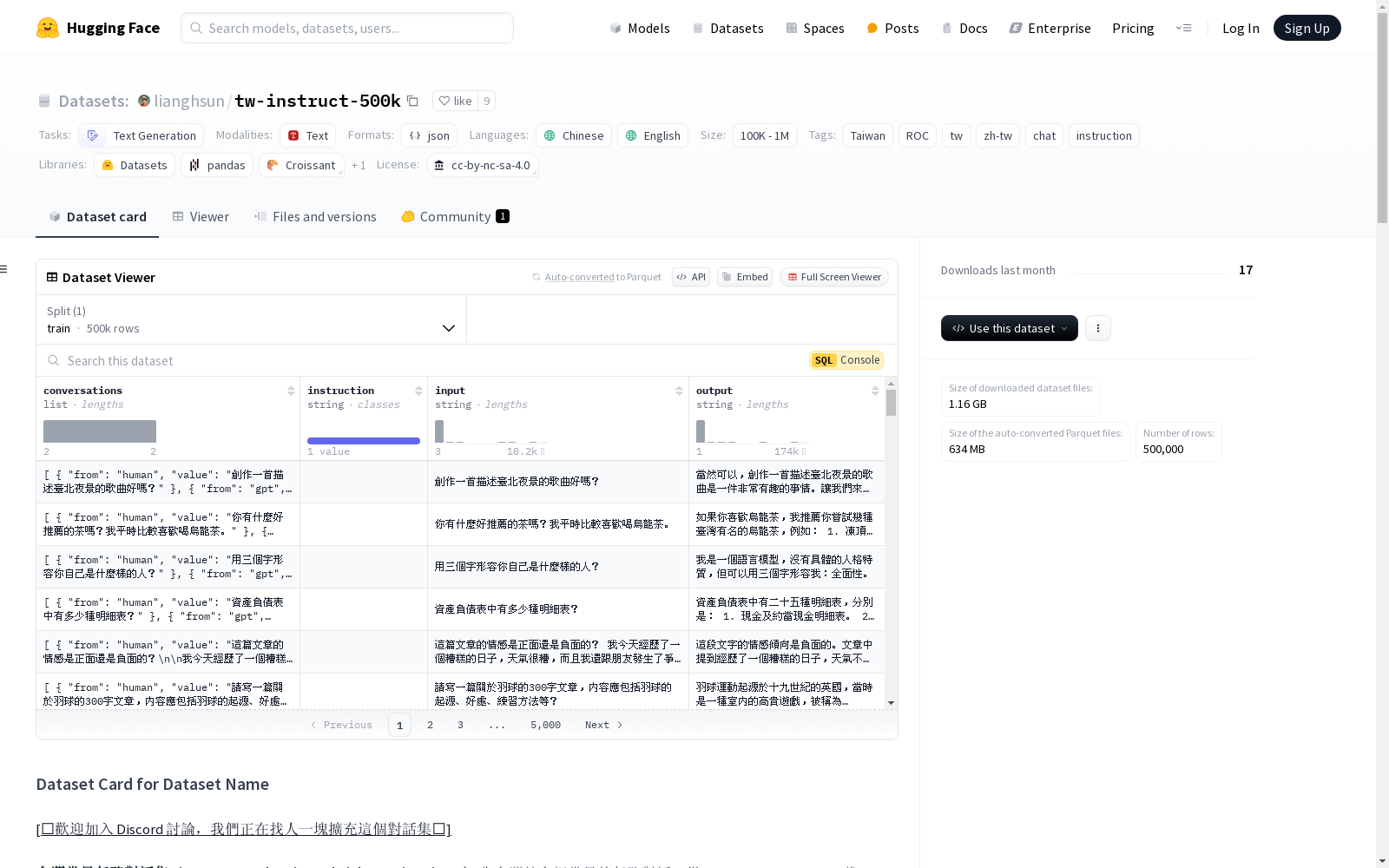
tw-instruct-500k
收藏Hugging Face2025-01-10 更新2025-01-11 收录
下载链接:
https://huggingface.co/datasets/lianghsun/tw-instruct-500k
下载链接
链接失效反馈官方服务:
资源简介:
台灣常見任務對話集(Common Task-Oriented Dialogues in Taiwan)是一个包含50万条对话的子集,主要用于训练模型以理解和生成台湾社会中的常见任务对话。数据集由合成数据组成,包括reference-based和reference-free两部分,使用OpenAI GPT-4o或Qwen/Qwen2.5-14B-Instruct生成。数据集的语言主要为繁体中文,适用于训练具有台湾社会背景知识的对话模型。
Common Task-Oriented Dialogues in Taiwan is a subset consisting of 500,000 dialogues, primarily designed for training models to comprehend and generate common task-oriented dialogues within Taiwanese social contexts. The dataset comprises synthetic data split into two categories: reference-based and reference-free, and is generated using OpenAI GPT-4o or Qwen/Qwen2.5-14B-Instruct. The dataset is primarily in Traditional Chinese and is tailored for training dialogue models equipped with Taiwanese social background knowledge.
