EmbRACE-3K
收藏arXiv2025-07-15 更新2025-07-16 收录
下载链接:
https://mxllc.github.io/EmbRACE-3K/
下载链接
链接失效反馈官方服务:
资源简介:
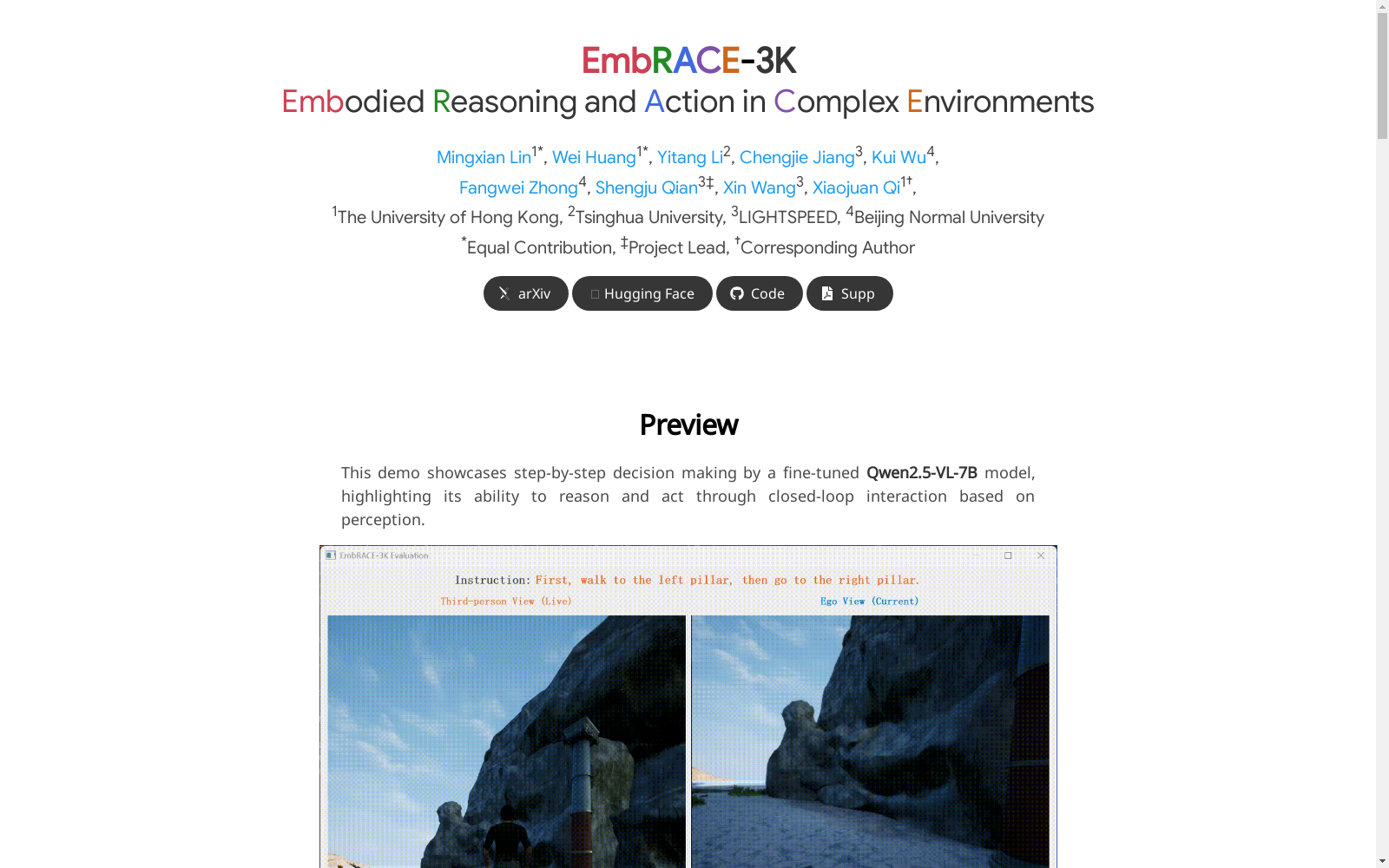
EmbRACE-3K数据集是一个由香港大学、清华大学、LIGHTSPEED和北京师范大学联合创建的,包含超过3000个语言引导的任务,这些任务设置在多样化的、逼真的环境中,使用Unreal Engine和UnrealCV-Zoo框架构建。数据集包含大约26000个决策步骤,每个步骤都标注有自上而下的视觉观察、选择的动作和自然语言的“思考”理由,解释了代理在每个步骤中的意图。这个设计导致了细粒度、时间上与决策紧密对齐的注释。EmbRACE-3K旨在评估VLMs(视觉语言模型)在探索、动态空间-语义推理和多阶段目标执行三个关键维度上的具身推理能力。
The EmbRACE-3K dataset was jointly created by The University of Hong Kong, Tsinghua University, LIGHTSPEED, and Beijing Normal University. It comprises over 3,000 language-guided tasks constructed in diverse and realistic environments using the Unreal Engine and UnrealCV-Zoo frameworks. The dataset contains approximately 26,000 decision steps, each annotated with top-down visual observations, selected actions, and natural language "thinking" justifications that explain the agent's intent at every step. This design results in fine-grained annotations tightly temporally aligned with the decisions. The EmbRACE-3K dataset aims to evaluate the embodied reasoning capabilities of VLMs (Vision-Language Models) across three critical dimensions: exploration, dynamic spatial-semantic reasoning, and multi-stage goal execution.
