reranking-datasets-light
收藏Hugging Face2024-12-30 更新2024-12-31 收录
下载链接:
https://huggingface.co/datasets/abdoelsayed/reranking-datasets-light
下载链接
链接失效反馈官方服务:
资源简介:
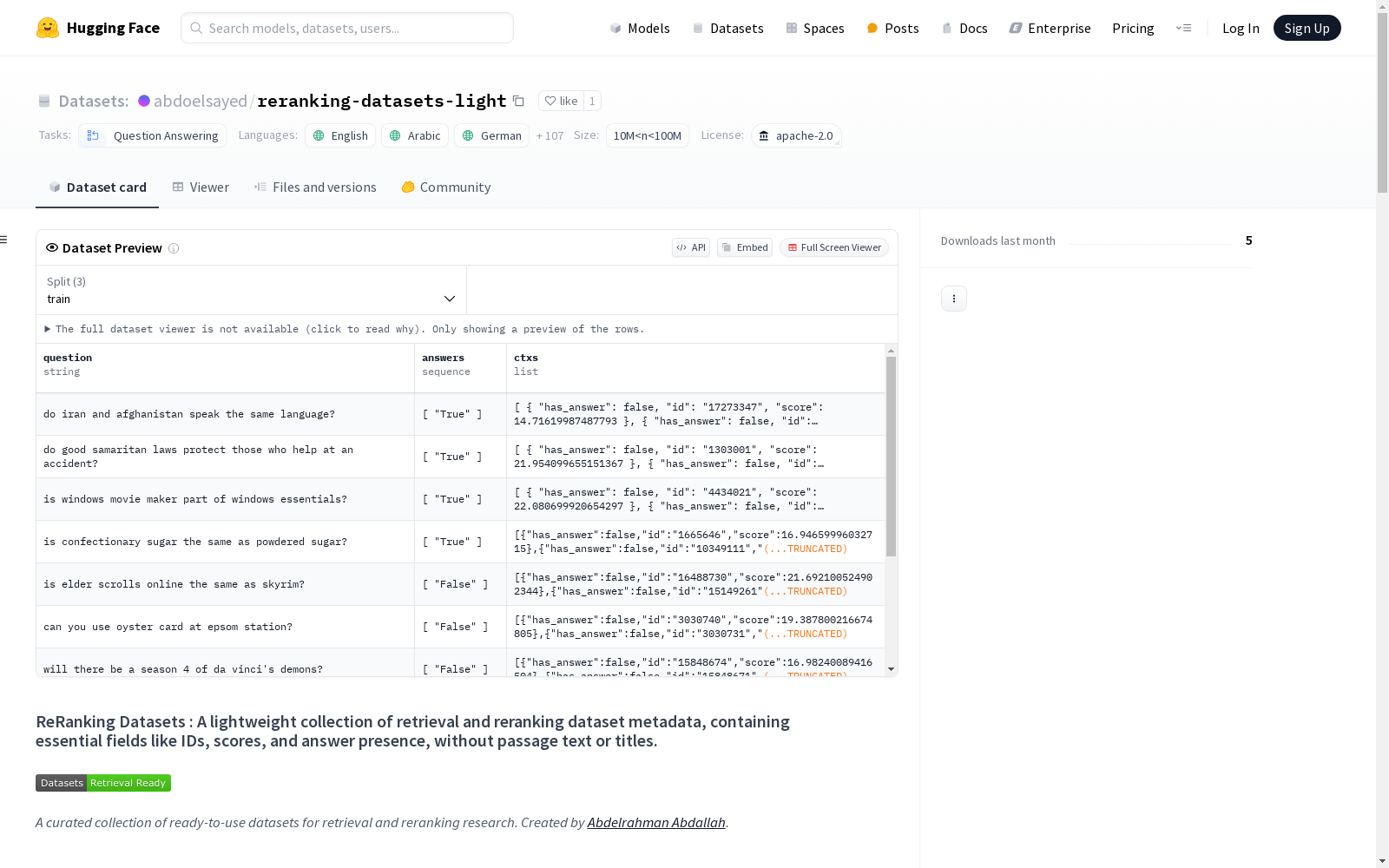
ReRanking Datasets是一个轻量级的检索和重排序数据集元数据集合,包含了ID、分数和答案存在等关键字段,但不包含段落文本或标题。该数据集旨在简化检索研究,提供预处理的常用检索器结果,包括Natural Questions (NQ)、TriviaQA、WebQuestions (WebQ)、SQuAD、EntityQuestions、ArchivialQA、ChroniclingAmericaQA和HotpotQA等数据集。每个数据集都有来自不同检索器的检索输出,如MSS、MSS-DPR、DPR、BM25、Contriever等。数据集以JSON格式提供,结构包括问题、答案和上下文信息。
ReRanking Datasets is a lightweight collection of retrieval and reranking dataset metadata, which encompasses core fields including ID, score, and answer existence, while excluding paragraph text or titles. This dataset is designed to streamline retrieval research by offering preprocessed results from widely used retrievers, covering datasets such as Natural Questions (NQ), TriviaQA, WebQuestions (WebQ), SQuAD, EntityQuestions, ArchivialQA, ChroniclingAmericaQA, and HotpotQA. Each dataset includes retrieval outputs from diverse retrievers, e.g., MSS, MSS-DPR, DPR, BM25, Contriever, and others. The datasets are distributed in JSON format, with a structure containing questions, answers, and context information.
