CSVQA
收藏arXiv2025-05-30 更新2025-06-03 收录
下载链接:
https://huggingface.co/datasets/Skywork/CSVQA
下载链接
链接失效反馈官方服务:
资源简介:
CSVQA是一个专门用于评估视觉语言模型(VLMs)科学推理能力的中文学科STEM多模态基准。它包含1,378个精心构建的问题-答案对,涵盖了STEM领域的多个学科,每个问题都需要领域知识、视觉证据的整合和高阶推理。与现有的多模态基准相比,CSVQA更强调现实世界的科学内容和复杂的推理。CSVQA数据集来源于中国高中STEM学科的公开教材和试卷,经过严格的筛选和注释,旨在为VLMs提供一个更具挑战性的评估框架。
CSVQA is a Chinese-language STEM multimodal benchmark specifically designed to evaluate the scientific reasoning capabilities of Vision-Language Models (VLMs). It comprises 1,378 carefully constructed question-answer pairs spanning multiple STEM disciplines, where each question requires the integration of domain knowledge, visual evidence, and high-order reasoning. Compared with existing multimodal benchmarks, CSVQA places greater emphasis on real-world scientific content and complex reasoning. Derived from publicly available high school STEM textbooks and examination papers in China, CSVQA has undergone rigorous screening and annotation, aiming to provide a more challenging evaluation framework for VLMs.
提供机构:
昆仑科技
创建时间:
2025-05-30
原始信息汇总
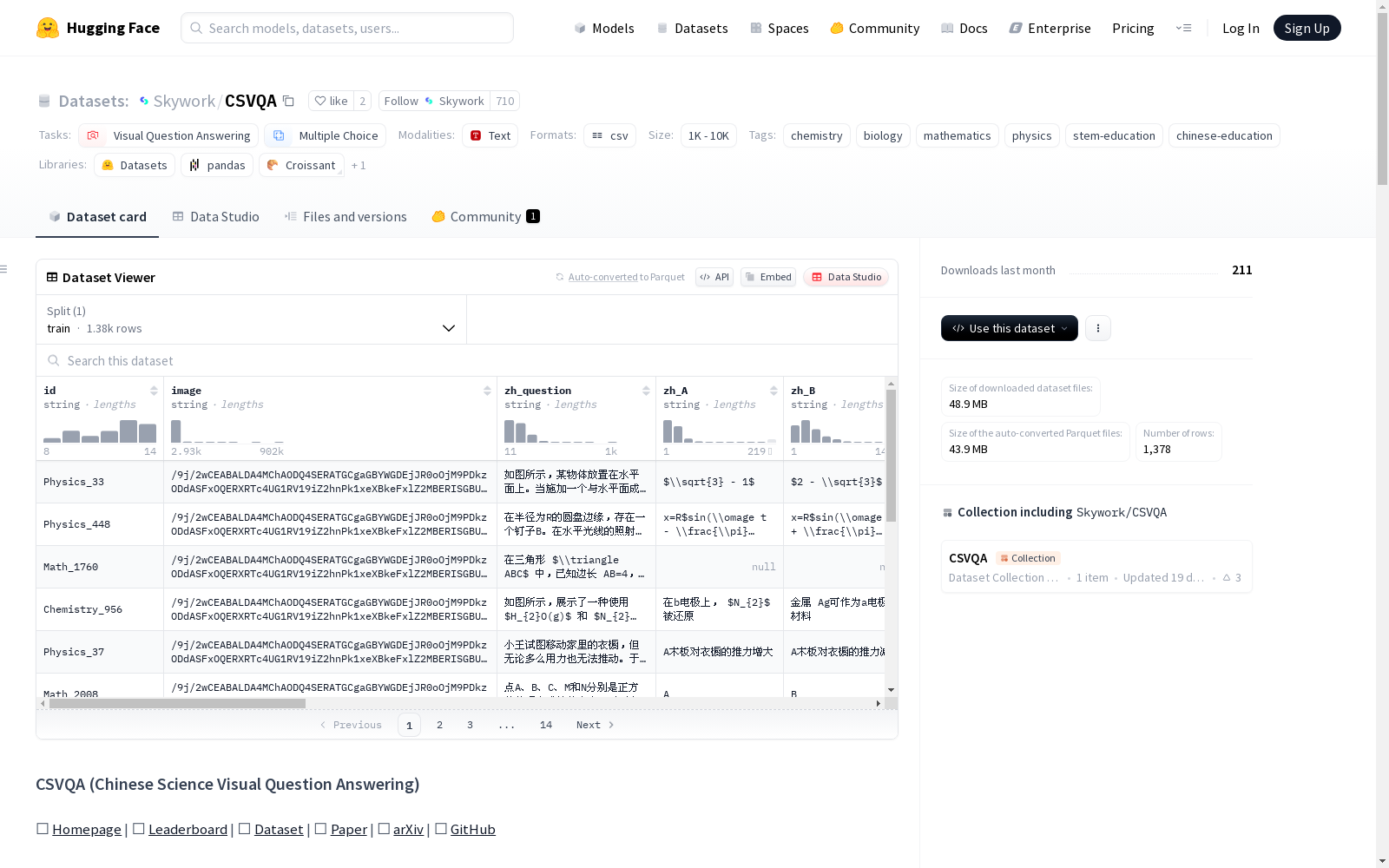
CSVQA 数据集概述
数据集基本信息
- 任务类别: 视觉问答、多选题
- 标签: 化学、生物、数学、物理、STEM教育、中文教育
- 规模: 10M < n < 100M
数据集简介
CSVQA(Chinese Science Visual Question Answering)是一个用于评估科学推理能力的多模态基准数据集,专注于中文科学视觉问答。该数据集填补了现有基准在科学语境评估上的不足,强调领域特定知识与视觉证据分析的结合。
数据集特点
- 问题数量: 1,378个精心构建的问答对
- 覆盖学科: 多样化的STEM学科
- 核心要求: 领域知识、视觉证据整合、高阶推理
数据集构成
| 项目 | 数量/比例 |
|---|---|
| 总问题数 | 1,378 |
| 图像类型 | 14 |
| 难度分布 (易:中:难) | 22.6% : 67.4% : 10.0% |
| 多选题 | 1,278 |
| 开放性问题 | 100 |
| 含解释的问题 | 81.1% |
| 问题中含图像 | 1,341 |
| 选项中含图像 | 37 |
| 平均问题长度 | 69.7 |
| 平均选项长度 | 12.1 |
| 平均解释长度 | 123.5 |
主要挑战
- 多学科覆盖: 需要跨学科知识和多样化的推理策略
- 视觉模态多样性: 包含14种不同的视觉模态
- 真实世界情境化: 基于真实STEM场景,要求超越模式识别的能力
排行榜表现
- 开源模型最佳表现: InternVL3-78B (37.4%总体准确率)
- 闭源模型最佳表现: o1 (49.6%总体准确率)
