pango-sample
收藏Hugging Face2025-07-22 更新2025-07-23 收录
下载链接:
https://huggingface.co/datasets/chakra-labs/pango-sample
下载链接
链接失效反馈官方服务:
资源简介:
Pango数据集包含了用户在实际工作中使用生产力应用程序的真实电脑交互数据,旨在通过众包平台收集用户在实际工作会话中的自然电脑交互,解决现有计算机使用代理训练数据集的规模、上下文、分布和错误模式等问题。数据集提供了详细的输入元数据和合成思考元数据,用于训练推理VLMs,并保证了数据质量。
创建时间:
2025-07-21
原始信息汇总
Pango Sample: 真实世界计算机使用代理训练数据集
数据集概述
- 名称: Pango Sample: Real-World Computer Use Agent Training Data
- 简称: Pango (Productivity Applications with Natural GUI Observations)
- 语言: 英语
- 标签: 计算机使用
- 类型: 真实世界计算机交互数据
数据集背景
- 动机: 解决现有计算机使用代理(CUA)训练数据集的局限性:
- 规模限制
- 人工场景
- 分布差距
- 缺少错误模式
- 特点: 捕获真实用户执行真实工作任务的交互数据
数据收集方法
- 平台: Pango众包平台
- 工具: Chrome扩展程序
- 应用范围: Google Sheets, Google Slides, Figma, Canva等生产力应用
- 用户分布: 全球180+国家/地区
- 补偿机制: 基于会话时长和数据质量付费
数据结构
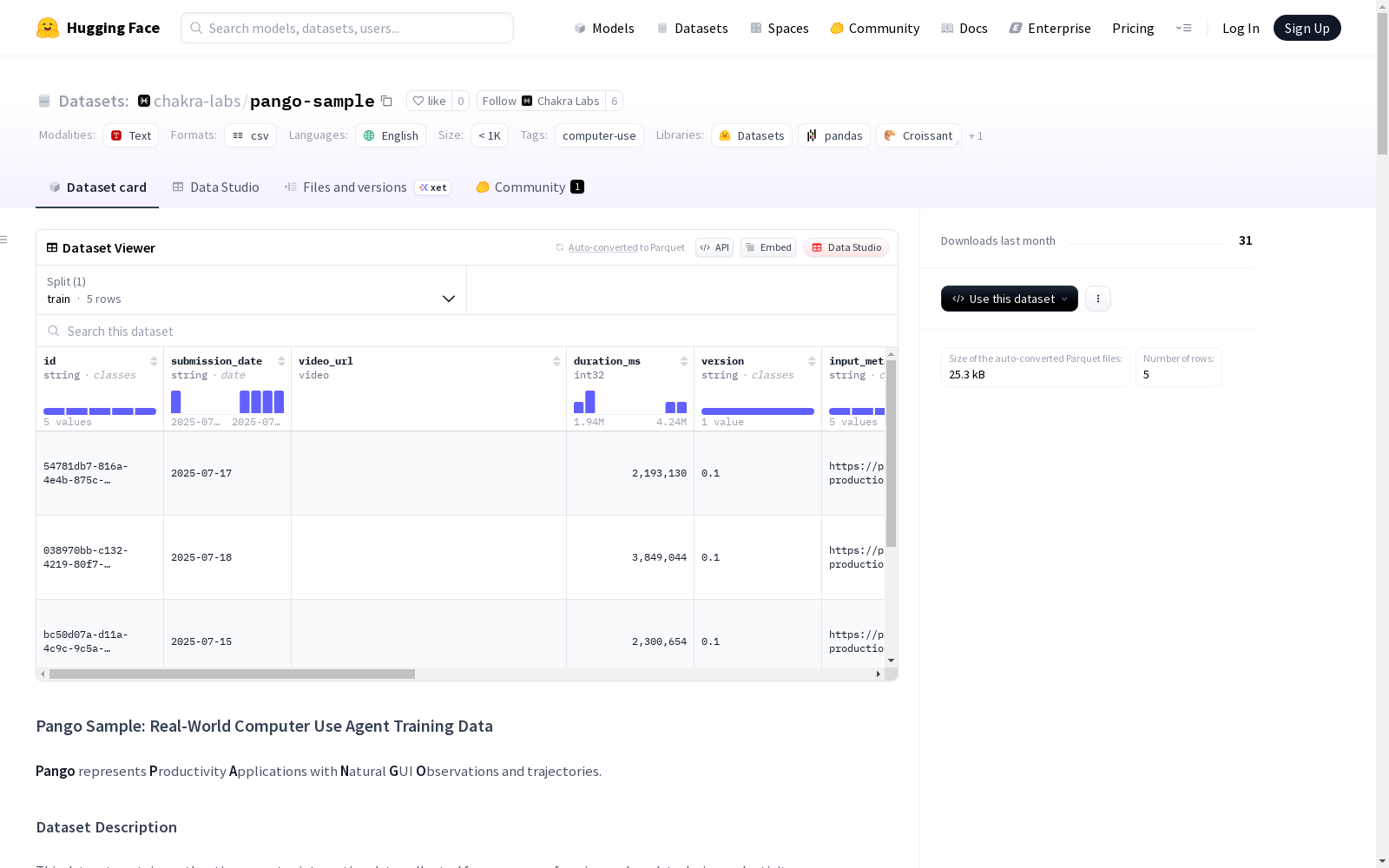
核心字段
id: 唯一会话标识符video_url: 交互会话的屏幕录像input_metadata: 结构化交互事件(JSON格式)task_description: 用户提供的任务描述quest_type: 应用类别profession: 用户专业背景synthetically_generated_instruction: 合成生成的任务指令synthetically_generated_thought_metadata: (Beta)合成生成的步骤思考
输入元数据模式
json { "relative_timestamp_ms": 1028, "type": "click", "x": 186.0, "y": 62.445, "button": "button_left", "screenshot_url": "https://...", "click_count": 1 }
关键字段:
- 事件类型: click/input/key_down/key_up/mouseover_start/mouseover_end/drag_start/drag_end/scroll
- 屏幕坐标: x,y
- 时间戳: relative_timestamp_ms
- 截图: screenshot_url
思考元数据(Beta)
- 用途: 增强VLM训练
- 生成参数:
- α=7 (前向窗口)
- β=15 (后向窗口)
- γ=15 (批间隔)
- 生成方法: 使用GPT-4o视觉API处理
质量保证
- 自动过滤无效交互和隐私内容
- 基于任务连贯性的质量评分
- 差分隐私技术
- 补偿算法激励真实参与
应用场景
- 计算机使用代理训练
- 人机交互行为研究
- GUI自动化系统开发
- 时序推理和错误恢复研究
伦理考量
- 用户知情同意
- 隐私内容自动过滤
- 公平补偿机制
- 符合众包研究伦理准则
数据规模
- 当前状态: 持续增长中
- 2025目标: 100,000+小时
引用格式
bibtex @dataset{pango2025, title={Pango: Real-World Computer Use Agent Training Data}, author={Chakra Labs}, year={2025}, url={https://huggingface.co/datasets/chakra-labs/pango} }
