shanchen/OncQA
收藏Hugging Face2023-12-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/shanchen/OncQA
下载链接
链接失效反馈官方服务:
资源简介:
OncQA数据集旨在研究使用AI聊天机器人(GPT-4)来起草对患者询问的回复的可接受性、安全性和潜在人为因素问题。数据集包含100个合成的癌症患者情景和患者消息,分为两个阶段:第一阶段是手动回复,第二阶段是AI辅助回复。数据集还包括医生对AI生成回复的编辑和调查反馈。研究结果表明,AI生成的回复虽然更长且可读性较低,但总体上安全且提高了效率。
提供机构:
shanchen
原始信息汇总
OncQA: 使用AI聊天机器人回应患者消息的影响
重要性
文档负担是导致临床医生倦怠的主要因素之一,AI聊天机器人通过协助文档记录显示出减轻这一负担的潜力,但其对临床决策的影响仍需深入研究。
目标
研究使用AI驱动的聊天机器人草拟患者询问回复时的可接受性、安全性和潜在的人为因素问题。
设计
- 设计了一个两阶段的横断面研究,围绕100个合成癌症患者场景和患者消息。
- 问题模拟真实的肿瘤学场景。
- 阶段1:手动回复:六名肿瘤学家随机分配26个问题进行回复。
- 阶段2:AI辅助回复:相同的肿瘤学家收到26个新问题,以及GPT-4生成的回复进行编辑。
- 获得知情同意。
- 参与者对草稿的来源不知情。
- 每个场景/回复都进行了调查。
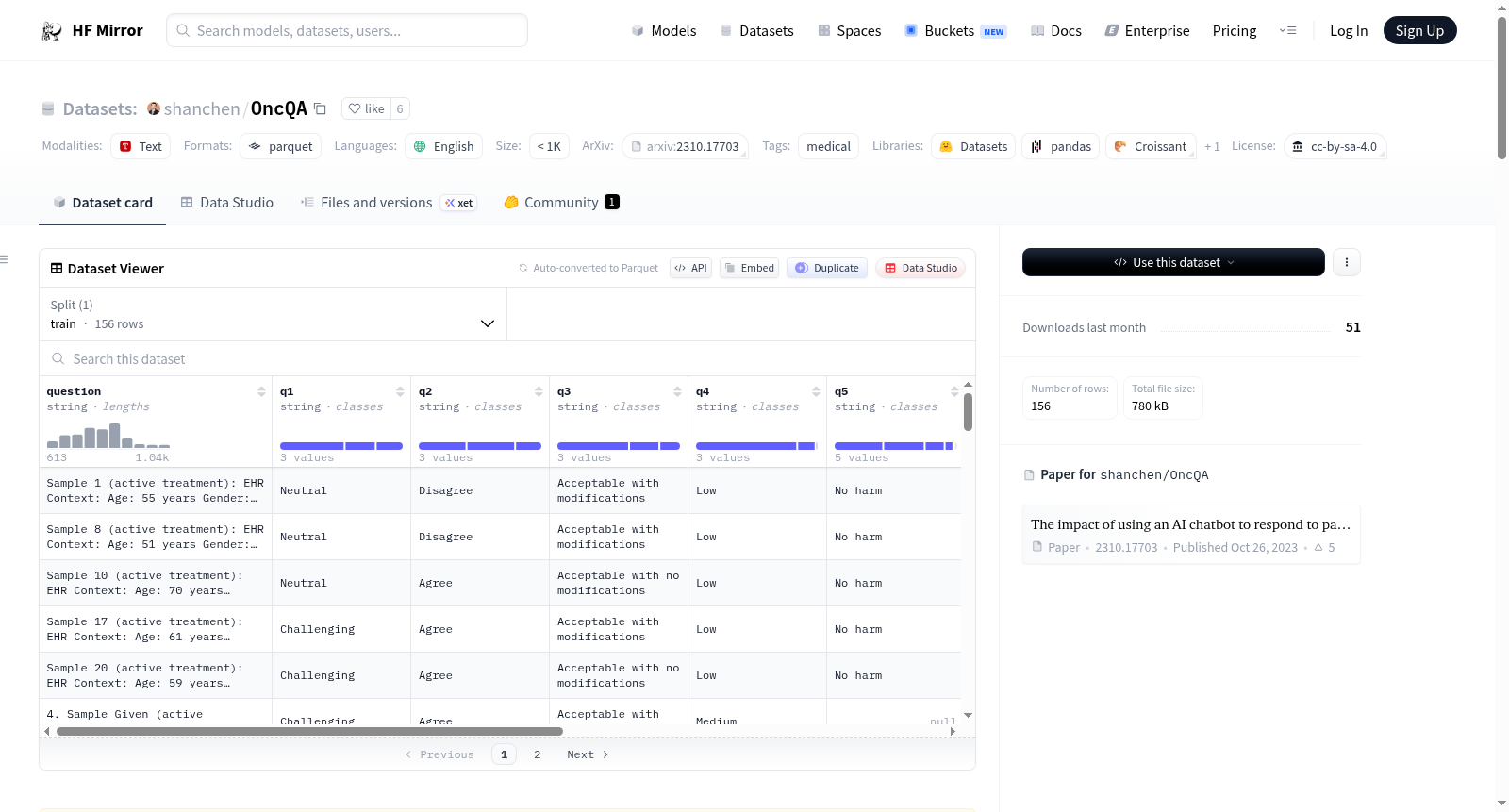
数据集描述
该数据集展示了完整的阶段2解析数据,包含所有医生的编辑。
设置
该研究于2023年在波士顿的布里格姆妇女医院进行。
参与者
六名获得认证的肿瘤学家参与了研究。
干预
使用GPT-4,一个AI聊天机器人,草拟患者询问的回复。
主要结果与测量
- 评估AI聊天机器人在协助回复患者消息中的影响和实用性。
- 通过比较回复长度和可读性(使用Flesch阅读易度分数)以及内容来确定影响。
- 通过医生对调查的反馈来确定实用性,包括可接受性、潜在伤害和聊天机器人草拟稿的效率。
结果
- 平均而言,手动回复比GPT-4或AI辅助回复更简洁(34 vs. 169 vs. 160字,p<0.001)。
- 手动回复比GPT-4或AI辅助消息更易读(Flesch分数67 vs. 45 vs. 46,p<0.001)。
