two-million-bluesky-posts
收藏Hugging Face2024-11-28 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/alpindale/two-million-bluesky-posts
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含从Bluesky Social的firehose API收集的200万条公开帖子,旨在用于机器学习研究和社交媒体数据的实验。数据集包括帖子文本内容、元数据以及媒体附件和回复关系的信息。数据集有两个配置:默认配置和带有语言预测的配置。默认配置包含帖子的基本信息,而带有语言预测的配置在此基础上增加了语言预测代码和置信度分数。数据集主要用于训练和测试语言模型、分析社交媒体发布模式、研究对话结构和回复网络、以及社交媒体内容审核等任务。
This dataset contains 2 million public posts collected from the firehose API of Bluesky Social, and is intended for machine learning research and social media data experiments. The dataset includes post text content, metadata, as well as information about media attachments and reply relationships. The dataset offers two configurations: the default configuration and the language prediction-augmented configuration. The default configuration contains basic post information, while the language prediction-augmented configuration adds language prediction codes and confidence scores based on the default setup. This dataset is primarily used for tasks such as training and testing language models, analyzing social media posting patterns, researching conversation structures and reply networks, and social media content moderation.
创建时间:
2024-11-28
原始信息汇总
2 Million Bluesky Posts 数据集
概述
该数据集包含从Bluesky Social的firehose API收集的200万条公开帖子,旨在用于机器学习研究和社交媒体数据的实验。
数据集详情
- 数据来源: Bluesky Social的firehose API
- 帖子数量: 200万条
- 内容: 每条帖子包含文本内容、元数据、媒体附件信息和回复关系信息
- 语言: 多语言(主要为英语)
- 许可证: 数据集的使用受Bluesky的条款服务约束
用途
该数据集可用于:
- 训练和测试社交媒体内容的语言模型
- 分析社交媒体发帖模式
- 研究对话结构和回复网络
- 社交媒体内容审核研究
- 使用社交媒体数据进行自然语言处理任务
数据集结构
数据集提供两种配置:
默认配置
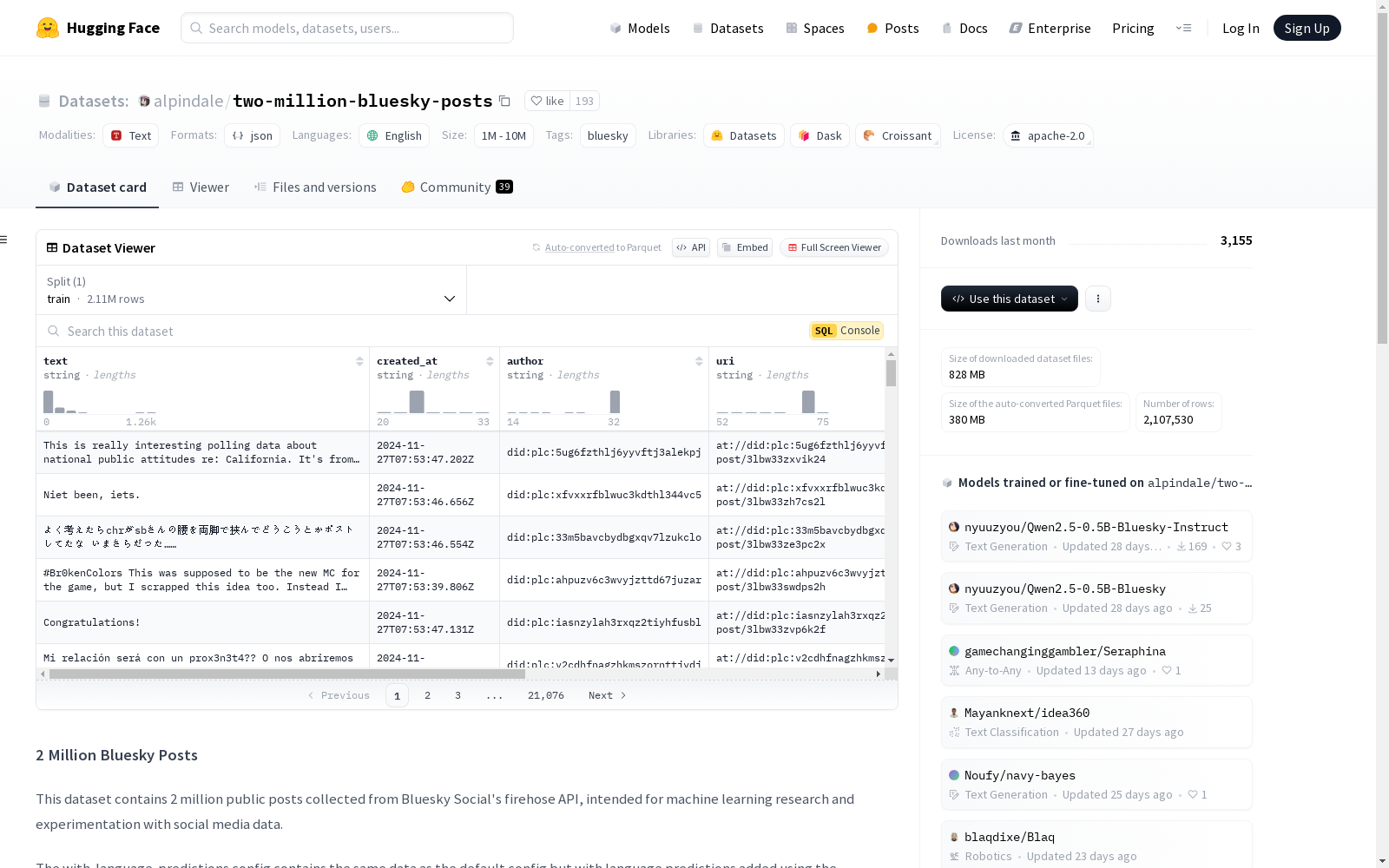
每条帖子包含以下字段:
