fashion-lookmatch-dataset
收藏Hugging Face2026-01-17 更新2026-01-18 收录
下载链接:
https://huggingface.co/datasets/orianrivlin/fashion-lookmatch-dataset
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含1,000张使用Stable Diffusion XL (SDXL)生成的合成时尚图像,旨在用于构建视觉检索和服装推荐系统。数据集涵盖了12个时尚类别,确保类别平衡、风格多样性和颜色分布。每个样本包含图像、类别、风格标签、颜色、季节、描述和生成种子等信息。
创建时间:
2026-01-17
原始信息汇总
Fashion LookMatch Synthetic Dataset 数据集概述
基本信息
- 数据集名称: Fashion LookMatch Synthetic Dataset
- 发布者/地址: orianrivlin
- 许可证: MIT
- 任务类别: 图像分类、文生图
- 标签: 时尚、合成数据、sdxl、lookmatch
- 数据规模: 1K<n<10K
数据集简介
该数据集包含 1000张合成时尚图像,使用 Stable Diffusion XL (SDXL) 生成。它是“构建你自己的AI应用”最终项目的一部分。数据集旨在用于构建 视觉检索与服装推荐系统。
数据内容与结构
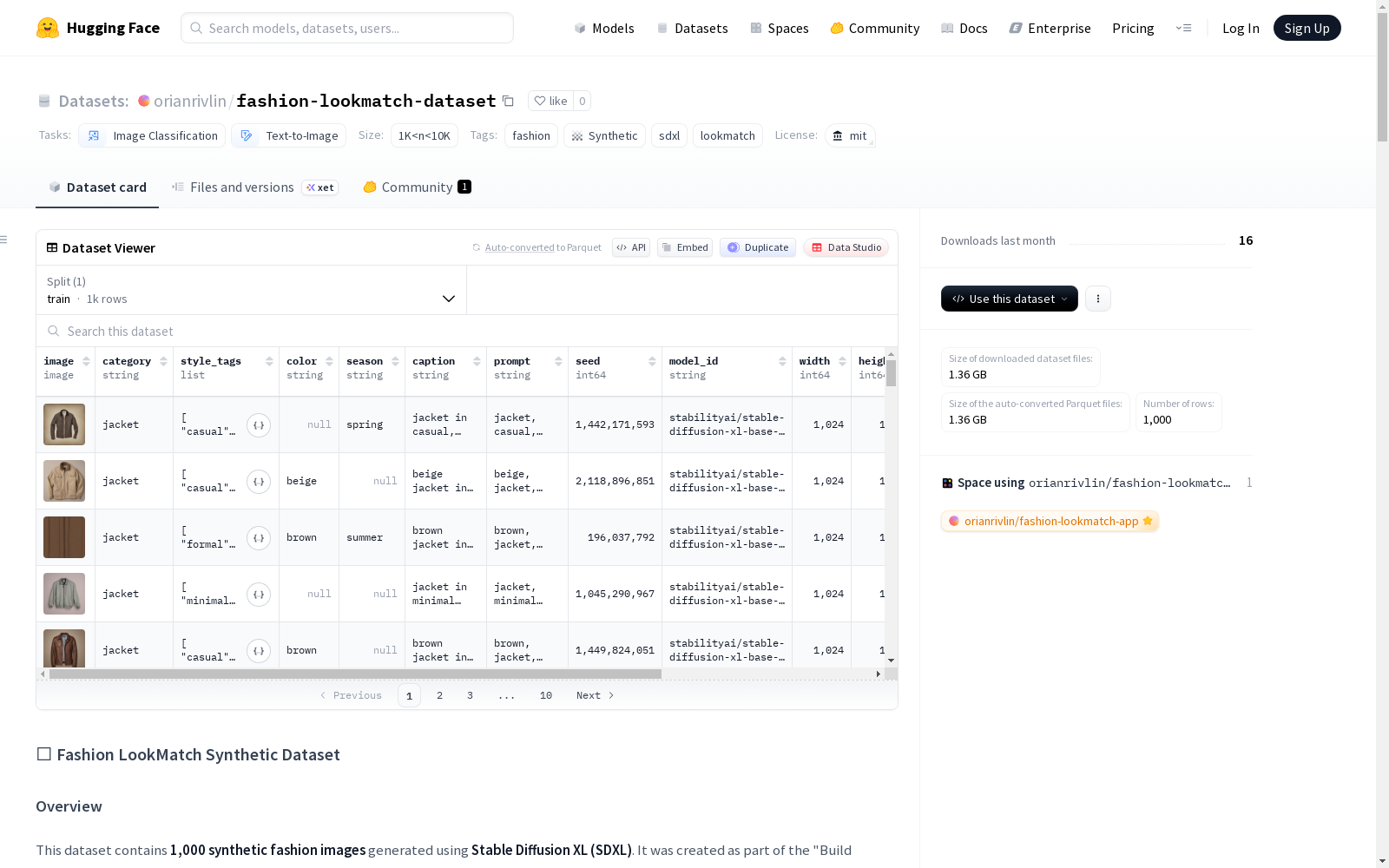
数据集包含1000个样本,每个样本包含以下字段:
| 字段 | 类型 | 描述 |
|---|---|---|
image |
图像 | 生成的时尚单品图像 (1024x1024) |
category |
字符串 | 类别,例如 jacket, sneakers, dress |
style_tags |
字符串列表 | 风格标签,例如 [casual, vintage] |
color |
字符串 | 主色调 (可选) |
season |
字符串 | 季节性 (可选) |
caption |
字符串 | 自然语言描述 |
seed |
整数 | 用于生成的随机种子 (确保可复现性) |
数据质量与多样性分析
为确保数据集的质量和平衡性,进行了严格的探索性数据分析。
-
类别平衡: 确保所有12个时尚类别均匀分布,以防止检索过程中的类别偏差。
- 可视化地址: https://huggingface.co/datasets/orianrivlin/fashion-lookmatch-dataset/resolve/main/eda_assets/eda_01_category_dist.png
-
风格多样性: 数据集涵盖多种风格标签(休闲、正式、街头服饰等)。注意,单品可以拥有多个标签。
