有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
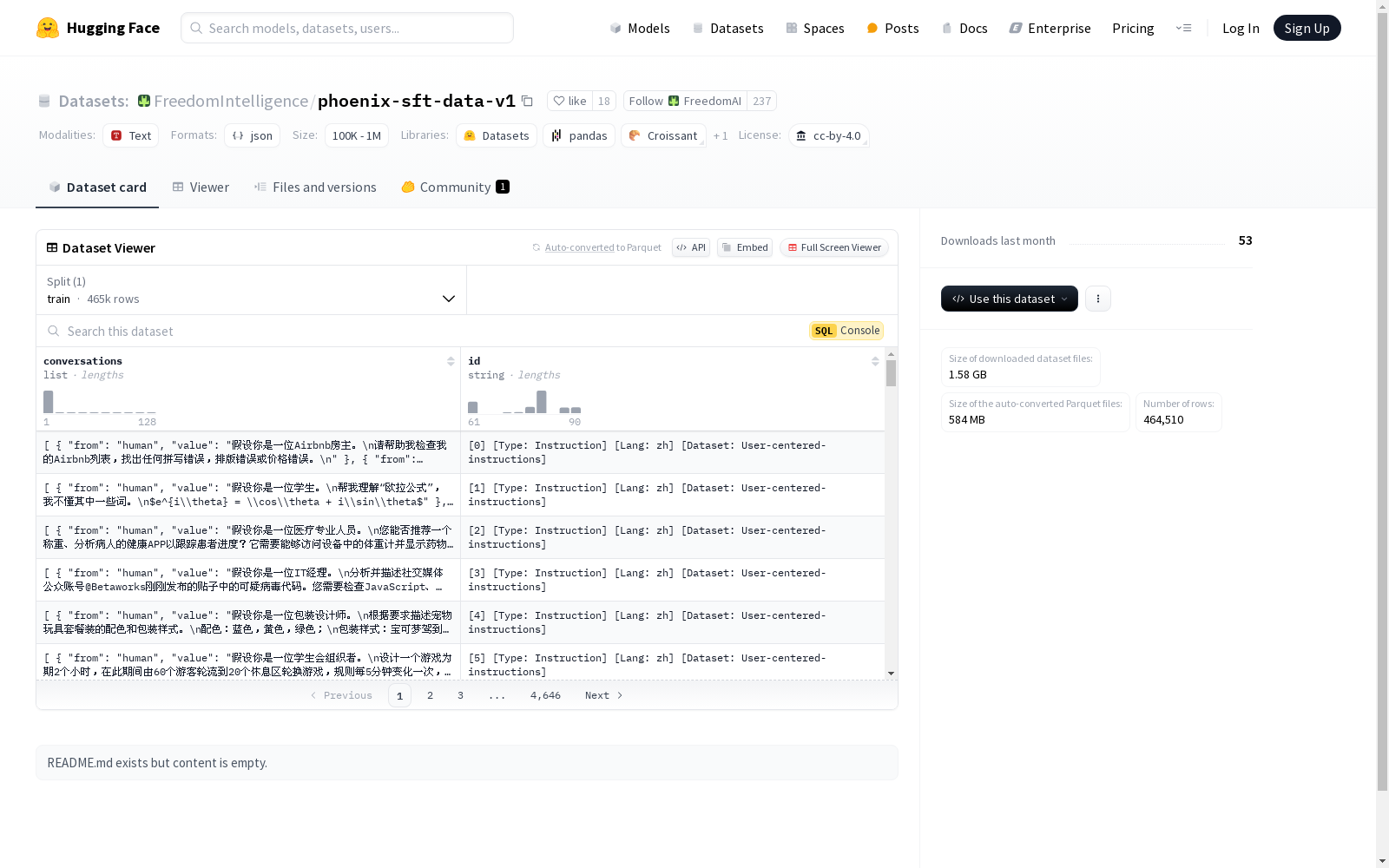
phoenix-sft-data-v1
cc-by-4.0
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
CE-CSL
CE-CSL数据集是由哈尔滨工程大学智能科学与工程学院创建的中文连续手语数据集,旨在解决现有数据集在复杂环境下的局限性。该数据集包含5,988个从日常生活场景中收集的连续手语视频片段,涵盖超过70种不同的复杂背景,确保了数据集的代表性和泛化能力。数据集的创建过程严格遵循实际应用导向,通过收集大量真实场景下的手语视频材料,覆盖了广泛的情境变化和环境复杂性。CE-CSL数据集主要应用于连续手语识别领域,旨在提高手语识别技术在复杂环境中的准确性和效率,促进聋人与听人社区之间的无障碍沟通。
arXiv 收录
DAT
DAT是一个统一的跨场景跨领域基准,用于开放世界无人机主动跟踪。它提供了24个视觉复杂的场景,以评估算法的跨场景和跨领域泛化能力,并具有高保真度的现实机器人动力学建模。
github 收录
专精特新“小巨人”合肥企业名单(第一批~第四批)
根据工信部的定义,专精特新“小巨人”企业是“专精特新”中小企业中的佼佼者,是专注于细分市场、创新能力强、市场占有率高、掌握关键核心技术、质量效益优的排头兵企业。 截止第四批,目前,全市“小巨人”企业总数达140户,占全国的1.6%,在全国城市及省会城市排名各进一位,位居全国城市第十四,省会城市第五。 2022 年 6 月,合肥市发布《专精特新中小企业倍增培育行动计划》,到2025年,合肥计划培育省级专精特新冠军企业和国家级专精特新“小巨人”企业300家,推动50家专精特新中小企业上市挂牌。接下来,合肥还将支持地方国有金融机构设立专精特新专项融资产品,力争每条产业链培育一批国家级专精特新“小巨人”企业。
合肥数据要素流通平台 收录
HIT-UAV
HIT-UAV数据集包含2898张红外热成像图像,这些图像从43,470帧无人机拍摄的画面中提取。数据集涵盖了多种场景,如学校、停车场、道路和游乐场,在不同的光照条件下,包括白天和夜晚。
github 收录