starcoder2-documentation
收藏数据集概述
数据集详情
概览
该数据集包含从各种包管理平台和编程语言文档站点爬取的文档和代码相关资源的全面集合。它专注于流行的库、免费编程书籍和其他相关材料,便于软件开发、编程语言趋势和文档分析的研究。
数据字段
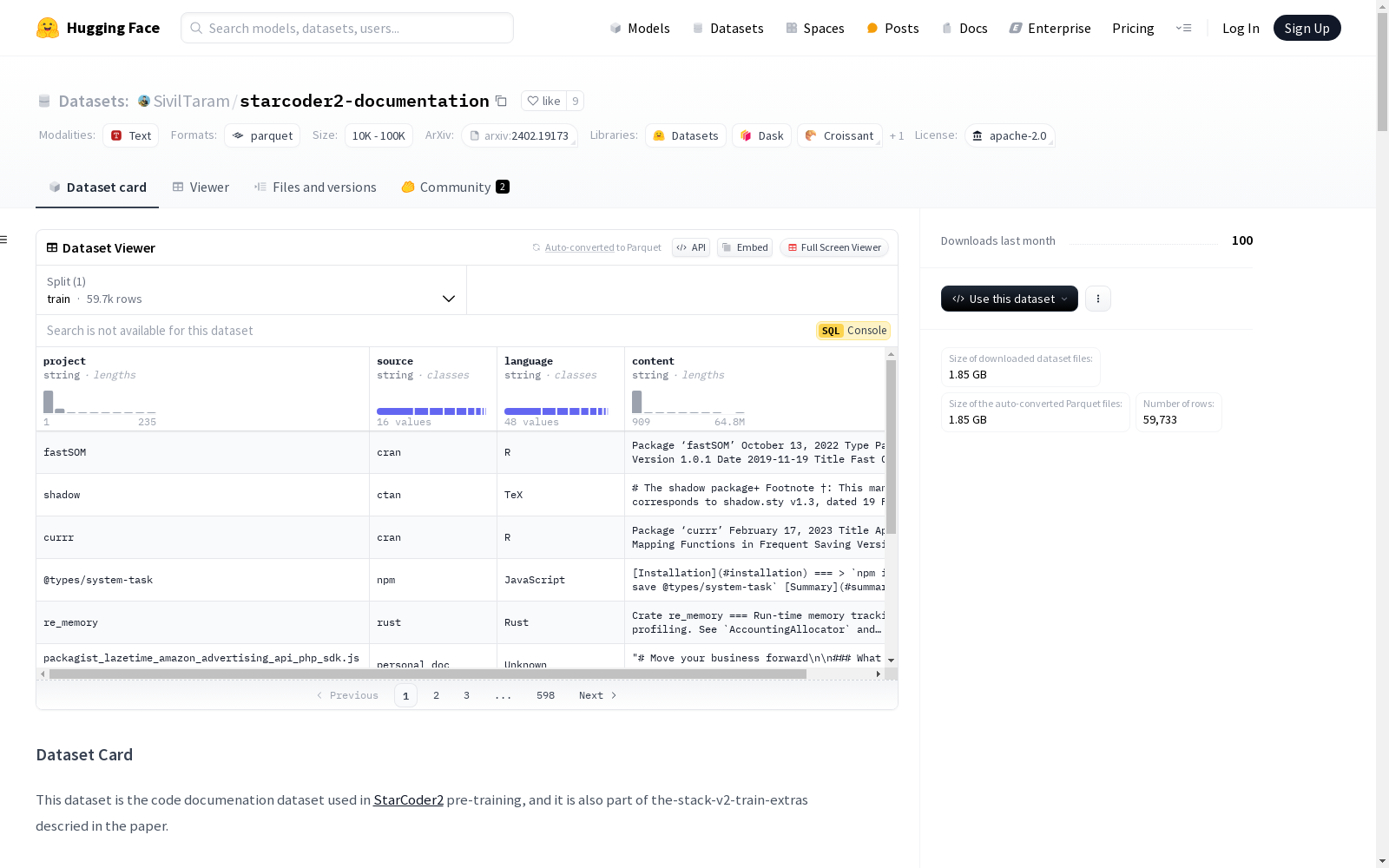
project(string): 每个平台上的项目名称或标识符。source(string): 文档数据来源的平台。language(string): 与项目相关的编程语言。content(string): 每个文档的文本内容,以Markdown格式编排。
数据来源
-
包管理器:
- npm: Node.js包管理器。
- PyPI: Python包索引。
- Go Packages: Go编程语言包。
- Packagist: PHP包仓库。
- Rubygems: Ruby包管理器。
- Cargo: Rust包管理器。
- CocoaPods: Swift和Objective-C Cocoa项目的依赖管理器。
- Bower: 前端包管理器。
- CPAN: 综合Perl存档网络。
- Clojars: Clojure库仓库。
- Conda: 数据科学和科学计算的包管理器。
- Hex: Elixir编程语言的包管理器。
- Julia: Julia编程语言的包管理器。
-
文档网站:
- 精心挑选的编程相关网站列表,包括Read the Docs和其他知名资源。
-
免费编程书籍:
- 来自Free Programming Books项目的资源,推广各种语言的免费编程电子书。
数据收集过程
-
库检索:
- 使用libraries.io识别上述平台中最流行的库,并将其作为搜索查询以获取相应的主页。
-
文档提取:
- 主页链接: 从检索到的主页链接爬取文档文件。如果没有找到专门的文档,则使用包管理平台上的README或等效文件。
- 处理策略: 对于通过主页链接获得的文档,采用与网站爬取相同的处理策略,确保一致的格式和提取质量。
- 优先级: 对于托管在PyPI和Conda上的库,优先考虑Read the Docs上的文档。
-
PDF提取:
- 对于R语言文档,使用pdftotext库从CRAN上托管的所有PDF中提取文本,有效保留格式。
- 对于LaTeX包,从CTAN过滤文档、教程和使用指南PDF,排除图像密集型PDF,并使用Nougat神经OCR工具转换为Markdown。
-
网络爬取:
- 从精心挑选的网站列表中收集代码文档,通过初始URL进行探索,完整URL列表可在StarCoder2论文中找到。
- 使用动态队列存储同一域内的URL,随着爬取过程中新链接的发现而扩展。
- 过程聚焦于(1)内容提取和(2)内容拼接:
- 内容提取: 使用trafilatura库将HTML页面转换为XML,消除冗余导航元素。
- 内容拼接: 对不同HTML页面提取的内容进行近似重复检查,使用minhash局部敏感哈希技术,应用0.7的阈值以确保保留唯一内容。
-
免费教科书:
- 数据集包括从Free Programming Books Project收集的免费编程书籍。提取带有PDF扩展的链接,并下载所有可用的PDF,使用pdf2text库进行文本提取。
-
语言识别:
- 采用双重方法识别每个文档的主要编程语言:
- 预定义规则: 当文档来源明确对应特定编程语言时应用。
- Guesslang库: 在对应关系不明确时使用。
- 采用双重方法识别每个文档的主要编程语言:
数据集特征
- 涵盖语言: 英语、中文、日语、西班牙语等。
- 文档类型:
- 代码文档文件
- PDF文档
- HTML页面
- 电子书
- 包含编程语言:
- Python
- JavaScript
- Rust
