ImageCaptioning_Catalan
收藏Hugging Face2024-10-19 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Marxx01/ImageCaptioning_Catalan
下载链接
链接失效反馈官方服务:
资源简介:
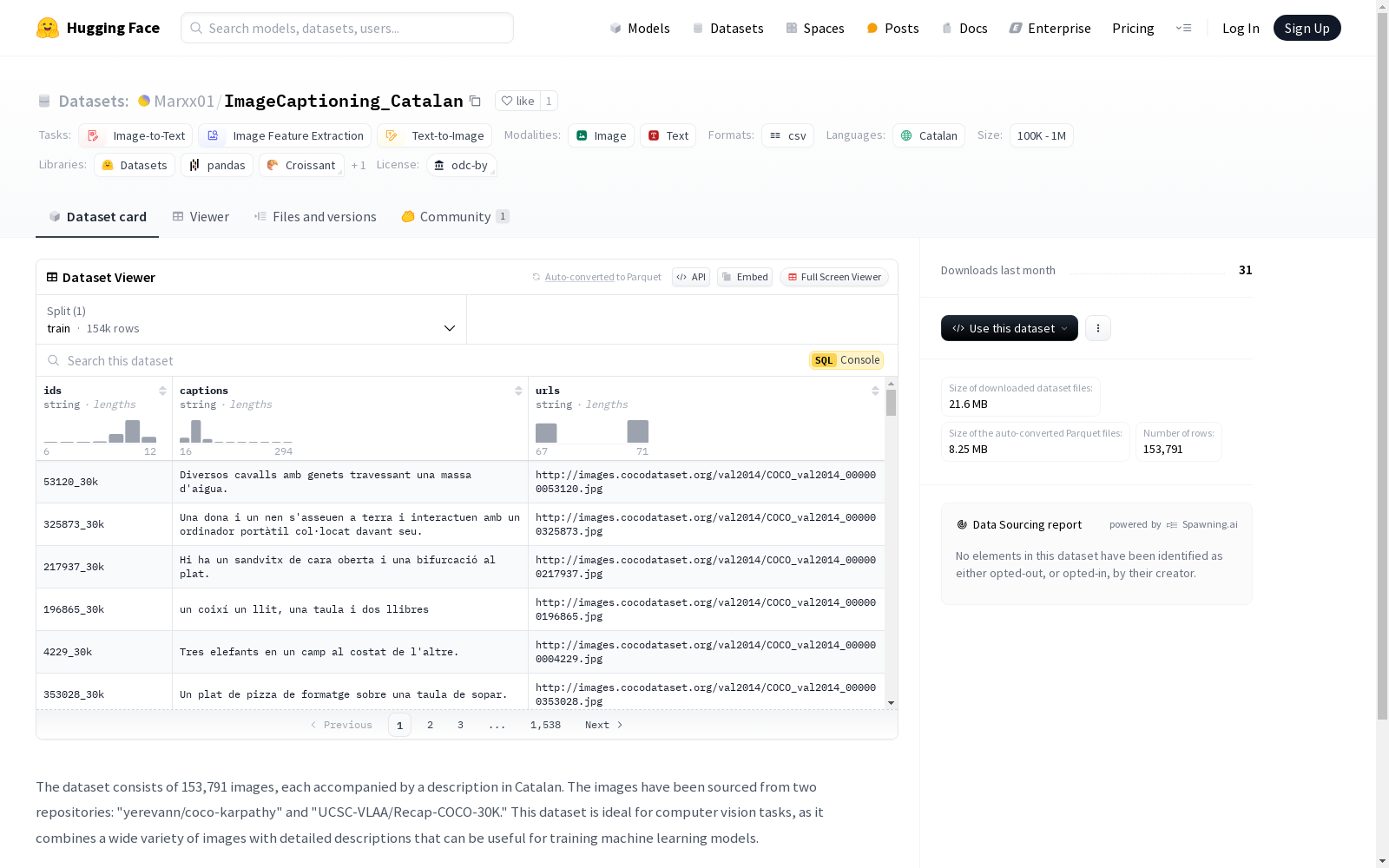
数据集包含153,791张图片,每张图片都附有加泰罗尼亚语的描述。这些图片来自两个资源库:'yerevann/coco-karpathy'和'UCSC-VLAA/Recap-COCO-30K'。该数据集非常适合计算机视觉任务,因为它结合了多种图片和详细的描述,这些描述对于训练机器学习模型非常有用。数据集是免费提供给所有人的,只要给予原始数据源适当的信用。
创建时间:
2024-10-19
原始信息汇总
Image Captioning in Catalan 数据集
概述
- 任务类别:
- 图像到文本
- 图像特征提取
- 文本到图像
- 语言:
- 加泰罗尼亚语 (ca)
- 数据集名称:
- Image Captioning in Catalan
- 数据集大小:
- 100K < n < 1M
数据集详情
- 图像数量:
- 153,791 张
- 图像描述语言:
- 加泰罗尼亚语
- 数据来源:
- yerevann/coco-karpathy
- UCSC-VLAA/Recap-COCO-30K
使用许可
- 许可类型:
- odc-by
- 使用条件:
- 需给予原始数据源适当的信用
搜集汇总
数据集介绍
构建方式
ImageCaptioning_Catalan数据集构建于两个主要图像资源库:'yerevann/coco-karpathy'和'UCSC-VLAA/Recap-COCO-30K'。该数据集精心挑选了153,791张图像,并为每张图像配备了加泰罗尼亚语的详细描述。这种构建方式不仅确保了图像内容的多样性,还通过精确的语言描述增强了数据集的实用性和研究价值。
使用方法
ImageCaptioning_Catalan数据集适用于多种计算机视觉任务,如图像到文本的转换、图像特征提取以及文本到图像的生成。研究者可以通过该数据集训练和测试机器学习模型,特别是在处理加泰罗尼亚语环境下的视觉和语言任务时。使用此数据集时,需确保对原始数据源进行适当的引用,以遵守数据使用的许可协议。
背景与挑战
背景概述
