【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
Zyda
收藏arXiv2024-06-04 更新2024-06-21 收录
下载链接:
https://huggingface.co/datasets/Zyphra/Zyda
下载链接
链接失效反馈官方服务:
资源简介:
Zyda是由Zyphra创建的一个包含1.3万亿tokens的大型语言模型预训练数据集。该数据集整合了多个高质量的开源数据集,通过严格的过滤和去重过程,确保数据质量。Zyda不仅在性能上超越了其他开源数据集,如Dolma和RefinedWeb,还显著提高了Pythia系列模型的表现。数据集的创建过程包括综合多个数据源、应用先进的过滤和去重技术。Zyda的应用领域广泛,主要用于提升大型语言模型的训练效果,解决模型在资源分配和性能优化方面的问题。
Zyda is a large language model pre-training dataset with 1.3 trillion tokens, developed by Zyphra. This dataset integrates multiple high-quality open-source datasets, and employs strict filtering and deduplication procedures to guarantee data quality. Zyda not only outperforms other open-source datasets such as Dolma and RefinedWeb, but also significantly boosts the performance of the Pythia series of models. The creation process of Zyda involves integrating multiple data sources and applying advanced filtering and deduplication technologies. The dataset has a wide range of application scenarios, and is primarily used to enhance the training efficacy of large language models and resolve issues concerning model resource allocation and performance optimization.
提供机构:
Zyphra
创建时间:
2024-06-04
搜集汇总
数据集介绍
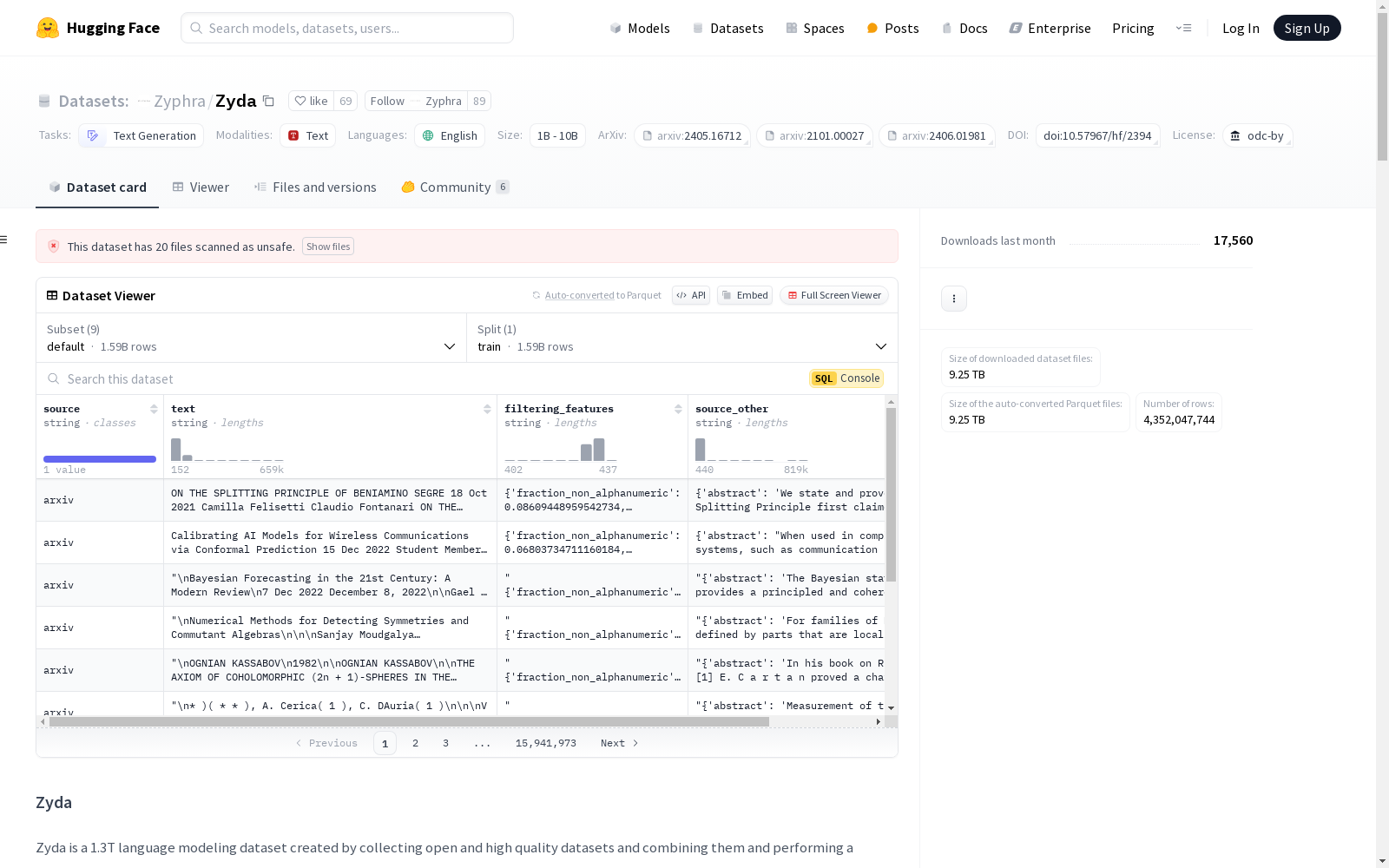
构建方式
Zyda数据集的构建过程融合了多个高质量的开源数据集,通过严格的筛选和去重步骤,形成了一个包含1.3万亿标记的综合语料库。构建过程中,首先整合了包括The Pile、SlimPajama、RefinedWeb等在内的主要开源数据集,随后应用了复杂的过滤和去重流程,确保数据质量的提升。这些步骤包括对数据集内部的重复数据进行去重,以及跨数据集的重复数据检测,从而有效减少了数据冗余,提升了整体数据集的质量。
特点