- R
- Go
- PHP
- Ruby
- Haskell
- Objective-C
- SQL
- YAML
- TeX
- Markdown
- 及其他...
使用案例
- 分析编程语言文档的趋势。
- 研究跨多个平台的软件开发资源。
- 在文档数据集上训练大型语言模型,以更好地理解编程语言。
- 理解编程文档的结构和可访问性。
引用
bibtex @article{DBLP:journals/corr/abs-2402-19173, author = {Anton Lozhkov and Raymond Li and Loubna Ben Allal and Federico Cassano and Joel Lamy{-}Poirier and Nouamane Tazi and Ao Tang and Dmytro Pykhtar and Jiawei Liu and Yuxiang Wei and Tianyang Liu and Max Tian and Denis Kocetkov and Arthur Zucker and Younes Belkada and Zijian Wang and Qian Liu and Dmitry Abulkhanov and Indraneil Paul and Zhuang Li and Wen{-}Ding Li and Megan Risdal and Jia Li and Jian Zhu and Terry Yue Zhuo and Evgenii Zheltonozhskii and Nii Osae Osae Dade and Wenhao Yu and Lucas Krau{ss} and Naman Jain and Yixuan Su and Xuanli He and Manan Dey and Edoardo Abati and Yekun Chai and Niklas Muennighoff and Xiangru Tang and Muhtasham Oblokulov and Christopher Akiki and Marc Marone and Chenghao Mou and Mayank Mishra and Alex Gu and Binyuan Hui and Tri Dao and Armel Zebaze and Olivier Dehaene and Nicolas Patry and Canwen Xu and Julian J. McAuley and Han Hu and Torsten Scholak and S{{e}}bastien Paquet and Jennifer Robinson and Carolyn Jane Anderson and Nicolas Chapados and et al.}, title = {StarCoder 2 and The Stack v2: The Next Generation}, journal = {CoRR}, volume = {abs/2402.19173}, year = {2024}, url = {https://doi.org/10.48550/arXiv.2402.19173}, doi = {10.48550/ARXIV.2402.19173}, eprinttype = {arXiv}, eprint = {2402.19173}, timestamp = {Tue, 06 Aug 2024 08:17:53 +0200}, biburl = {https://dblp.org/rec/journals/corr/abs-2402-19173.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }