shibing624/nli-zh-all
收藏Hugging Face2023-06-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/shibing624/nli-zh-all
下载链接
链接失效反馈官方服务:
资源简介:
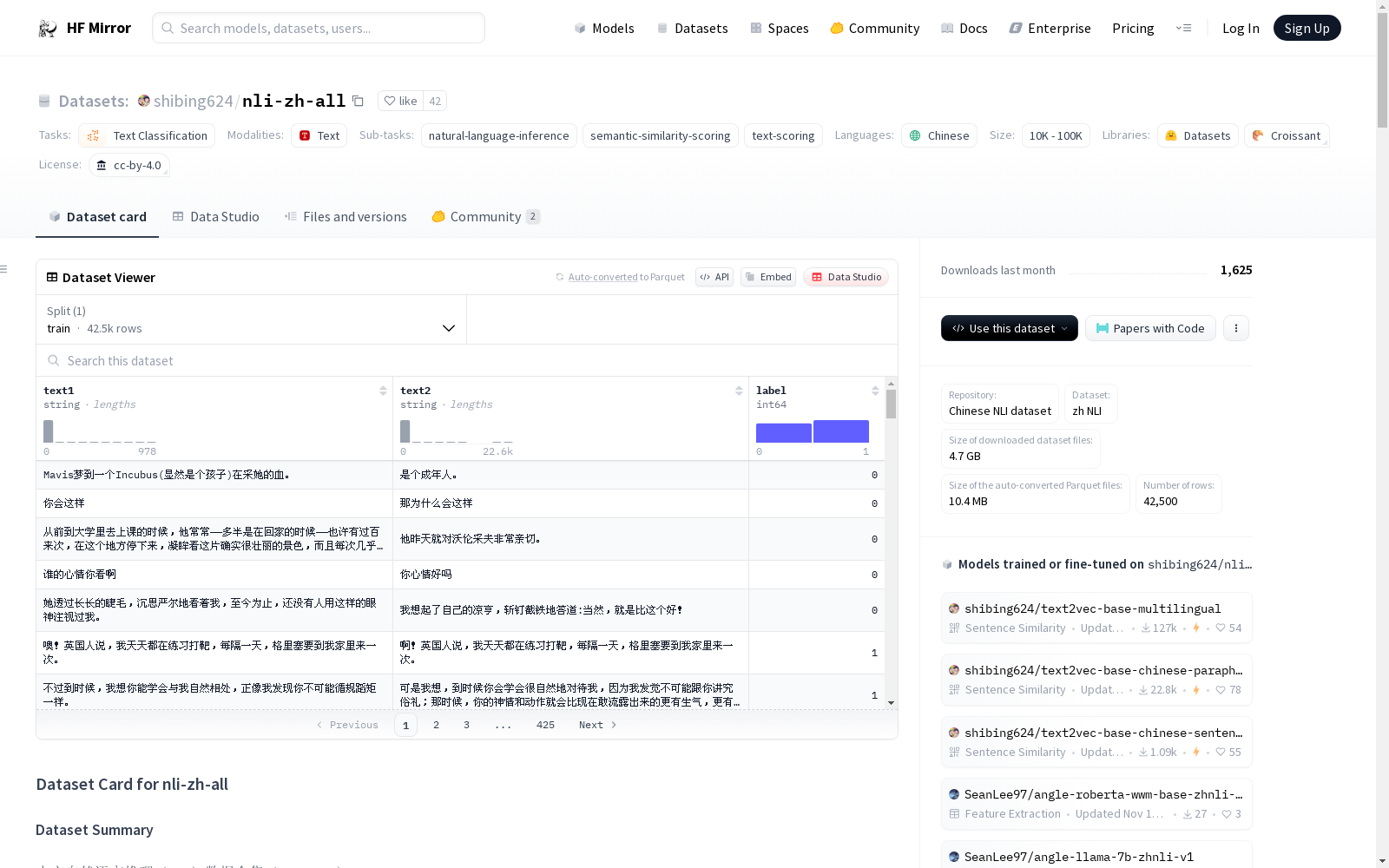
中文自然语言推理(NLI)数据合集(nli-zh-all)整合了文本推理、相似、摘要、问答、指令微调等任务的820万高质量数据,并转化为匹配格式数据集。该数据集支持中文文本匹配任务和文本相似度计算等相关任务。数据集的创建受到m3e-base的启发,合并了中文高质量NLI数据集,并上传到huggingface的datasets,方便大家使用。数据集的结构包括text1、text2和label三个字段,label表示两个文本是否相似。数据集的文件大小为4.7 GB,总数据量为8234680条。
The Chinese Natural Language Inference (NLI) dataset collection nli-zh-all integrates 8,234,680 high-quality data instances from tasks including textual inference, text similarity, summarization, question answering, and instruction tuning, and is formatted into a dataset compatible with text matching tasks. This dataset supports Chinese text matching tasks and related downstream tasks such as text similarity calculation. Inspired by m3e-base, this dataset was compiled by merging high-quality Chinese NLI datasets, and uploaded to Hugging Face Datasets for convenient public use. The dataset comprises three fields: text1, text2, and label, where label denotes whether the two texts are similar. The total file size of the dataset is 4.7 GB.