提供机构:
香港大学, 清华大学, LIGHTSPEED, 北京师范大学
创建时间:
2025-07-15
原始信息汇总
EmbRACE-3K 数据集概述
基本信息
- 数据集名称: EmbRACE-3K
- 研究领域: 具身推理与复杂环境中的行动
- 开发团队:
- 香港大学、清华大学、LIGHTSPEED、北京师范大学
- 同等贡献者: Mingxian Lin, Wei Huang
- 项目负责人: Shengju Qian
- 通讯作者: Xiaojuan Qi
数据集简介
- 核心内容: 包含3,100个语言引导任务和26,000个决策步骤
- 任务特点:
- 多样化虚拟环境中的多阶段任务
- 需要感知、推理和行动的闭环交互
- 基准测试: 评估视觉语言模型在探索、动态空间语义推理和多阶段目标执行三个核心技能上的表现
数据构成
- 任务类型: 6种具身任务类型
- Basic
- Dynamic Spatial-Semantic
- Exploration
- Interaction
- Open-Door
- Pick-and-Drop
- 数据元素 (每个步骤包含):
- 指令
- 自我中心视角图像
- 思考过程
- 行动
数据收集方法
- 在虚拟环境中采样6自由度智能体位姿
- 使用Gemini生成基于场景的任务指令
- 收集人类示范数据
- 为每个动作标注自然语言推理说明
基准测试结果
- 测试模型:
- GPT-4o
- Gemini 2.5 Pro
- Qwen2.5-VL 7B (原始版)
- Qwen2.5-VL 7B (SFT + RL版)
- 零样本测试表现: 所有模型成功率低于20%
- 微调效果: Qwen2.5-VL-7B经过监督学习和强化学习微调后,在所有任务类型上均取得一致提升
引用信息
bibtex @article{lin2025embrace3k, title={EmbRACE-3K: Embodied Reasoning and Action in Complex Environments}, author={Lin, Mingxian and Huang, Wei and Li, Yitang and Jiang, Chengjie and Wu, Kui and Zhong, Fangwei and Qian, Shengju and Wang, Xin and Qi, Xiaojuan}, journal={arXiv preprint arXiv:2507.10548}, year={2025} }
联系方式
- 联系邮箱: lmx.mingxian@gmail.com
搜集汇总
数据集介绍
构建方式
EmbRACE-3K数据集的构建采用了多阶段、系统化的方法,旨在捕捉具身智能体在复杂环境中的感知-推理-行动闭环。研究团队基于Unreal Engine和UnrealCV-Zoo框架,从24个高保真虚拟环境中采集数据,涵盖室内外多样化场景。构建过程分为四个关键阶段:首先通过混合策略采样6自由度智能体位姿;接着利用Gemini 2.5 Pro生成空间语义 grounded 的任务指令;然后由人类操作者进行实时演示并记录第一人称轨迹;最后为每个决策步骤标注包含行动意图的自然语言推理链。这种构建方法产生了3,000余个语言引导任务和26,000个决策步骤,每个步骤都包含视觉观察、具体行动和思维过程的三元组标注。
特点
EmbRACE-3K的核心特征体现在其时空连续性和认知深度上。数据集突破了传统被动视觉基准的局限,通过第一人称视角的闭环交互设计,完整保留了行动对后续观察的动态影响。其独特价值在于细粒度的思维过程标注,每个行动决策都配有自然语言解释,形成了可解释的长时程决策链条。数据覆盖五大任务类型(基础导航、主动探索、动态空间推理、多阶段目标、物体交互),特别强调相对空间关系理解和目标持久性跟踪。相较于ALFRED等静态轨迹数据集,EmbRACE-3K的在线交互特性支持对部分可观测条件下时空推理能力的严格评估。