创建时间:
2025-01-07
搜集汇总
数据集介绍
构建方式
tw-instruct-500k 数据集是一个合成数据集,结合了 reference-based 和 reference-free 两种生成方式。reference-based 部分通过参考训练 Llama-3.2-Taiwan-3B 模型时使用的繁体中文文本,利用大型语言模型(LLM)生成指令对话集,特别针对特定领域的文本设计问题。reference-free 部分则基于常见的种子提示,生成以台湾为背景的对话集。生成过程中使用了 OpenAI GPT-4o 和 Qwen/Qwen2.5-14B-Instruct 等模型,种子提示来源于 Self-Instruct 和 Hugging Face 的开源资源。
特点
该数据集的特点在于其专注于台湾社会的常见任务对话,涵盖了繁体中文的语境和文化背景。通过 reference-based 和 reference-free 的结合,数据集不仅包含广泛的对话场景,还特别设计了与台湾社会相关的特定领域问题。数据集规模适中,包含约 50 万条对话,适合用于训练具有繁体中文对话能力的模型。此外,数据集的格式已针对 LLaMA-Factory 进行了优化,便于直接使用。
使用方法
tw-instruct-500k 数据集主要用于训练具有繁体中文对话能力的模型,特别是针对台湾社会的语境和文化背景。用户可以直接使用该数据集来训练基础模型,使其具备处理台湾常见任务对话的能力。数据集的格式已经针对 LLaMA-Factory 进行了优化,用户可以根据需要选择合适的格式进行训练。此外,数据集还可用于评估模型在台湾社会语境下的表现,帮助开发者优化模型的对话生成能力。
背景与挑战
背景概述
tw-instruct-500k数据集由Huang Liang Hsun于2024年创建,旨在填补繁体中文任务导向对话数据集的空白。该数据集特别针对台湾社会设计,包含50万条合成对话,分为reference-based和reference-free两部分。reference-based部分基于训练Llama-3.2-Taiwan-3B模型时收集的繁体中文文本生成,reference-free部分则通过种子提示生成台湾场景的对话。该数据集的核心研究问题是如何通过大规模合成数据提升模型对台湾社会语境的理解与生成能力。其影响力在于为繁体中文自然语言处理领域提供了高质量、场景化的对话数据,推动了台湾本地化语言模型的发展。
当前挑战
tw-instruct-500k数据集在构建过程中面临多重挑战。首先,繁体中文任务导向对话数据稀缺,且现有数据多未针对台湾社会设计,导致模型训练后缺乏对台湾语境的深入理解。其次,合成数据的生成依赖于大型语言模型(如GPT-4和Qwen2.5-14B-Instruct),可能引入模型本身的偏见或非台湾社会用语,需通过严格过滤确保数据质量。此外,数据集的构建需平衡多样性与真实性,确保生成的对话既涵盖广泛场景,又符合台湾社会的语言习惯与文化背景。这些挑战对数据集的构建与应用提出了高要求。
常用场景
经典使用场景
tw-instruct-500k数据集在自然语言处理领域中的经典使用场景是用于训练和优化基于台湾社会背景的对话生成模型。该数据集通过提供大量台湾地区的任务导向对话,帮助模型更好地理解和生成符合台湾社会文化背景的对话内容。这种场景特别适用于需要处理台湾特定语境和文化的应用,如智能客服、教育辅导和社交互动等。
解决学术问题
tw-instruct-500k数据集解决了在自然语言处理研究中,繁体中文语料库稀缺且缺乏针对台湾社会背景的对话数据的问题。通过提供大量合成且具有台湾特色的对话数据,该数据集为研究者提供了一个宝贵的资源,用于训练和评估模型在台湾语境下的表现。这不仅提升了模型对台湾文化的理解能力,还推动了相关领域的研究进展。
衍生相关工作
tw-instruct-500k数据集衍生了许多相关的研究和应用工作。例如,基于该数据集训练的[lianghsun/Llama-3.2-Taiwan-3B-Instruct](https://huggingface.co/lianghsun/Llama-3.2-Taiwan-3B-Instruct)模型,展示了在台湾语境下的强大对话生成能力。此外,该数据集还激发了更多关于台湾社会文化背景的对话生成研究,推动了自然语言处理领域在特定文化语境下的发展。
以上内容由遇见数据集搜集并总结生成