ImageCaptioning_Catalan数据集于近年由多个数据源整合而成,主要来源于'yerevann/coco-karpathy'和'UCSC-VLAA/Recap-COCO-30K'两个图像库。该数据集包含153,791张图像,每张图像均配有加泰罗尼亚语的详细描述,旨在为计算机视觉任务提供丰富的训练资源。其核心研究问题在于如何通过图像与文本的对应关系,提升机器在图像理解与生成自然语言描述方面的能力。该数据集的发布为加泰罗尼亚语地区的自然语言处理与计算机视觉研究提供了重要的数据支持,推动了多模态学习领域的发展。
当前挑战
ImageCaptioning_Catalan数据集在解决图像描述生成问题时,面临的主要挑战包括图像与文本的对齐精度、语言描述的多样性与准确性,以及跨模态特征提取的复杂性。在构建过程中,研究人员需克服数据来源的异构性,确保图像与描述的高质量匹配。此外,加泰罗尼亚语作为相对小众的语言,其语言资源的稀缺性也为数据集的构建增加了难度。如何平衡数据规模与标注质量,同时确保数据集的多样性与代表性,是构建过程中亟待解决的关键问题。
常用场景
经典使用场景
ImageCaptioning_Catalan数据集在计算机视觉领域中被广泛用于图像到文本的生成任务。该数据集包含153,791张图像,每张图像均配有加泰罗尼亚语的详细描述,为研究人员提供了丰富的视觉和语言数据。通过该数据集,研究者可以训练和评估图像描述生成模型,探索图像与文本之间的复杂关系。
解决学术问题
该数据集解决了图像描述生成任务中的语言多样性问题,特别是在加泰罗尼亚语这一相对小众语言的应用场景中。通过提供高质量的图像和对应的加泰罗尼亚语描述,研究者能够开发出更具普适性和语言适应性的模型,推动多语言图像描述生成技术的发展。
实际应用
在实际应用中,ImageCaptioning_Catalan数据集可用于开发多语言图像描述系统,特别是在加泰罗尼亚语地区的教育和文化传播领域。例如,该数据集可以用于构建自动化的图像描述工具,帮助视障人士理解图像内容,或用于博物馆和艺术馆的数字化展示,提供多语言的图像解说服务。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理的交叉领域,ImageCaptioning_Catalan数据集为加泰罗尼亚语的图像描述任务提供了独特的资源。近年来,随着多模态学习的兴起,研究者们逐渐关注如何将视觉信息与语言信息更有效地结合。该数据集不仅为图像到文本的生成任务提供了丰富的训练样本,还为跨语言图像描述模型的开发提供了新的可能性。特别是在低资源语言处理领域,加泰罗尼亚语作为一门区域性语言,其数据资源的稀缺性使得该数据集显得尤为重要。研究者们正探索如何利用该数据集提升多语言图像描述模型的性能,同时也在研究如何通过迁移学习等技术,将高资源语言的知识迁移到加泰罗尼亚语等低资源语言上。这一研究方向不仅推动了多模态学习技术的发展,也为区域性语言的数字化保护与推广提供了技术支持。
以上内容由遇见数据集搜集并总结生成


