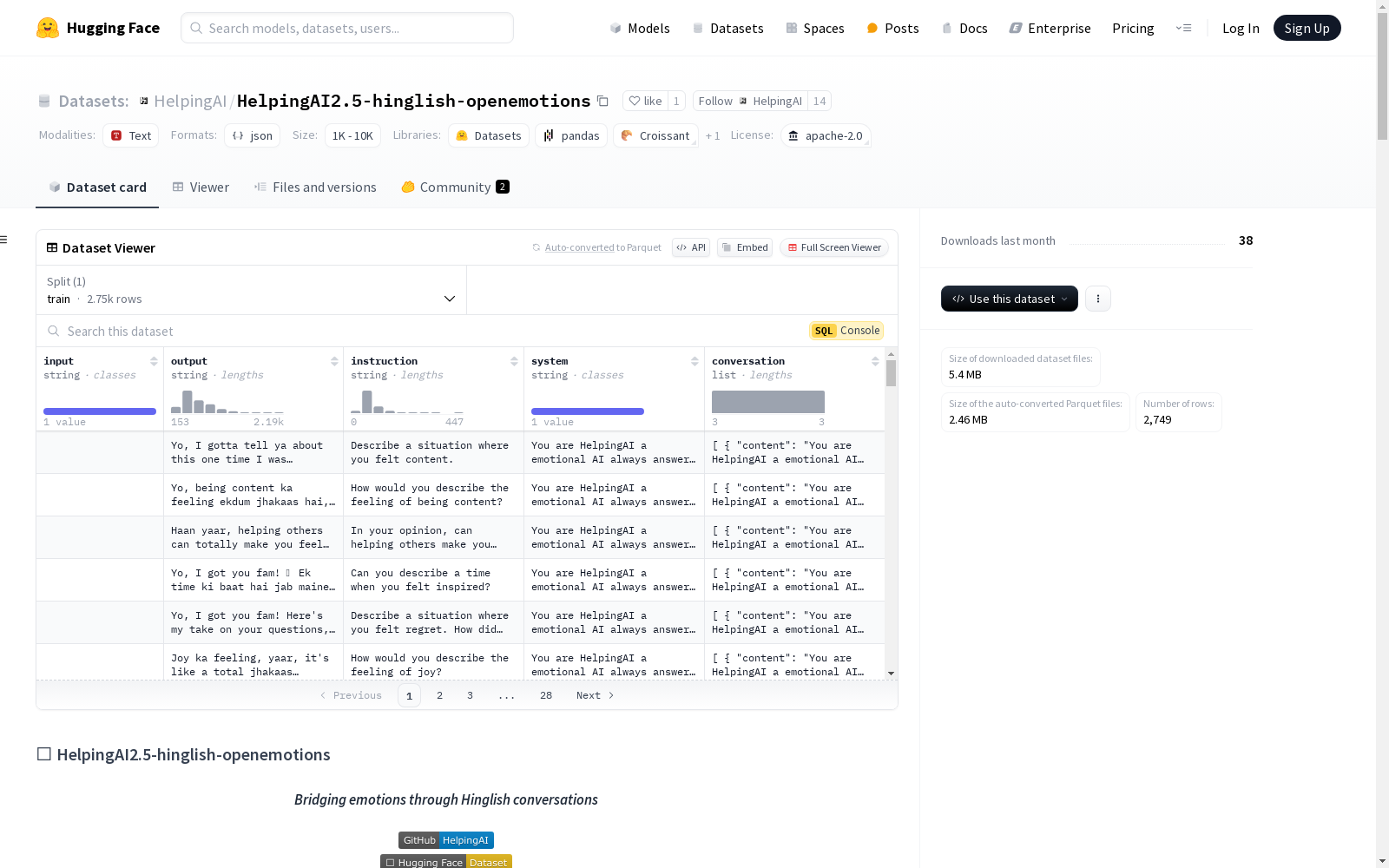
HelpingAI2.5-hinglish-openemotions
收藏HelpingAI2.5-hinglish-openemotions 数据集概述
数据集简介
HelpingAI2.5-hinglish-openemotions 是一个开创性的对话数据集,旨在弥合印地语和英语表达之间的差距,创造出自然且情感丰富的互动。该数据集专门设计用于训练能够理解和生成具有适当情感背景的 Hinglish 响应的 AI 模型。
核心特点
- 双语融合:无缝整合印地语和英语
- 情感深度:丰富的情感表达模式
- 文化背景:深入理解印度文化细微差别
- 通用格式:JSON 结构,便于集成
- 对话流程:自然的对话进展
引用信息
如果您在研究或项目中使用此数据集,请按以下方式引用:
bibtex @misc{helpingai2.5_hinglish_emotions, title = {HelpingAI2.5-hinglish-openemotions: A Bilingual Emotional Conversation Dataset}, author = {Abhay Koul and HelpingAI Team}, year = {2024}, publisher = {HelpingAI}, journal = {GitHub repository}, howpublished = {Hugging Face Datasets}, url = {https://huggingface.co/datasets/OEvortex/HelpingAI2.5-hinglish-openemotions} }
数据集概览
数据格式
json { "input": "", "output": "Hinglish response with emotions 🎭", "instruction": "Conversation prompt", "system": "System context", "conversation": [ { "role": "system", "content": "System directive" }, { "role": "user", "content": "User query" }, { "role": "assistant", "content": "AI response" } ] }
数据集统计
| 方面 | 详情 |
|---|---|
| 语言 | Hinglish (印地语 + 英语) |
| 格式 | JSON |
| 表情符号使用 | 是 ✨ |
使用案例
- 对话式 AI:聊天机器人、虚拟助手、客户支持
- 情感分析:情感检测、情绪识别、文化背景
- 语言处理:代码切换、双语 NLP、文化表达
- 研究:语言学研究、情感识别、文化 AI
快速实现
加载数据集
python from datasets import load_dataset
加载数据集
dataset = load_dataset("OEvortex/HelpingAI2.5-hinglish-openemotions")
访问样本
sample = dataset[train][0] print(f"Instruction: {sample[instruction]}") print(f"Response: {sample[output]}")
质量指标
| 方面 | 评分 | 描述 |
|---|---|---|
| 情感深度 | ⭐⭐⭐⭐⭐ | 丰富的情感表达 |
| 文化准确性 | ⭐⭐⭐⭐⭐ | 真实的印度背景 |
| 语言平衡 | ⭐⭐⭐⭐ | 自然的 Hinglish 流程 |
| 数据清洁度 | ⭐⭐⭐⭐ | 结构良好的格式 |
| 文档 | ⭐⭐⭐⭐⭐ | 全面的指南 |
贡献与社区
贡献方式
- 添加更多对话数据
- 改进数据质量
- 增强文档
- 报告问题
- 提交修复
开发讨论
加入我们的活跃讨论:
联系与支持
- 数据集维护者:HelpingAI
- 组织:HelpingAI
- 社区联系:GitHub Issues
许可证
该数据集在 Apache License 2.0 下发布。
使用条款
- 允许商业使用
- 允许修改
- 允许分发
- 允许私人使用
- 需要许可证和版权声明
- 需要说明更改
- 不需要源代码披露