- 可视化地址: https://huggingface.co/datasets/orianrivlin/fashion-lookmatch-dataset/resolve/main/eda_assets/eda_02_style_dist.png
-
颜色分布: 分析了色谱以验证视觉多样性。
- 可视化地址: https://huggingface.co/datasets/orianrivlin/fashion-lookmatch-dataset/resolve/main/eda_assets/eda_03_color_pie.png
-
相关性热力图: 分析了类别与风格之间的关系,以理解数据集的语义结构。
- 可视化地址: https://huggingface.co/datasets/orianrivlin/fashion-lookmatch-dataset/resolve/main/eda_assets/eda_04_heatmap.png
-
数据样本: 展示了随机图像样本,体现了“产品照片”美学和标签准确性。
- 可视化地址: https://huggingface.co/datasets/orianrivlin/fashion-lookmatch-dataset/resolve/main/eda_assets/eda_05_sample_grid.png
生成过程
- 模型: stabilityai/stable-diffusion-xl-base-1.0
- 约束条件: “产品照片,纯色背景,无标识”
- 元数据: 基于预定义模式的结构化提示生成。
使用方法
python from datasets import load_dataset
加载完整数据集
dataset = load_dataset("orianrivlin/fashion-lookmatch-dataset", split="train")
查看第一个样本
print(dataset[0])
搜集汇总
数据集介绍
构建方式
在时尚计算领域,高质量且标注详尽的数据集对于视觉检索与搭配推荐系统的研发至关重要。本数据集通过结构化提示生成方法,基于预定义的模式构建了包含12个时尚类别的元数据框架,并利用Stable Diffusion XL模型生成了1000张合成图像。生成过程严格遵循“产品照片、纯色背景、无标识”的视觉约束,确保了图像风格的一致性。每张图像均附带类别、风格标签、颜色、季节及自然语言描述等多维度标注,且生成种子被记录以保证实验的可复现性。
特点
该数据集的核心特征在于其合成数据的多样性与平衡性。通过探索性数据分析,数据集在12个主要时尚类别上实现了均匀分布,有效避免了类别偏差。风格标签覆盖了休闲、正式、街头服饰等多种类型,并支持多标签标注,增强了语义表达的丰富性。色彩分布分析证实了视觉上的多样性,而类别与风格之间的相关性热图则揭示了数据内在的语义结构。所有图像均以1024x1024分辨率呈现,具有统一的“产品照片”美学风格,为模型训练提供了高质量且结构化的视觉素材。
使用方法
