ViRL39K
收藏魔搭社区2026-05-16 更新2025-04-26 收录
下载链接:
https://modelscope.cn/datasets/TIGER-Lab/ViRL39K
下载链接
链接失效反馈官方服务:
资源简介:
# 1. Overview of ViRL39K
**ViRL39K** (pronounced as "viral") provides a curated collection of 38,870 verifiable QAs for **Vi**sion-Language **RL** training.
It is built on top of newly collected problems and existing datasets (
[Llava-OneVision](https://huggingface.co/datasets/lmms-lab/LLaVA-OneVision-Data),
[R1-OneVision](https://huggingface.co/datasets/Fancy-MLLM/R1-Onevision),
[MM-Eureka](https://huggingface.co/datasets/FanqingM/MMK12),
[MM-Math](https://huggingface.co/datasets/THU-KEG/MM_Math),
[M3CoT](https://huggingface.co/datasets/LightChen2333/M3CoT),
[DeepScaleR](https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset),
[MV-Math](https://huggingface.co/datasets/PeijieWang/MV-MATH))
through cleaning, reformatting, rephrasing and verification.
**ViRL39K** lays the foundation for SoTA Vision-Language Reasoning Model [VL-Rethinker](https://tiger-ai-lab.github.io/VL-Rethinker/). It has the following merits:
- **high-quality** and **verifiable**: the QAs undergo rigorous filtering and quality control, removing problematic queries or ones that cannot be verified by rules.
- covering **comprehensive** topics and categories: from grade school problems to broader STEM and Social topics; reasoning with charts, diagrams, tables, documents, spatial relationships, etc.
- with fine-grained **model-capability annotations**: it tells you what queries to use when training models at different scales.
Explore more about **VL-Rethinker**:
- [**Project Page**](https://tiger-ai-lab.github.io/VL-Rethinker/)
