french_first_names_insee_2024
收藏Hugging Face2024-11-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/eltorio/french_first_names_insee_2024
下载链接
链接失效反馈官方服务:
资源简介:
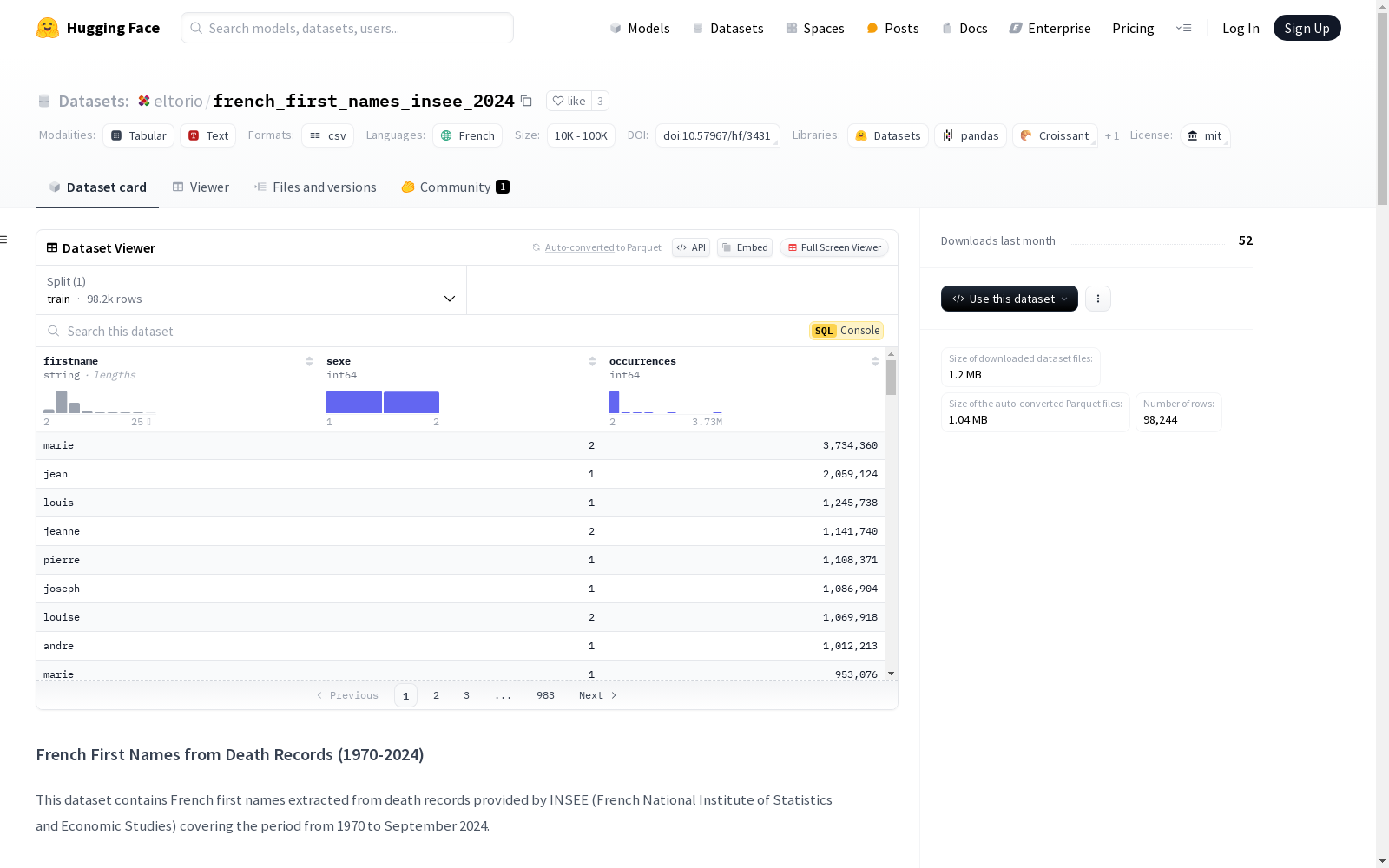
该数据集包含从INSEE(法国国家统计和经济研究所)提供的死亡记录中提取的法国名字,涵盖1970年至2024年9月的时间段。数据集包含三个特征列:'firstname'(死者的名字)、'sexe'(性别指示符,1表示男性,2表示女性)和'occurrences'(记录中名字的出现次数)。数据经过过滤处理,只包括长度大于1个字符、不重复单个字符且至少出现两次的名字。数据集可用于历史分析、人口研究、性别分类、文化演变研究和家谱研究等多种用途。
创建时间:
2024-11-03
原始信息汇总
French First Names from Death Records (1970-2024)
数据集描述
数据来源
- 数据来源于INSEE(法国国家统计与经济研究所)的死亡记录数据库。
- 包含法国死亡记录中的名字,提供了不同代际命名模式的宝贵见解。
时间范围
- 开始时间:1970年
- 结束时间:2024年9月
特征
数据集包含以下三列:
firstname:死者的名字sexe:性别指示符(1 = 男性,2 = 女性)occurrences:记录中名字的出现次数
数据处理
数据经过以下过滤标准进行清洗:
- 名字长度大于1个字符
- 名字不是由重复的单个字符组成
- 仅包含至少出现2次的名字
数据格式
- 文件格式:CSV
- 编码:UTF-8
- 分隔符:逗号(,)
使用场景
该数据集可用于以下目的:
- 法国命名模式的历史分析
- 人口统计研究
- 法国名字的性别分类
- 文化演变研究
- 家谱研究
许可证
MIT许可证
引用
bibtex @dataset{french_first_names_insee_2024, author = {Ronan Le Meillat}, title = {French First Names from Death Records (1970-2024)}, year = {2024}, publisher = {Hugging Face}, source = {INSEE}, }
数据集创建
数据收集
数据从INSEE的死亡记录数据库中提取,该数据库维护法国所有死亡的官方记录。
预处理
- 从死亡记录中提取名字
- 过滤掉只有1个字符的名字
- 过滤掉由重复单个字符组成的名字
- 移除只出现一次的名字
- 性别编码(1为男性,2为女性)
- 统计每个名字的出现次数
数据集结构
python DatasetDict({ train: Dataset({ features: [firstname, sexe, occurrences], num_rows: 98244 }) })
附加信息
源数据
原始数据来自INSEE(法国国家统计与经济研究所)。
维护
该数据集是一个静态快照,反映截至2024年9月的死亡记录。
已知限制
- 数据集仅包含死亡记录中的名字,可能无法完全代表当代命名模式
- 历史记录可能存在拼写或记录不一致的情况
- 数据集仅包含至少出现2次的名字,可能排除一些罕见或独特的名字
致谢
感谢INSEE使这些数据公开可用。
搜集汇总
数据集介绍
构建方式