- text: 帖子主要内容
- created_at: 帖子创建时间戳
- author: 帖子作者的Bluesky用户名
- uri: 帖子的唯一标识符
- has_images: 布尔值,指示帖子是否包含图片
- reply_to: 如果是回复,则为父帖子的URI(否则为null)
带语言预测的配置
包含默认配置的所有字段,并额外包含:
- predicted_language: 预测的语言代码(例如,eng_Latn, deu_Latn)
- language_confidence: 语言预测的置信度分数(0-1)
语言预测使用glotlid模型通过fasttext添加。
偏差、风险和限制
该数据集的目标是让您玩得开心 :)
搜集汇总
数据集介绍
构建方式
该数据集通过Bluesky Social的firehose API收集了200万条公开帖子,旨在为社交媒体数据的机器学习研究和实验提供支持。每条帖子均包含文本内容、元数据、媒体附件信息以及回复关系。数据集由Alpin Dale精心整理,主要语言为英语,使用需遵循Bluesky的服务条款。
特点
数据集包含两种配置:默认配置和带语言预测的配置。默认配置涵盖帖子的文本内容、创建时间戳、作者信息、唯一标识符、是否包含图片以及回复关系。带语言预测的配置在默认基础上增加了预测语言代码及其置信度,使用glotlid模型通过fasttext实现语言预测。
使用方法
该数据集适用于多种研究场景,包括社交媒体内容的语言模型训练与测试、发帖模式分析、对话结构与回复网络研究、社交媒体内容审核研究以及自然语言处理任务。用户可根据需求选择默认配置或带语言预测的配置,灵活应用于不同研究目标。
背景与挑战
背景概述
在社交媒体数据研究领域,Bluesky Social作为一个新兴平台,其公开数据为自然语言处理和社会网络分析提供了丰富的资源。由Alpin Dale精心策划的two-million-bluesky-posts数据集,包含了从Bluesky Social的firehose API中收集的200万条公开帖子。该数据集不仅涵盖了文本内容,还包括元数据、媒体附件信息以及回复关系,旨在为机器学习研究和社会媒体数据分析提供实验基础。自发布以来,该数据集在训练和测试语言模型、分析社交媒体发布模式、研究对话结构及回复网络等方面展现了其独特的价值。
当前挑战
尽管two-million-bluesky-posts数据集为社交媒体研究提供了宝贵的数据资源,但在其应用过程中仍面临诸多挑战。首先,社交媒体数据的动态性和多样性使得模型训练和测试的泛化能力受到考验。其次,数据集中的语言预测虽然借助了glotlid模型,但语言识别的准确性和置信度仍需进一步提升,以确保研究结果的可靠性。此外,社交媒体数据的隐私和伦理问题也不容忽视,如何在保护用户隐私的同时进行有效的数据分析,是研究者必须面对的重要课题。
常用场景
经典使用场景
在社交媒体数据分析领域,two-million-bluesky-posts数据集为研究者提供了一个丰富的资源库,用于探索Bluesky平台上的用户行为模式。该数据集广泛应用于语言模型的训练与测试,特别是在处理社交媒体特有的非正式语言和多样化表达方面,展现了其独特的价值。
实际应用
在实际应用中,two-million-bluesky-posts数据集被用于开发更精准的社交媒体监控工具和内容推荐系统。企业和研究机构利用这些数据来优化用户互动策略,提升内容的相关性和用户参与度,从而在竞争激烈的社交媒体市场中占据有利位置。
衍生相关工作
基于two-million-bluesky-posts数据集,学术界已衍生出多项经典研究,包括社交媒体语言模型的改进、用户行为预测算法的开发以及社交媒体网络结构的分析。这些研究不仅推动了社交媒体数据分析技术的发展,也为理解现代社交媒体生态提供了新的视角和方法。
以上内容由遇见数据集搜集并总结生成