创建时间:
2024-12-27
搜集汇总
数据集介绍
构建方式
reranking-datasets-light数据集的构建基于多个流行的问答数据集,包括Natural Questions、TriviaQA、WebQuestions等。通过整合不同检索器(如MSS、DPR、BM25等)的检索结果,数据集提供了预处理的检索输出,避免了用户自行运行检索器的繁琐步骤。数据以JSON格式组织,包含问题、答案列表以及检索到的上下文信息,如段落ID、检索分数和是否包含答案的标记。
特点
该数据集的特点在于其轻量级设计,仅包含检索和重排序任务所需的核心元数据,如ID、分数和答案存在性,而不包含段落文本或标题。这种设计使得数据集易于下载和使用,同时节省了存储空间。此外,数据集支持多种语言,覆盖了从英语到阿拉伯语、德语、法语等广泛的语言范围,适用于跨语言研究。
使用方法
使用reranking-datasets-light数据集时,用户可通过HuggingFace平台直接下载所需的文件。数据集以JSON格式提供,便于集成到检索或重排序的工作流中。用户可以使用HuggingFace的`load_dataset`函数加载数据,并通过流式处理模式高效地迭代数据。例如,加载BM25检索器在Natural Questions测试集上的结果,并处理前10条记录。
背景与挑战
背景概述
reranking-datasets-light数据集由Abdelrahman Abdallah创建,旨在为信息检索和重排序研究提供便捷的预处理数据集。该数据集涵盖了多个流行的问答数据集,如Natural Questions、TriviaQA、WebQuestions等,并提供了多种检索器的预计算结果,包括MSS、DPR、BM25等。其核心研究问题在于如何高效地支持问答系统中的检索与重排序任务,减少研究人员在数据预处理和检索器运行上的时间消耗。该数据集的推出为信息检索领域的研究者提供了一个标准化的基准,极大地推动了相关领域的研究进展。
当前挑战
reranking-datasets-light数据集在解决问答系统检索与重排序任务时面临多重挑战。首先,不同检索器的性能差异显著,如何选择最优的检索器并确保其在不同数据集上的泛化能力是一个关键问题。其次,数据集的构建过程中需要处理海量的文本数据,确保数据的准确性和一致性,尤其是在多语言环境下,语言多样性和数据质量的控制尤为复杂。此外,随着新型检索器的不断涌现,如何及时更新数据集以涵盖最新的检索技术,也是该数据集持续面临的挑战。
常用场景
经典使用场景
在信息检索和问答系统领域,reranking-datasets-light数据集为研究者提供了一个轻量级的工具,用于评估和比较不同检索模型在多种语言和数据集上的表现。该数据集包含了如Natural Questions、TriviaQA等知名问答数据集,并提供了多种检索器的预计算结果,使得研究者能够直接进行重排序任务,而无需从头开始运行检索过程。
实际应用
在实际应用中,reranking-datasets-light数据集被广泛应用于搜索引擎、智能助手和在线问答平台中。通过使用该数据集,开发者能够快速集成和测试不同的检索和重排序算法,从而提升系统的响应速度和准确性,改善用户体验。
衍生相关工作
基于reranking-datasets-light数据集,研究者们已经开发了多种先进的检索和重排序模型,如ColBERT和ANCE等。这些模型在多个基准测试中表现出色,进一步推动了信息检索技术的发展。此外,该数据集还激发了跨语言检索和多模态检索等新兴研究方向。
以上内容由遇见数据集搜集并总结生成