Zyda数据集的主要特点在于其大规模和高品质。该数据集包含1.3万亿标记,远超许多现有的开源数据集。通过严格的过滤和去重处理,Zyda在保持数据多样性的同时,显著提升了数据质量。此外,Zyda的构建过程公开透明,所有处理代码均开源,便于学术界和工业界的研究人员进行验证和进一步优化。
使用方法
Zyda数据集适用于大规模语言模型的预训练。研究人员和开发者可以通过Hugging Face平台访问该数据集,并利用其进行模型训练。使用时,建议结合数据集的构建说明和处理代码,确保数据的有效利用。此外,由于数据集的高质量和大规模特性,Zyda特别适合用于需要大量高质量文本数据的任务,如自然语言理解、生成和对话系统等。
背景与挑战
背景概述
随着大型语言模型(LLMs)规模的迅速扩展,其计算和数据需求也相应激增。当前最先进的语言模型,即使在相对较小的规模下,通常也需要在至少一万亿个标记上进行训练。这种快速进步已经超过了开源数据集的增长。在此背景下,我们引入了Zyda(Zyphra数据集),这是一个包含1.3万亿个标记的数据集,通过整合多个备受尊重的开源数据集构建而成。我们应用了严格的过滤和去重过程,以保持和提升原始数据集的质量。评估显示,Zyda不仅在其他开源数据集如Dolma、FineWeb和RefinedWeb中表现出色,而且显著提升了Pythia套件中类似模型的性能。我们的严格数据处理方法显著增强了Zyda的有效性,即使独立使用,也能超越其组成数据集中的最佳表现。
当前挑战
构建Zyda数据集面临的主要挑战包括:1) 整合多个高质量的开源数据集,确保数据的一致性和质量;2) 实施严格的过滤和去重过程,以消除低质量数据和重复内容;3) 在数据处理过程中保持高效率,以应对万亿级标记的庞大规模。此外,确保数据集的开放性和可访问性,以便研究人员和开发者能够充分利用这一资源,也是一个重要的挑战。
常用场景
经典使用场景
Zyda数据集在开放语言模型训练中展现了其经典应用场景,通过整合多个高质量的开源数据集,Zyda提供了1.3万亿个标记,适用于大规模语言模型的预训练。其严格的过滤和去重过程确保了数据集的高质量和有效性,使得模型在语言建模任务中表现优异,特别是在Pythia套件中的模型性能提升显著。
衍生相关工作
Zyda数据集的发布催生了一系列相关研究工作,特别是在数据集处理和模型训练优化方面。例如,基于Zyda的预训练模型在多个基准测试中表现优异,推动了开源语言模型的发展。此外,Zyda的成功也激发了对数据集质量和去重技术的进一步研究,如语义聚类和数据集扩展等方向的研究,为未来的语言模型训练提供了新的思路和方法。
数据集最近研究
最新研究方向
在大型语言模型(LLMs)领域,Zyda数据集的最新研究方向主要集中在数据质量和规模的提升上。随着LLMs的计算和数据需求激增,现有开源数据集在规模和质量上逐渐滞后。Zyda数据集通过整合多个高质量的开源数据集,并应用严格的过滤和去重流程,显著提升了数据集的质量和规模。研究显示,Zyda不仅在性能上优于其他开源数据集,如Dolma、FineWeb和RefinedWeb,还能显著提升Pythia系列模型的表现。此外,Zyda的严格数据处理方法使其在独立使用时也能超越其构成数据集的最佳表现。这一研究方向对于推动开源LLMs的发展具有重要意义,尤其是在数据集标准化和公平比较不同架构和训练方法方面。
相关研究论文
- 1Zyda: A 1.3T Dataset for Open Language ModelingZyphra · 2024年
以上内容由遇见数据集搜集并总结生成