使用方法
该数据集支持两种主要应用范式:基准评估与模型训练。在评估层面,研究者可通过零样本测试衡量模型在探索能力、动态空间推理和多阶段目标执行三个维度的表现,使用成功率(SR)、目标距离误差(GDE)等五项指标进行量化分析。训练应用推荐采用两阶段策略:先利用2,344条标注轨迹进行监督微调(SFT),重点学习视觉场景理解与思维链生成;再通过基于规则的强化学习(GRPO算法)优化长程决策能力,其中动作格式正确性和任务完成度构成复合奖励信号。实验表明,这种训练方案能使Qwen2.5-VL-7B在未知环境中的探索任务成功率提升30个百分点,验证了数据集对具身推理能力培养的有效性。
背景与挑战
背景概述
EmbRACE-3K数据集由香港大学、清华大学、LIGHTSPEED和北京师范大学的研究团队于2025年联合推出,旨在解决视觉语言模型(VLMs)在具身智能环境中的局限性。该数据集包含3,000多个语言引导的任务,覆盖导航、物体操作和多阶段目标执行等复杂场景,构建于Unreal Engine和UnrealCV-Zoo框架下的高仿真环境中。通过26,000个决策步骤的细粒度标注,包括第一人称视觉观察、高层指令和自然语言推理,EmbRACE-3K推动了感知与决策的紧密对齐,为具身推理研究提供了重要基准。
当前挑战
EmbRACE-3K面临的挑战主要体现在两方面:领域问题方面,现有VLMs在动态空间语义推理、长时程规划和目标持久性等具身任务中表现不足,零样本成功率低于20%;数据构建方面,需克服多模态对齐的复杂性(如视觉观察与语言指令的时序绑定)、高仿真环境中的交互闭环设计,以及确保26,000个决策步骤中行动与推理标注的因果一致性。这些挑战凸显了从静态视觉理解到在线交互决策的范式转换难度。
常用场景
经典使用场景
EmbRACE-3K数据集在具身智能领域的研究中扮演着关键角色,其经典使用场景主要集中在多模态语言模型(VLMs)的在线交互与动态场景理解能力评估。该数据集通过构建3000余项语言引导任务,覆盖导航、物体操控及多阶段目标执行等复杂场景,为研究者提供了丰富的第一视角视觉观察与动作序列数据。每个任务步骤均配有自然语言推理标注,使得模型能够学习感知与决策的精细对齐,特别适合用于验证智能体在部分可观测环境中的时空推理与长程规划能力。
衍生相关工作
该数据集已衍生出多项具身推理领域的创新研究,例如基于GRPO强化学习框架的决策优化方法,以及融合链式思维(CoT)标注的监督微调策略。相关工作在ALFRED、Octopus等传统基准上实现了性能突破,特别是在多阶段任务执行方面,Qwen2.5-VL-7B模型的成功率从原始26.4%提升至81.8%。这些进展为构建具有持续学习能力的具身智能体奠定了方法论基础。
数据集最近研究
最新研究方向
EmbRACE-3K数据集作为首个专注于具身推理与复杂环境交互的多模态基准,正推动视觉语言模型在动态空间语义理解、长程目标规划等前沿方向的发展。其通过虚幻引擎构建的26,000步决策轨迹与逐步推理标注,为模型训练提供了感知-决策闭环的细粒度监督,显著提升了GPT-4o等模型在开放环境中的探索成功率(提升300%)和空间关系推理准确率。该数据集通过强化学习框架实现了Qwen2.5-VL-7B在跨场景任务中的泛化能力突破,为解决具身智能中的目标遗忘、视角漂移等核心挑战提供了新的研究范式。
相关研究论文
- 1EmbRACE-3K: Embodied Reasoning and Action in Complex Environments香港大学, 清华大学, LIGHTSPEED, 北京师范大学 · 2025年
以上内容由遇见数据集搜集并总结生成


