Casablanca
收藏Hugging Face2024-11-15 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/UBC-NLP/Casablanca
下载链接
链接失效反馈官方服务:
资源简介:
Casablanca数据集是一个大规模的社区驱动项目,旨在收集和转录多方言阿拉伯语数据集。该数据集涵盖了八个方言:阿尔及利亚语、埃及语、阿联酋语、约旦语、毛里塔尼亚语、摩洛哥语、巴勒斯坦语和也门语。数据集包括转录、性别、方言和代码切换的注释。每个方言的数据集分为验证集和测试集,并提供了示例数量和大小。
The Casablanca Dataset is a large-scale community-driven project dedicated to collecting and transcribing multi-dialect Arabic datasets. It covers eight dialects: Algerian Arabic, Egyptian Arabic, Emirati Arabic, Jordanian Arabic, Mauritanian Arabic, Moroccan Arabic, Palestinian Arabic, and Yemeni Arabic. The dataset includes annotations for transcription, gender, dialect, and code-switching. For each dialect, the dataset is split into a validation set and a test set, with the number of samples and data size provided for each subset.
提供机构:
UBC Deep Learning & NLP Lab
创建时间:
2024-11-12
原始信息汇总
Casablanca 数据集概述
数据集信息
许可证
- 许可证类型: CC BY-NC-ND 4.0
配置信息
Algeria
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 844个样本, 636948361字节
- test: 843个样本, 596602724字节
- 下载大小: 1215310166字节
- 数据集大小: 1233551085字节
Egypt
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 846个样本, 635527273字节
- test: 846个样本, 650820801字节
- 下载大小: 1157255309字节
- 数据集大小: 1286348074字节
Jordan
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 848个样本, 418493582字节
- test: 848个样本, 423762790字节
- 下载大小: 788256254字节
- 数据集大小: 842256372字节
Mauritania
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 953个样本, 624134522字节
- test: 953个样本, 598880731字节
- 下载大小: 1191233989字节
- 数据集大小: 1223015253字节
Morocco
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 1045个样本, 636022167.005字节
- test: 1045个样本, 639302464.46字节
- 下载大小: 1225648114字节
- 数据集大小: 1275324631.4650002字节
Palestine