该数据集专为支持视觉检索与服装搭配推荐系统的构建而设计。研究人员可通过Hugging Face的`datasets`库便捷加载,直接获取包含图像及多维度标注信息的结构化数据。在应用层面,该数据集适用于图像分类、跨模态检索及文本到图像生成等任务。其详尽的元数据,如类别、风格标签和自然语言描述,为训练深度学习模型提供了丰富的监督信号。通过利用记录的生成种子,研究者可以进一步复现或扩展数据集,推动时尚AI领域在可控生成与个性化推荐方面的探索。
背景与挑战
背景概述
在人工智能与时尚产业深度融合的背景下,视觉检索与穿搭推荐系统成为研究热点。Fashion LookMatch合成数据集应运而生,作为“构建你自己的AI应用”最终项目的一部分,由研究人员Ori Anrivlin创建。该数据集专注于利用生成式人工智能技术,特别是Stable Diffusion XL模型,合成高质量的时尚单品图像,旨在解决传统时尚数据集在多样性、标注一致性与可控生成方面的局限性。其核心研究问题在于如何通过结构化提示工程生成兼具视觉真实性与丰富语义标注的合成数据,以支持跨模态检索与个性化推荐模型的训练与评估,为时尚计算领域提供了新的数据范式。
当前挑战
该数据集致力于应对时尚视觉检索与搭配推荐中的核心挑战,即如何精准理解并匹配用户查询与海量时尚单品在风格、类别、颜色等多维度属性上的复杂关联。构建过程中面临多重挑战:首先,合成数据的真实性与多样性平衡,需确保生成图像既符合“产品摄影”美学,又覆盖广泛的品类、风格与色彩谱系,避免模型过拟合于合成伪影;其次,结构化元数据标注的准确性与一致性,要求通过严谨的提示工程将类别、风格标签等语义信息可靠地嵌入生成过程,并处理多标签共存的情形;最后,数据偏差的规避,需通过探索性数据分析确保类别均匀分布,防止检索系统因数据不平衡而产生推荐偏见。
常用场景
经典使用场景
在时尚计算与计算机视觉交叉领域,该数据集为视觉检索与服装搭配推荐系统的构建提供了关键资源。其经典使用场景集中于训练和评估多模态模型,通过合成图像与结构化元数据的配对,支持基于类别、风格或自然语言描述的服装图像检索任务。研究者可利用该数据集开发先进的嵌入表示学习方法,实现从查询到视觉相似性匹配的端到端系统优化,从而推动个性化时尚推荐技术的发展。
解决学术问题
该数据集有效解决了时尚领域研究中数据稀缺与标注成本高昂的学术难题。通过合成生成技术,它提供了类别平衡、风格多样且标注精确的图像样本,为视觉检索模型的公平性评估与偏差分析奠定了数据基础。其结构化元数据支持跨模态学习研究,促进了图像与文本对齐、细粒度属性识别等核心问题的探索,对提升推荐系统的可解释性与鲁棒性具有重要理论意义。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在多模态检索与生成模型的改进上。例如,研究者基于其结构化提示与图像对,开发了融合注意力机制的跨模态编码器,显著提升了服装属性对齐的精度。此外,该数据集常被用作基准测试集,用于评估对比学习、度量学习等前沿方法在时尚检索任务上的性能,催生了一系列关于合成数据有效性、领域适应与零样本学习的研究论文。
以上内容由遇见数据集搜集并总结生成