- [**Github**](https://github.com/TIGER-AI-Lab/VL-Rethinker)
- [**Paper**](https://arxiv.org/abs/2504.08837)
- [**Models**](https://huggingface.co/collections/TIGER-Lab/vl-rethinker-67fdc54de07c90e9c6c69d09)
# 2. Dataset Statistics
## 2.1 **ViRL39K** covers **eight** major categories:
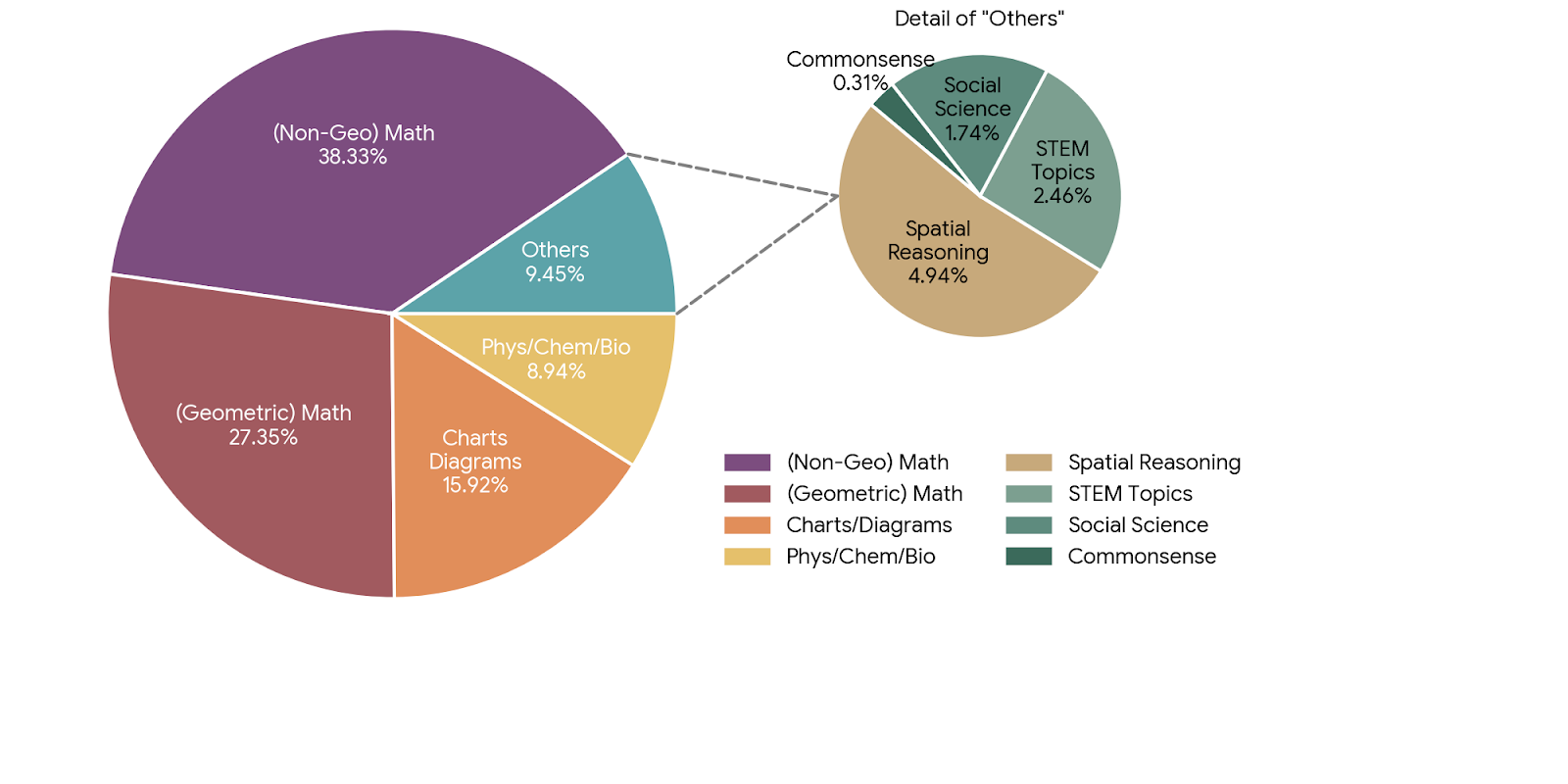
## 2.2 **ViRL39K** covers different difficulty levels for different model scales.

We associate each query with a PassRate annotation that reflects **model-capability** affinity.
You can use this annotation to select the proper queries to train models at different scales.
# 3. Dataset Keys
- answer: all answers are with \\boxed{}.
For answer extractions, we recommend using the `math-verify` library.
It can handle partial match where the answer has text in it, such as : `predicted = \\boxed{17}, answer = \\boxed{17^\circ}`.
You can refer to our [**Github**](https://github.com/TIGER-AI-Lab/VL-Rethinker) for reference of extraction and matching functions.
- PassRate:
we provide all PassRate for 32BTrained, <u>but provide only partial PassRate for 7BUntrained</u>, to save compute.
Specifically, we only label PassRate on 7BUntrained with 50\% queries in the dataset. These selected queries are easy for 32BTrained, which has `PassRate==1.0`.
The remaining queries are somewhat challenging for 32BTrained (`PassRate<1.0`), so we assume they will also be challenging for 7BUntrained.
**Note**: For 7BUntrained PassRate annotations, if they are not tested because `PassRate_32BTrained<1.0`, they are labeled `PassRate_7BUntrained=-1.0`.
- Category:
you can choose queries of interest based on the category.