提供机构:
shibing624
原始信息汇总
数据集概述
数据集名称
- 中文自然语言推理(NLI)数据合集(nli-zh-all)
数据集描述
- 整合了文本推理,相似,摘要,问答,指令微调等任务的820万高质量数据,并转化为匹配格式数据集。
支持的任务和排行榜
- 支持任务: 中文文本匹配任务,文本相似度计算等相关任务。
- 排行榜: NLI_zh leaderboard
语言
- 数据集语言: 简体中文文本。
数据集结构
- 数据实例: 示例包括两个文本字段(text1, text2)和一个标签字段(label),其中标签1表示相似,0表示不相似。
- 数据字段: 包括text1, text2, label三个字段。
- 数据分割: 数据集经过处理后,各个子集的行数详细列出。
数据集创建
- 来源数据: 数据集构建方法可在提供的脚本中找到,所有数据均上传到huggingface datasets。
- 社会影响: 该数据集用于评估文本表示系统,特别是通过表示学习方法诱导的系统,在预测给定上下文中的真实条件任务中的表现。
许可证信息
- 许可证: cc-by-4.0
贡献者
- 贡献者: shibing624
搜集汇总
数据集介绍
构建方式
该数据集名为'nli-zh-all',由shibing624创建,旨在为中文自然语言推理任务提供大规模的数据支持。数据集整合了来自不同领域和任务的高质量中文数据,包括文本推理、相似度、摘要、问答和指令微调等,总计820万条数据。数据来源多样,涵盖了百科、电商、医药、学术等多个领域,从而保证了数据集的广泛性和多样性。为了构建这个数据集,开发者采用了多种技术,包括数据清洗、格式转换等,最终将数据转化为适合自然语言推理任务的格式。
特点
nli-zh-all数据集具有以下特点:首先,数据规模庞大,总计820万条数据,为研究提供了丰富的样本;其次,数据来源广泛,涵盖了多个领域和任务,有助于模型学习更全面的语义表示;再次,数据格式规范,方便研究人员进行使用和扩展;最后,数据集支持多种自然语言推理任务,包括文本匹配、文本相似度计算等,具有很高的实用价值。
使用方法
使用nli-zh-all数据集,首先需要了解数据集的结构和特点。数据集包含了多个数据集,每个数据集都有自己独特的任务类型和领域。使用数据集时,可以根据具体的任务需求选择合适的数据集。其次,需要了解数据集的格式,以便进行数据加载和处理。nli-zh-all数据集以JSONL格式存储,每个数据点包含'text1'、'text2'和'label'三个字段,分别表示两个文本和它们之间的相似度标签。最后,需要了解数据集的使用方式。可以使用数据集进行模型训练、评估和测试,也可以用于开发新的自然语言推理应用。
背景与挑战
背景概述
在自然语言处理(NLP)领域,中文自然语言推理(NLI)是一项核心任务,旨在理解和模拟人类在特定上下文中判断陈述真实性条件的能力。'shibing624/nli-zh-all'数据集,由shibing624创建并维护,是一个庞大的中文NLI数据集,它整合了超过820万条高质量数据,涵盖了文本推理、相似度、摘要、问答、指令微调等任务。该数据集的创建旨在为中文NLP研究提供一种强大的基准,并促进自然语言推理模型的发展。自上传至Hugging Face平台以来,该数据集已被广泛用于学术研究,并在相关领域中产生了深远的影响。
当前挑战
尽管'nli-zh-all'数据集为中文NLP研究提供了宝贵的资源,但其也面临着一些挑战。首先,数据集的规模和多样性虽然强大,但在实际应用中,如何确保模型的泛化能力和鲁棒性仍然是一个重要的问题。其次,数据集的构建过程中,如何平衡不同类型数据的比例,以及如何处理可能存在的偏差,也是研究人员需要考虑的问题。此外,随着NLP技术的不断发展,如何将'nli-zh-all'数据集与最新的模型训练技术相结合,以实现更好的模型性能,也是一项持续性的挑战。
常用场景
经典使用场景
在中文自然语言处理领域,shibing624/nli-zh-all数据集被广泛用于训练和评估自然语言推理模型。该数据集涵盖了文本推理、相似度计算、摘要、问答和指令微调等多种任务,为研究者在这些领域提供了丰富的训练数据。此外,数据集的多样性和大规模性使其成为评估模型泛化能力和鲁棒性的理想选择。
实际应用
shibing624/nli-zh-all数据集在实际应用中具有广泛的价值。例如,在问答系统中,数据集可用于训练模型理解用户提问和答案之间的关系,提高问答系统的准确性和效率。在文本相似度计算任务中,数据集可用于训练模型识别文本间的相似性,为信息检索、文本摘要和机器翻译等领域提供支持。此外,数据集还可用于训练模型进行文本推理,提高模型在文本分析和决策支持等任务中的能力。
衍生相关工作
shibing624/nli-zh-all数据集的发布和整合促进了中文自然语言处理领域的研究。基于该数据集,研究者可以开展更多关于自然语言推理、文本相似度计算和问答系统等方面的研究。此外,数据集的多样性和大规模性也为模型的训练和评估提供了更多可能性,有助于推动自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