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 667个样本, 635220732字节
- test: 667个样本, 619623761字节
- 下载大小: 1212707132字节
- 数据集大小: 1254844493字节
UAE
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 813个样本, 648357489字节
- test: 813个样本, 604083281字节
- 下载大小: 1108277578字节
- 数据集大小: 1252440770字节
Yemen
- 特征:
- audio: 音频
- seg_id: 字符串
- transcription: 字符串
- gender: 字符串
- duration: 浮点数
- 分割:
- validation: 803个样本, 656114251字节
- test: 803个样本, 682738357字节
- 下载大小: 1266260015字节
- 数据集大小: 1338852608字节
数据文件
- Algeria:
- validation: Algeria/validation-*
- test: Algeria/test-*
- Egypt:
- validation: Egypt/validation-*
- test: Egypt/test-*
- Jordan:
- validation: Jordan/validation-*
- test: Jordan/test-*
- Mauritania:
- validation: Mauritania/validation-*
- test: Mauritania/test-*
- Morocco:
- validation: Morocco/validation-*
- test: Morocco/test-*
- Palestine:
- validation: Palestine/validation-*
- test: Palestine/test-*
- UAE:
- validation: UAE/validation-*
- test: UAE/test-*
- Yemen:
- validation: Yemen/validation-*
- test: Yemen/test-*
语言
- 阿拉伯语 (ar)
标签
- speech
- arabic
- asr
- speech_recognition
- speech_processing
- dialects
- algeria
- egypt
- jordan
- mauritania
- morocco
- palestine
- uae
- yemen
数据集名称
- casablanca
引用
@article{talafha2024casablanca, title={Casablanca: Data and Models for Multidialectal Arabic Speech Recognition}, author={Talafha, Bashar and Kadaoui, Karima and Magdy, Samar Mohamed and Habiboullah, Mariem and Chafei, Chafei Mohamed and El-Shangiti, Ahmed Oumar and Zayed, Hiba and Alhamouri, Rahaf and Assi, Rwaa and Alraeesi, Aisha and others}, journal={arXiv preprint arXiv:2410.04527}, year={2024} }
搜集汇总
数据集介绍
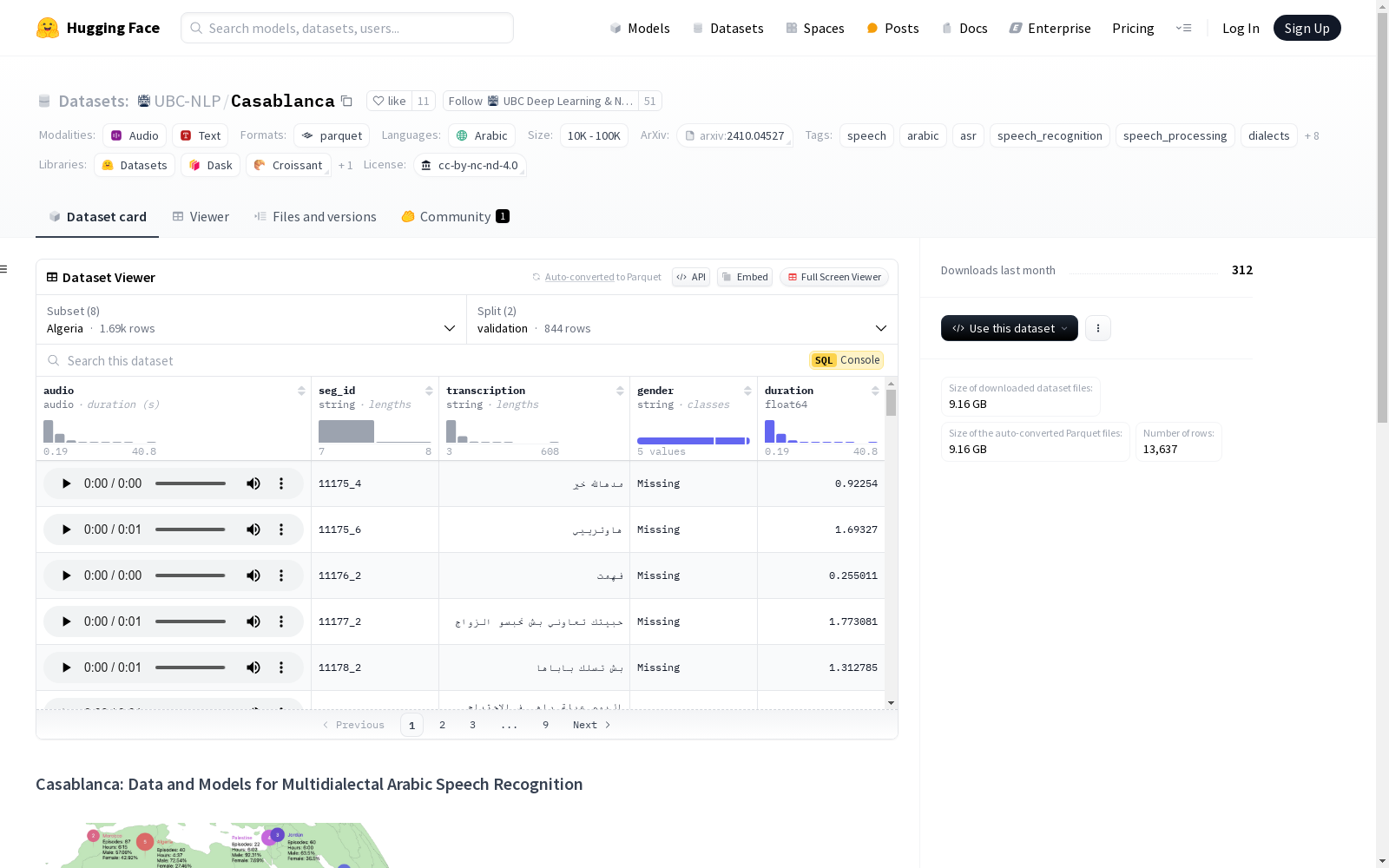
构建方式
