egoqa
收藏Hugging Face2024-10-05 更新2024-12-12 收录
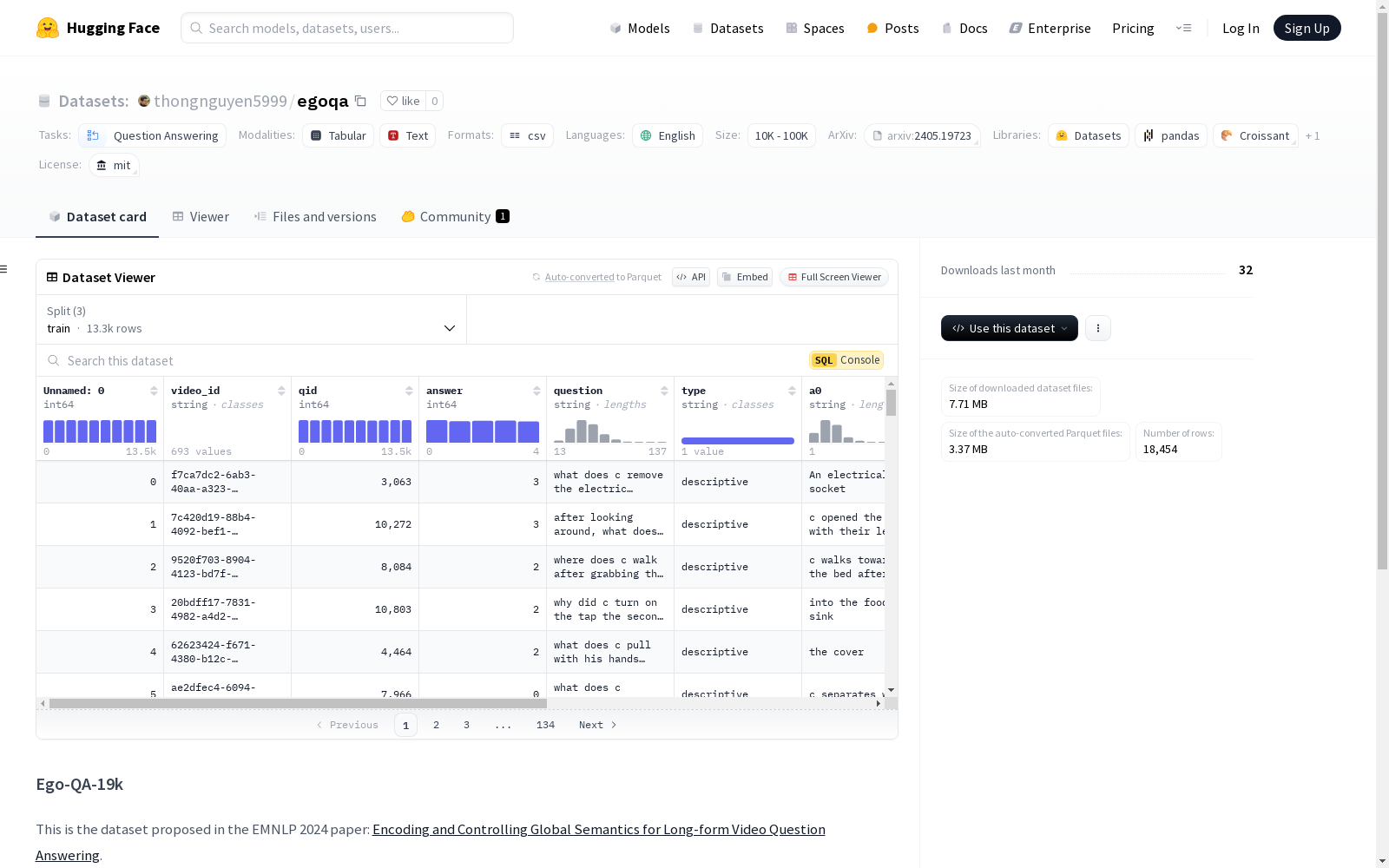
下载链接:
https://huggingface.co/datasets/thongnguyen5999/egoqa
下载链接
链接失效反馈官方服务:
资源简介:
Ego-QA-19k数据集包含19k个视频问答数据,领域为第一人称视角场景。数据集的创建分为两个阶段:首先,通过将视频字幕按时间顺序拼接生成视频描述,然后利用GPT-4为每个视频生成20个问题;其次,过滤掉包含特定线索词的问题,并由母语为英语的研究生确保问题的真实性和回答问题所需的视频长度。
The Ego-QA-19k dataset consists of 19,000 video-based question answering (QA) samples, with its domain focusing on first-person perspective scenarios. The dataset construction is divided into two stages: Firstly, video descriptions are generated by concatenating video subtitles in chronological order, and then 20 questions are generated for each video using GPT-4. Secondly, questions containing specific cue words are filtered out, and native English-speaking graduate students are invited to verify the authenticity of the questions and the video length required for answering each question.
