controlled-generated-convos-gpt-4.1-mini
收藏Hugging Face2026-02-03 更新2026-02-05 收录
下载链接:
https://huggingface.co/datasets/isaacchung/controlled-generated-convos-gpt-4.1-mini
下载链接
链接失效反馈官方服务:
资源简介:
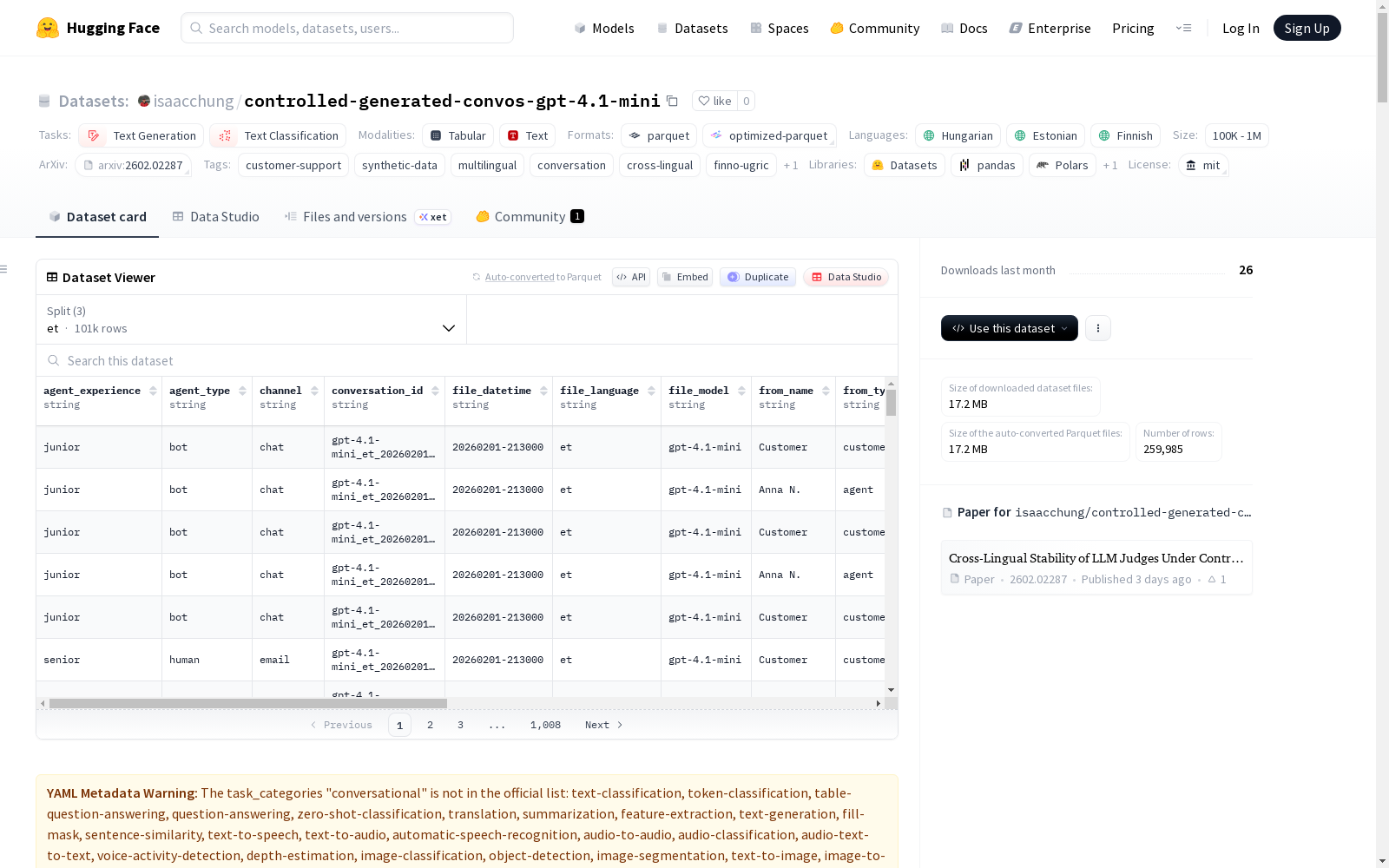
该数据集包含使用gpt-4.1-mini生成的合成客户支持对话,旨在研究语言模型评估中的跨语言稳定性问题,特别关注芬兰-乌戈尔语系(爱沙尼亚语、芬兰语、匈牙利语)和英语。数据集包含259,985条消息和30,000个对话,覆盖46个行业和20种问题类型。每条消息都包含详细的元数据,如对话ID、消息位置、发言者角色、行业类别、问题类型等。该数据集适用于跨语言评估、对话分析、质量评估、标签恢复和排名稳定性分析等任务。数据集采用MIT许可证,主要局限性包括合成数据的固有偏差、生成模型的偏见以及语言和文化代表性的限制。
创建时间:
2026-02-03
搜集汇总
数据集介绍
构建方式
在跨语言自然语言处理研究领域,构建高质量的多语言对话数据集对于评估模型的语言稳定性至关重要。本数据集采用受控合成生成方法,依托gpt-4.1-mini模型,系统性地生成了涵盖匈牙利语、爱沙尼亚语和芬兰语的客户支持对话。生成过程通过结构化参数进行精细控制,包括从超过40个商业领域随机选择行业、定义20余种问题类型,并设定沟通渠道与客服人员属性,确保对话在多样化的预设情境下展开。每条对话均被拆分为独立的消息记录,并完整保留了生成时所用的元数据,从而为后续的细粒度分析奠定了坚实基础。
特点
该数据集的核心特征体现在其专注于芬兰-乌戈尔语系的多语言覆盖与受控生成的设计理念。数据集囊括了三种形态复杂、在训练数据中代表性相对不足的语言,为探究语言模型在跨语言评估中的稳定性提供了独特资源。每条数据记录不仅包含对话内容,还附有丰富的结构化元数据,如行业分类、问题类型、沟通渠道以及客服经验等级等,这些维度共同构成了一个多层次的分析框架。其合成性质虽可能无法完全复现真实对话的全部细微差别,但通过系统化的参数控制,为研究模型在不同语言、领域和情境下的表现一致性创造了高度可比的实验条件。
使用方法
该数据集主要服务于跨语言评估、对话分析与质量评估等研究任务。使用者可通过Hugging Face的`datasets`库便捷加载数据,既可整体导入,也可按语言子集(如爱沙尼亚语‘et’)进行选择性加载。数据集以单一训练分割形式提供,研究者可根据自身需求,依据语言、行业或对话长度等维度灵活划分评估集。典型应用包括分析不同语言间模型性能的一致性、探究对话结构与模式,或尝试根据消息内容恢复其原始的生成参数标签。在进行跨语言对比时,需留意生成模型本身可能存在的语言偏差,并将分析结果置于相应的文化与语言背景中加以审慎考量。