## Citation
If you find ViRL39K useful, please give us a free cit:
```bibtex
@article{vl-rethinker,
title={VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning},
author = {Wang, Haozhe and Qu, Chao and Huang, Zuming and Chu, Wei and Lin,Fangzhen and Chen, Wenhu},
journal={arXiv preprint arXiv:2504.08837},
year={2025}
}
```
# 1. ViRL39K 概览
**ViRL39K**(发音为“viral”)是一套经过精心整理的数据集,包含38,870条可验证的问答对,用于**视觉语言强化学习(Vision-Language RL,VLRL)**训练。该数据集基于新收集的问题与现有公开数据集([Llava-OneVision](https://huggingface.co/datasets/lmms-lab/LLaVA-OneVision-Data)、[R1-OneVision](https://huggingface.co/datasets/Fancy-MLLM/R1-Onevision)、[MM-Eureka](https://huggingface.co/datasets/FanqingM/MMK12)、[MM-Math](https://huggingface.co/datasets/THU-KEG/MM_Math)、[M3CoT](https://huggingface.co/datasets/LightChen2333/M3CoT)、[DeepScaleR](https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset)、[MV-Math](https://huggingface.co/datasets/PeijieWang/MV-MATH))构建,经过清洗、格式重构、表述优化与验证流程生成。
**ViRL39K** 为当前顶尖(State-of-the-Art,SoTA)视觉语言推理模型 [VL-Rethinker](https://tiger-ai-lab.github.io/VL-Rethinker/) 奠定了核心数据基础。其具备以下优势:
- **高质量且可验证**:所有问答对均经过严格筛选与质量管控,剔除了存在问题或无法通过规则验证的查询内容。
- **覆盖全面的主题与类别**:涵盖从小学阶段习题到广泛的STEM(科学、技术、工程、数学)及社会科学主题;支持图表、示意图、表格、文档、空间关系等多模态推理场景。
- **细粒度的模型能力标注**:标注信息可指导针对不同模型规模选择适配的训练查询。
如需了解更多关于 **VL-Rethinker** 的信息,请访问:
- [**项目主页**](https://tiger-ai-lab.github.io/VL-Rethinker/)
- [**GitHub 仓库**](https://github.com/TIGER-AI-Lab/VL-Rethinker)
- [**论文**](https://arxiv.org/abs/2504.08837)
- [**模型权重**](https://huggingface.co/collections/TIGER-Lab/vl-rethinker-67fdc54de07c90e9c6c69d09)
# 2. 数据集统计信息
## 2.1 **ViRL39K** 覆盖**8大**主要类别:

## 2.2 **ViRL39K** 针对不同模型规模覆盖了不同难度层级的查询。

我们为每个查询添加了反映模型能力亲和性的**通过率(PassRate)**标注。您可通过该标注为不同规模的模型选择适配的训练查询。
# 3. 数据集字段说明
- `answer`:所有答案均采用 `oxed{}` 格式包裹。
针对答案提取任务,我们推荐使用 `math-verify` 工具库。该库可处理答案中包含文本的部分匹配场景,例如:`predicted = oxed{17}, answer = oxed{17^circ}`。
您可参考我们的 [**GitHub 仓库**](https://github.com/TIGER-AI-Lab/VL-Rethinker) 中的提取与匹配函数示例。
- `PassRate`:
我们为32B预训练模型(32BTrained)提供了全部查询的通过率标注,但为节省计算资源,仅为7B未预训练模型(7BUntrained)提供了部分查询的通过率标注。
具体而言,我们仅对数据集中50%的查询进行了7BUntrained的通过率标注:这些查询对于32BTrained模型而言属于简单样本,其`PassRate==1.0`。
剩余查询对于32BTrained模型具有一定挑战性(`PassRate<1.0`),因此我们假设它们同样难以被7BUntrained模型解决。
**注意**:对于7BUntrained模型的通过率标注,如果因`PassRate_32BTrained<1.0`而未进行测试,则将其`PassRate_7BUntrained`标注为`-1.0`。
- `Category`:您可根据类别标签选择感兴趣的查询样本。
## 引用声明
如果您认为ViRL39K对您的研究有所帮助,请引用我们的工作:
bibtex
@article{vl-rethinker,
title={VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning},
author = {Wang, Haozhe and Qu, Chao and Huang, Zuming and Chu, Wei and Lin,Fangzhen and Chen, Wenhu},
journal={arXiv preprint arXiv:2504.08837},
year={2025}
}
提供机构:
maas
创建时间:
2025-04-22