创建时间:
2024-10-05
原始信息汇总
Ego-QA-19k
概述
- 数据集名称: Ego-QA-19k
- 数据集来源: EMNLP 2024 论文 Encoding and Controlling Global Semantics for Long-form Video Question Answering
- 任务类别: 问答
- 语言: 英语
- 数据规模: 10K<n<100K
- 许可证: MIT
数据集描述
- 领域: 以自我为中心的场景
- 数据生成过程:
- 问题-答案生成: 对于每个视频,按时间顺序拼接视频字幕以构建视频描述,然后使用GPT-4生成每个视频的20个问题。
- 数据过滤: 过滤包含线索词(如“passage”、“text”、“description”)的问题,并由母语为英语的研究生确保问题的真实性和回答问题所需的视频长度。
使用方法
搜集汇总
数据集介绍
构建方式
Ego-QA-19k数据集的构建过程分为两个主要阶段。首先,通过将视频的字幕按时间顺序拼接生成视频描述,随后利用GPT-4为每个视频生成20个问题。其次,通过过滤包含特定关键词的问题,并邀请母语为英语的研究生对问题的真实性和所需观看的视频长度进行验证,确保数据的质量。
特点
Ego-QA-19k数据集专注于以自我为中心的场景,包含19,000个视频问答对。该数据集的特点在于其问题生成过程依赖于先进的自然语言处理模型GPT-4,确保了问题的多样性和复杂性。此外,通过人工筛选和验证,数据集的质量得到了进一步提升,适用于长视频问答任务的研究。
使用方法
Ego-QA-19k数据集的使用方法较为直观。用户可以通过HuggingFace平台访问数据文件,并结合相关论文和GitHub代码进行深入研究。数据集适用于视频问答任务的研究,特别是长视频场景下的问答系统开发。通过参考提供的论文和代码,用户可以更好地理解数据集的构建逻辑和应用场景。
背景与挑战
背景概述
Ego-QA-19k数据集由EMNLP 2024论文《Encoding and Controlling Global Semantics for Long-form Video Question Answering》提出,专注于以自我为中心场景的长视频问答任务。该数据集由19,000个视频问答对组成,旨在通过视频描述生成问题并利用GPT-4进行问答对生成。数据集的构建分为两个阶段:首先通过按时间顺序拼接视频字幕生成视频描述,随后利用GPT-4为每个视频生成20个问题;其次通过人工筛选确保问题的真实性和相关性。该数据集的发布为长视频问答领域提供了重要的研究资源,推动了视频语义理解与问答技术的发展。
当前挑战
Ego-QA-19k数据集在构建过程中面临多重挑战。首先,长视频问答任务本身具有复杂性,需要模型理解视频的全局语义并生成高质量的问题。其次,数据生成阶段依赖GPT-4生成问题,可能引入偏差或与视频内容不完全匹配的问题,需通过人工筛选进行修正。此外,数据集的规模较大,确保每个问答对的准确性和一致性需要耗费大量人力成本。最后,视频数据的多样性和复杂性对模型的泛化能力提出了更高要求,如何在长视频中捕捉关键信息并生成精准答案仍是一个亟待解决的难题。
常用场景
经典使用场景
Ego-QA-19k数据集主要用于长视频问答任务,特别是在以自我为中心的视觉场景中。该数据集通过结合视频描述和GPT-4生成的问题,为研究者提供了一个丰富的资源,用于训练和评估视频问答模型。其经典使用场景包括视频内容理解、时间序列分析以及多模态学习,尤其是在需要从长视频中提取关键信息并回答复杂问题的场景中表现出色。
解决学术问题
Ego-QA-19k数据集解决了长视频问答领域中的多个关键学术问题。首先,它通过生成高质量的问题-答案对,填补了长视频问答数据稀缺的空白。其次,该数据集通过过滤机制确保了问题的真实性和可回答性,为模型训练提供了可靠的基础。此外,其以自我为中心的视觉场景为研究全局语义编码和控制提供了独特的研究视角,推动了多模态学习领域的发展。
衍生相关工作
Ego-QA-19k数据集自发布以来,已衍生出多项经典研究工作。例如,基于该数据集的全局语义编码方法在长视频问答任务中取得了显著进展。此外,研究者们还利用该数据集开发了多种多模态融合模型,进一步提升了视频问答系统的性能。这些工作不仅验证了数据集的实用性,也为未来的研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