- 约58%的GPT-4草稿立即被接受,82%的草稿造成低风险伤害。
- 使用GPT-4草稿提高了77%回复的文档效率。
- 令人惊讶的是,31%的GPT-4回复被认为是人类撰写的,尽管它们是AI生成的。
- 7.7%的调查回复认为未经编辑的GPT-4草稿可能导致严重伤害或死亡。
- 在56个双重注释的回复中,手动回复的注释一致性较低(Cohens kappa 0.10),但AI辅助回复的注释一致性提高(Cohens kappa 0.52)。
- AI辅助导致回复中的临床内容差异(p=0.001)。
- 手动回复更可能建议直接临床行动,而GPT-4草稿通常提供教育和自我管理建议。
- AI辅助回复接近GPT-4草稿,但引入了一些直接临床行动。
结论与相关性
AI生成的聊天机器人回复虽然较长且不易读,但总体上是安全的并提高了效率。AI辅助改变了医生反馈的性质并减少了变异性。AI聊天机器人是解决医生倦怠的有前景的方法,并可能改善患者护理,但人类与AI的互动可能以意想不到的方式影响临床决策。解决这些互动对于安全地整合此类技术至关重要。
搜集汇总
数据集介绍
构建方式
在医学信息学领域,OncQA数据集的构建遵循严谨的交叉研究设计。该研究模拟了100个合成癌症患者场景及相应咨询信息,以贴近真实肿瘤学情境。构建过程分为两个阶段:第一阶段由六位肿瘤学家独立撰写回复;第二阶段则引入GPT-4生成初始草稿,供同一批专家进行编辑修订。所有参与者均不知晓草稿来源,且每个场景均辅以标准化问卷调查,确保了数据采集的科学性与可控性。
特点
OncQA数据集的核心特点在于其聚焦于人工智能辅助临床决策的交互影响。数据不仅包含医师手动撰写与AI辅助修订的双版本回复,还整合了多维度的医师评估指标,如回复可接受性、潜在伤害风险及效率提升感知等。尤为突出的是,数据集揭示了AI生成内容与人工回复在长度、可读性及临床建议倾向上的系统性差异,为探究人机协作对医疗文本生成的影响提供了细致对比。
使用方法
该数据集适用于自然语言处理与医学信息学交叉研究,特别是对话生成与文本修订任务。使用者可基于阶段二的解析数据,分析AI草稿与医师修订版之间的文本差异,或利用附带的调查数据评估AI在临床场景中的接受度与安全性。数据亦支持对回复风格、临床内容变更及注释一致性等进行量化研究,为开发更安全、高效的医疗辅助工具提供实证基础。
背景与挑战
背景概述