联系方式
- 机构: Chakra Labs
- 邮箱: nirmal@chakra-labs.com
搜集汇总
数据集介绍
构建方式
在计算机使用代理(CUA)研究领域,数据采集的真实性与规模直接影响模型性能。Pango数据集通过创新的众包平台构建,采用Chrome扩展程序精准捕获全球180余国用户在实际工作场景中的自然交互行为。数据采集聚焦生产力应用(如Google Sheets、Figma等),通过结构化任务设计确保数据多样性,同时运用自动化过滤、质量评分和差分隐私技术保障数据安全与质量。
特点
该数据集的核心价值在于突破了传统仿真数据的局限,包含真实工作场景下的完整交互轨迹、错误恢复模式及多维度元数据。其特色在于:1)首创合成思维标注系统,通过GPT-4o生成动作步骤的认知推理链;2)采用时空聚合算法(α=7前向窗口,β=15后向窗口)构建上下文关联;3)提供屏幕坐标归一化、事件类型细分等17类交互特征,为多模态代理训练提供丰富信号。
使用方法
研究者可通过HuggingFace平台获取结构化数据文件,每条记录包含视频URL、交互元数据及合成指令。建议使用流程为:1)基于input_metadata重建用户操作序列;2)结合synthetically_generated_thought_metadata训练决策推理模型;3)利用profession字段进行跨领域泛化测试。该数据集特别适用于开发具有错误恢复能力的GUI自动化系统,或研究人机交互中的时序决策机制。
背景与挑战
背景概述
Pango-sample数据集由Chakra Labs于2025年推出,旨在解决计算机使用代理(CUA)训练数据的关键局限性。该数据集通过Pango平台收集真实用户在生产力应用中的自然交互数据,覆盖Google Sheets、Google Slides、Figma和Canva等主流软件。相较于传统人工标注数据集如Mind2Web或OSWorld,其创新性体现在三个方面:采用众包模式获取全球180余国家用户的真实工作场景数据;完整记录包括错误恢复在内的完整交互轨迹;应用差分隐私技术保障数据安全。这一数据集的建立为人机交互研究和智能体训练提供了前所未有的真实世界基准。
当前挑战
构建Pango-sample数据集面临双重挑战。在领域问题层面,需克服现有CUA训练数据存在的规模限制(平均仅数千任务)、场景失真(脚本化演示为主)和分布偏差(跨界面泛化能力差)等核心问题。在数据构建过程中,技术挑战包括:多模态数据同步采集的精确性保障,涉及屏幕录像与元事件的时间对齐;用户隐私保护与数据效用的平衡,需部署自动化敏感信息过滤系统;以及合成思维标注的生成质量把控,每个步骤需消耗约3万输入令牌进行GPT-4o的高精度推理。这些挑战的解决直接影响了数据集在训练视觉语言模型时的有效性边界。
常用场景
经典使用场景
在计算机交互行为研究中,Pango数据集因其真实的用户工作场景记录而成为经典。研究者利用该数据集分析用户在Google Sheets、Figma等生产力工具中的自然操作序列,包括点击轨迹、输入模式和错误恢复行为。这些数据特别适用于构建基于人类真实行为的基准测试,为评估计算机使用代理(CUA)的泛化能力提供了黄金标准。
解决学术问题
该数据集有效解决了人机交互领域长期存在的四大挑战:通过大规模真实任务数据(如财务分析、设计创作)突破传统数据集规模限制;捕获非脚本化的自然工作流程以弥合实验室环境与现实的差距;包含错误操作序列为研究故障恢复机制提供样本;跨180余国家的用户分布确保了界面交互模式的多样性。这些特性显著提升了代理模型在开放环境中的鲁棒性研究。
衍生相关工作
基于Pango的衍生研究包括UI-TARS 1.5多模态推理模型,该工作利用数据集中的合成思维元数据训练视觉语言模型理解界面操作逻辑。斯坦福团队提出的ACT-1框架通过分析跨应用任务流,建立了首个能处理复杂工作流的数字代理。这些突破性工作均引用Pango作为关键训练数据源,推动了人机协同办公的前沿发展。
以上内容由遇见数据集搜集并总结生成