该数据集基于法国国家统计与经济研究所(INSEE)提供的1970年至2024年9月的死亡记录构建。数据提取过程包括从死亡记录中筛选出名字长度大于1字符且不包含重复单字符的名字,并仅保留出现次数至少为2次的名字。此外,性别信息被编码为1(男性)和2(女性),并对每个名字的出现次数进行了统计。数据以CSV格式存储,采用UTF-8编码,字段间以逗号分隔。
特点
该数据集包含三个主要特征:`firstname`(名字)、`sexe`(性别)和`occurrences`(出现次数)。名字来源于法国死亡记录,涵盖了1970年至2024年9月的命名数据。性别信息以数字编码形式呈现,便于性别分类研究。出现次数统计了每个名字在记录中的频率,为命名模式的历史分析和人口统计研究提供了丰富的数据支持。
使用方法
该数据集适用于多种研究场景,包括法国命名模式的历史分析、人口统计研究、性别分类以及文化演变研究等。用户可以通过Hugging Face的`datasets`库加载数据集,具体代码为`load_dataset('eltorio/french_first_names_insee_2024')`。数据集以CSV格式提供,便于直接导入到数据分析工具中进行进一步处理。
背景与挑战
背景概述
法国名字数据集(french_first_names_insee_2024)由法国国家统计与经济研究所(INSEE)提供的死亡记录数据构建而成,涵盖了1970年至2024年9月期间的法国人名信息。该数据集由Ronan Le Meillat于2024年发布,旨在为研究者提供关于法国命名模式的历史视角。通过分析这些数据,研究者可以深入探讨法国社会文化变迁、性别命名偏好以及人口统计学特征。该数据集不仅为历史学家和人口统计学家提供了宝贵资源,还为文化演变研究和家谱学研究提供了重要支持。
当前挑战
该数据集在构建过程中面临多重挑战。首先,数据来源仅限于死亡记录,可能导致对当代命名模式的代表性不足,尤其是在年轻一代中。其次,历史记录中可能存在拼写或记录不一致的问题,增加了数据清洗的难度。此外,数据集仅包含出现次数大于等于2的名字,这可能排除了一些罕见或独特的名字,影响了数据的全面性。在应用层面,尽管该数据集可用于性别分类和文化演变研究,但其静态特性限制了其在实时分析中的应用。这些挑战要求研究者在利用该数据集时,需谨慎考虑其局限性,并结合其他数据源进行综合分析。
常用场景
经典使用场景
在法国社会文化研究中,`french_first_names_insee_2024`数据集被广泛用于分析命名趋势的演变。通过对1970年至2024年间死亡记录中的名字进行统计,研究者能够追踪不同年代中法国人名的流行变化,揭示社会文化背景对命名习惯的影响。该数据集为历史学家、社会学家和人口统计学家提供了宝贵的数据支持,帮助他们深入理解法国社会的文化变迁。
实际应用
在实际应用中,`french_first_names_insee_2024`数据集为法国政府机构和研究机构提供了重要的参考依据。例如,该数据集可用于优化人口统计模型,帮助政府制定更精准的社会政策。同时,该数据集也为文化研究机构提供了丰富的数据资源,支持其对法国命名文化的深入分析和传播。
衍生相关工作
基于`french_first_names_insee_2024`数据集,许多经典研究工作得以展开。例如,研究者利用该数据集开发了法国名字性别分类模型,为自动化性别识别提供了技术支持。此外,该数据集还被用于构建法国命名文化演变的时间线,为相关领域的学术研究提供了重要的数据支撑和理论依据。
以上内容由遇见数据集搜集并总结生成