局限性
- 学科覆盖: 目前仅包含高中科学内容
- 数据分布分析: 仍在进行详细的学科和问题类型分布分析
- 标注噪声: 可能存在OCR识别错误或不完整解析
联系方式
- shawn0wang76031@gmail.com
- jianai@bupt.edu.cn
搜集汇总
数据集介绍
构建方式
CSVQA数据集的构建采用了严谨的四阶段质量控制流程,首先从中国高中STEM教材和考试材料中收集原始数据,通过OCR技术提取文本和视觉信息;随后利用DeepSeekV3驱动的自动化对齐管道建立语义关联;再经人工筛选处理复杂案例;最终经过三轮独立评审(模式验证、完整性检查、学科专家审核)形成包含1,378个问题的精校数据集。该过程从10万原始条目中筛选,保留了需要视觉推理的优质多模态项目,并特别构建了基于难度评分和视觉依赖性的CSVQA-Hard挑战子集。
特点
作为首个专注于中文STEM领域多模态推理的基准测试,CSVQA具有三个显著特征:跨学科覆盖性(物理、化学、生物、数学四大学科)、多模态复杂性(包含14类科学视觉模态)、以及真实场景关联性(81%的问题配有详细解题步骤)。其问题平均长度达69.7词,远超过往基准,且采用双语设计(中英文问题对),在保持文化真实性的同时支持更广泛的测试场景。特别设计的开放式问题和多选题两种形式,可全面评估模型在自由生成和精确判别方面的能力。
使用方法
使用CSVQA时建议采用分层评估策略:基础层测试模型对文本密集图像(如流程图)和结构化图像的理解;进阶层评估跨模态推理能力,需结合领域知识分析视觉证据;高级层通过CSVQA-Hard子集检验复杂科学概念的推理深度。评估时可采用思维链(CoT)提示策略,并建议配套使用论文提出的过程追踪实验方法,通过比对模型生成的解题步骤与人工标注的标准解释,区分真实推理与随机猜测。数据集支持端到端评估和分模块诊断,便于定位模型在感知、知识整合或逻辑推理等环节的缺陷。
背景与挑战
背景概述
CSVQA是由Skywork AI和Kunlun Inc.的研究团队于2025年推出的一个中文多模态基准测试数据集,旨在评估视觉语言模型(VLMs)在科学、技术、工程和数学(STEM)领域的推理能力。该数据集包含1,378个经过精心构建的问题-答案对,覆盖多个STEM学科,每个问题都需要领域知识、视觉证据分析和高级推理能力。CSVQA的推出填补了当前多模态基准测试在科学推理评估方面的空白,为相关领域的研究提供了重要的评估工具。
当前挑战
CSVQA面临的挑战主要包括两个方面:一是领域问题的挑战,即如何准确评估VLMs在复杂科学推理任务中的表现,特别是在需要跨学科知识和视觉理解的场景下;二是构建过程中的挑战,包括如何从真实教学材料中提取高质量的多模态数据,确保问题的多样性和难度平衡,以及如何设计有效的评估协议来验证模型的中间推理步骤。这些挑战使得CSVQA成为一个具有高度复杂性和严格要求的基准测试。
常用场景
经典使用场景
CSVQA数据集作为首个专注于中文STEM领域多模态推理的基准测试,其经典使用场景在于系统评估视觉语言模型(VLMs)在跨学科科学问题中的深度理解与推理能力。该数据集通过1,378个涵盖物理、化学、生物和数学的视觉问答对,要求模型结合领域知识、视觉证据分析与高阶推理,典型应用包括模型在解析实验流程图、化学分子结构、数学几何图形等14类科学图像时的多模态对齐能力测试。
实际应用
该数据集在教育科技领域具有重要实践价值,可应用于智能辅导系统的能力评测。例如在虚拟实验室场景中,模型需根据学生提交的化学反应图像推断实验现象,或通过物理力学图示解答运动轨迹问题。其包含的详细解题步骤(81.1%问题含人工标注解释)也为构建可解释性AI教学助手提供了训练范本,推动自适应学习系统中视觉-语言协同推理技术的发展。
衍生相关工作
CSVQA的发布催生了一系列改进科学推理的VLMs研究工作。基于其构建的CSVQA-Hard子集,研究者开发了针对物理抽象符号的专用编码器(如InternVL3的变体视觉专家模块)。该数据集还启发了类似MathVista的中文数学视觉基准MathVision,以及跨模态思维链验证框架EMMA的优化,这些工作均引用CSVQA作为多模态科学推理的金标准测试环境。
以上内容由遇见数据集搜集并总结生成