Casablanca数据集的构建源于对多方言阿拉伯语语音识别的研究需求。该数据集通过社区驱动的方式,广泛收集了来自阿尔及利亚、埃及、约旦、毛里塔尼亚、摩洛哥、巴勒斯坦、阿联酋和也门等八个地区的阿拉伯语方言语音数据。每个样本均包含音频文件、转录文本、性别信息以及音频时长等详细标注。数据集的构建过程严格遵循科学规范,确保了数据的多样性和代表性,为多方言语音识别研究提供了坚实的基础。
特点
Casablanca数据集的特点在于其覆盖了多种阿拉伯语方言,涵盖了从北非到中东的广泛地理区域。每个方言的语音数据均经过精细的转录和标注,包括性别、方言类型以及代码转换等信息。数据集规模庞大,验证集和测试集分别包含数百至上千个样本,音频总时长达到数千小时。这种多维度、多层次的标注方式为语音识别模型的训练和评估提供了丰富的上下文信息,显著提升了模型的泛化能力。
使用方法
Casablanca数据集的使用方法主要围绕多方言阿拉伯语语音识别任务展开。研究人员可以通过加载数据集中的音频文件和对应的转录文本,构建和训练语音识别模型。数据集提供了验证集和测试集,便于模型性能的评估和比较。此外,数据集中的性别和方言标签可用于研究语音识别模型在不同人群和方言中的表现差异。通过结合这些标注信息,研究人员可以进一步探索多方言语音识别中的挑战与解决方案,推动该领域的技术进步。
背景与挑战
背景概述
Casablanca数据集由Bashar Talafha等人于2024年提出,旨在解决阿拉伯语多方言语音识别领域的数据稀缺问题。该数据集涵盖了阿尔及利亚、埃及、约旦、毛里塔尼亚、摩洛哥、巴勒斯坦、阿联酋和也门等八个阿拉伯方言,包含音频、转录文本、性别和时长等多维度标注信息。Casablanca的发布标志着阿拉伯语语音处理领域的一个重要里程碑,为多方言语音识别系统的开发提供了丰富的数据支持,推动了语音技术在阿拉伯语社区的应用与普及。
当前挑战
Casablanca数据集在构建过程中面临多重挑战。阿拉伯语方言的多样性使得数据收集和标注变得复杂,不同方言之间的语音特征和词汇差异显著,增加了数据一致性和准确性的难度。数据集的规模和质量要求高,需要大量的语音样本和精确的转录文本,这对数据采集和标注团队提出了极高的要求。此外,方言间的代码转换现象进一步增加了数据处理的复杂性,如何有效捕捉和处理这些现象成为数据集构建中的一大难题。
常用场景
经典使用场景
Casablanca数据集在阿拉伯语多方言语音识别领域具有广泛的应用。其经典使用场景包括训练和评估多方言阿拉伯语自动语音识别(ASR)系统。通过涵盖阿尔及利亚、埃及、约旦、毛里塔尼亚、摩洛哥、巴勒斯坦、阿联酋和也门等八种方言的语音数据,Casablanca为研究人员提供了一个全面的基准,用于测试和优化ASR模型在不同方言环境下的表现。
衍生相关工作
Casablanca数据集衍生了许多相关经典工作,特别是在多方言语音识别和语音处理领域。基于该数据集,研究人员开发了多种先进的ASR模型,这些模型在处理不同方言时表现出色。此外,Casablanca还激发了关于方言识别、语音合成和语音增强等领域的研究,推动了阿拉伯语语音处理技术的全面发展。这些工作不仅提升了多方言语音识别的准确性,还为其他低资源语言的语音处理研究提供了宝贵的参考。
数据集最近研究
最新研究方向
在语音处理领域,阿拉伯语多方言识别一直是一个具有挑战性的研究方向。Casablanca数据集的推出为这一领域注入了新的活力,其覆盖了阿尔及利亚、埃及、约旦、毛里塔尼亚、摩洛哥、巴勒斯坦、阿联酋和也门等八种阿拉伯方言,并提供了转录、性别、方言和代码转换等多维度标注。这一数据集不仅填补了多方言阿拉伯语语音数据的空白,还为开发更精准的语音识别模型提供了坚实的基础。近年来,基于Casablanca的研究主要集中在多方言语音识别模型的优化、方言间差异的量化分析以及代码转换现象的深入研究。这些研究不仅推动了阿拉伯语语音处理技术的发展,也为全球多语言语音识别系统的构建提供了宝贵的经验和数据支持。Casablanca的发布标志着阿拉伯语多方言语音识别研究进入了一个新的阶段,其影响将深远地推动语音技术的普及与包容性发展。
以上内容由遇见数据集搜集并总结生成