在医疗信息化浪潮中,临床文档负担日益成为导致医生职业倦怠的关键因素,严重威胁医疗服务的可持续性。为此,OncQA数据集应运而生,由哈佛大学附属布莱根妇女医院的研究团队于2023年创建,旨在深入探究人工智能聊天机器人在辅助肿瘤科医生回复患者咨询时的可接受性、安全性及其潜在的人类因素影响。该数据集围绕100个模拟真实肿瘤学场景的合成患者案例构建,通过两阶段横断面研究设计,比较了人工回复与GPT-4辅助回复在内容、可读性及临床决策方面的差异,为评估AI在减轻临床文档负担、优化医患沟通方面的应用潜力提供了实证基础,对推动医疗人工智能的负责任部署具有重要参考价值。
当前挑战
OncQA数据集致力于应对医疗对话生成领域的核心挑战,即如何在确保临床安全性与决策准确性的前提下,有效利用AI技术提升医患沟通效率。具体而言,数据集构建面临多重挑战:在领域问题层面,需精准模拟真实肿瘤学场景,平衡合成数据的逼真度与伦理边界,同时评估AI生成回复的潜在医疗风险,如7.7%的未编辑草案可能引发严重伤害或死亡的风险警示;在构建过程中,研究团队需设计双盲实验以消除偏见,协调六位肿瘤科医生进行跨阶段标注,并处理人工与AI回复在内容长度、可读性及临床建议导向上的显著差异,例如AI草案倾向于提供教育性建议,而人工回复更注重直接临床行动,这种差异可能导致临床决策的意外偏移,凸显了人机交互复杂性带来的挑战。
常用场景
经典使用场景
在医疗信息学领域,OncQA数据集为探索人工智能在临床沟通中的应用提供了关键资源。该数据集通过模拟真实的癌症患者咨询场景,记录了肿瘤科医生在人工和AI辅助下对患者消息的回复过程,特别聚焦于评估AI生成草稿的可接受性、安全性及效率。其经典使用场景包括训练和验证自然语言处理模型,以优化医疗对话系统,支持医生更高效地处理患者咨询,同时减少文档负担。
解决学术问题
OncQA数据集直接应对了临床决策中人工智能交互的学术研究空白。它通过实证分析,解决了AI聊天机器人如何影响医生回复内容、临床行动建议以及沟通变异性等问题。该数据集的意义在于揭示了AI辅助虽能提升效率,但可能改变反馈性质,为安全整合AI技术提供了数据基础,推动了医疗人机交互领域的深入探索。
衍生相关工作
基于OncQA数据集,衍生了一系列经典研究工作,主要集中在医疗AI的伦理与安全评估。例如,研究团队进一步探讨了AI生成回复的临床影响和人类感知偏差,推动了相关模型在可解释性和适应性方面的改进。这些工作扩展了数据集在医疗对话生成、风险预测以及人机协作优化等方向的应用。
以上内容由遇见数据集搜集并总结生成