背景与挑战
背景概述
在自然语言处理领域,跨语言评估的稳定性是衡量大语言模型泛化能力的关键指标。由Isaac Chung和Linda Freienthal等人于2026年创建的Controlled Generated Conversations: gpt-4.1-mini数据集,旨在探究LLM评判者在不同语言间的一致性表现。该数据集聚焦于芬兰-乌戈尔语系(包括爱沙尼亚语、芬兰语和匈牙利语)及英语,通过gpt-4.1-mini模型生成了超过25万条合成客户服务对话。其核心研究问题在于评估语言模型在形态复杂且训练数据相对稀缺的语言中,能否保持与英语相当的性能水平,从而推动多语言NLP系统向更公平、包容的方向发展。
当前挑战
该数据集致力于解决跨语言自然语言处理评估中的核心挑战,即如何确保语言模型在多样化的语言环境中展现出稳定且一致的性能。具体而言,挑战体现在模型需克服芬兰-乌戈尔语系丰富的屈折形态和有限训练数据所带来的理解障碍。在构建过程中,研究者面临合成数据固有局限的挑战,包括生成模型可能继承的偏见、对话真实性不足,以及难以完全捕捉特定语言的文化语境和商业沟通习惯。此外,确保各语言变体在语法流畅性、话题覆盖和对话结构上具有可比性,也是一项复杂任务。
常用场景
经典使用场景
在跨语言自然语言处理研究中,该数据集为评估大型语言模型在多样语言环境下的性能稳定性提供了标准化基准。其核心应用场景聚焦于分析模型在芬兰-乌戈尔语系(包括爱沙尼亚语、芬兰语和匈牙利语)与英语之间的跨语言一致性,通过模拟客户支持对话,研究者能够系统检验模型在语法、流畅度和连贯性等维度的表现,尤其关注形态复杂语言在低资源条件下的模型鲁棒性。
解决学术问题
该数据集主要致力于解决跨语言评估中的公平性与可比性难题。通过提供结构化的多语言合成对话,它使研究者能够量化语言模型在不同语言间的性能差异,揭示训练数据偏差对模型评估的影响。其意义在于推动建立更包容的评估框架,促进语言技术在全球范围内的均衡发展,尤其为资源相对匮乏的芬兰-乌戈尔语系研究提供了关键数据支撑。
衍生相关工作
围绕该数据集衍生的经典研究多集中于跨语言评估方法的创新。例如,基于其构建的基准测试被用于探究语言模型评判的一致性,发展针对低资源语言的评估协议。相关工作还拓展至多语言对话生成的质量控制、领域自适应技术,以及合成数据在缓解语言表征不平衡方面的效用分析,进一步丰富了跨语言自然语言处理的研究图谱。
以上内容由遇见数据集搜集并总结生成


