OAS95-aligned-cleaned
收藏Hugging Face2026-03-30 更新2026-03-31 收录
下载链接:
https://huggingface.co/datasets/OASfiltered/OAS95-aligned-cleaned
下载链接
链接失效反馈官方服务:
资源简介:
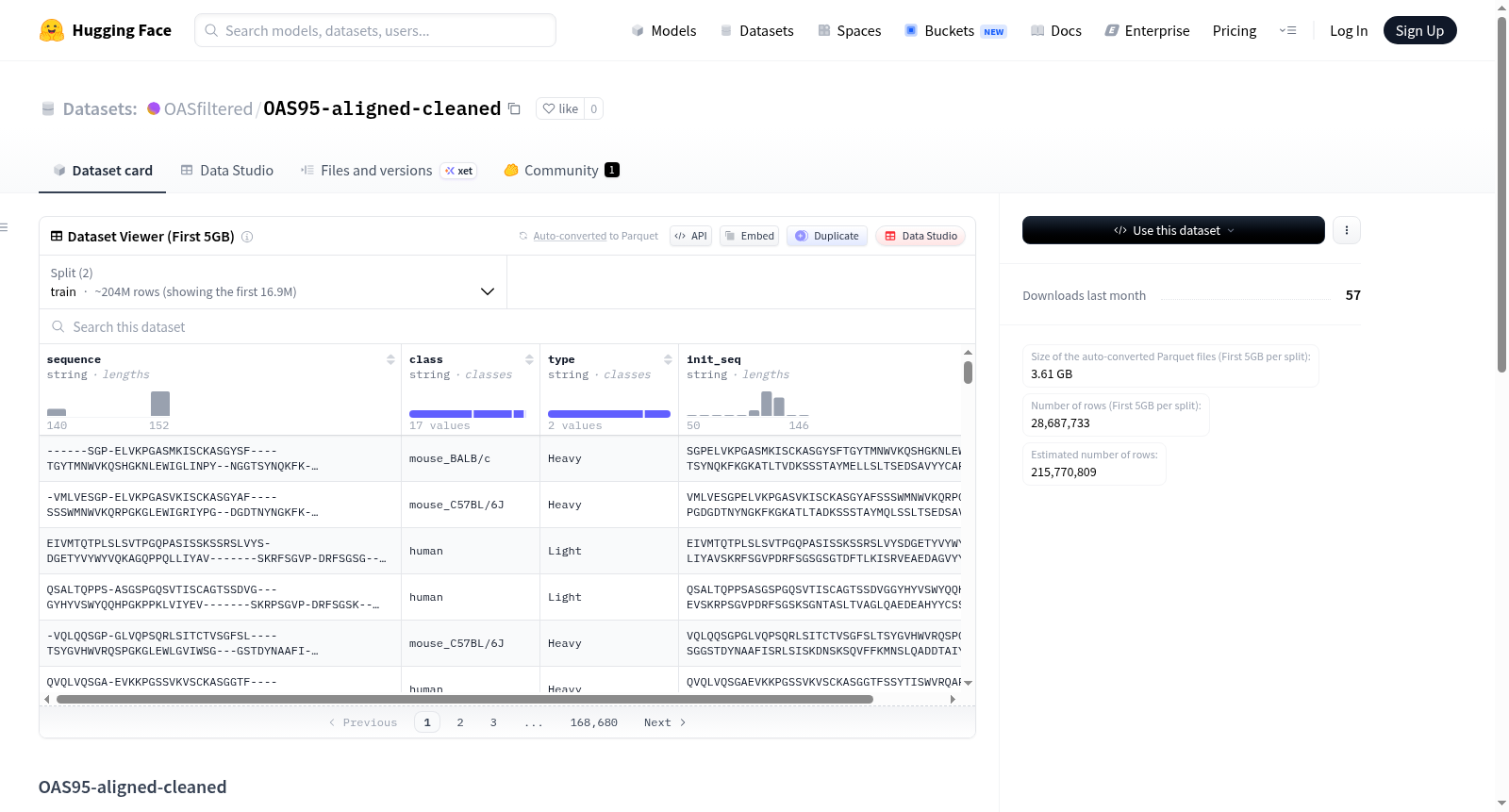
OAS95-aligned-cleaned 是一个经过清洗和 IMGT 对齐的抗体序列数据集,源自 Observed Antibody Space (OAS) 数据库。数据集通过 IgLM 管道预处理,并以 95% 的序列同一性进行聚类。所有序列均使用 ANARCII 按照 IMGT 编号方案进行编号。数据集移除了在第一框架位置有编号缺口的重链和轻链序列,以及长度小于 90 个残基的轻链序列。最终数据集包含 203,968,932 条训练序列和 11,819,793 条测试序列,覆盖 6 个生物体标签和 2 种链类型(重链和轻链)。数据集的字段包括:sequence(带有间隔字符的 IMGT 对齐氨基酸序列)、init_seq(无对齐间隔的原始氨基酸序列)、class(生物体标签)和 type(抗体链类型)。数据集适用于抗体序列分析、抗体工程和免疫学研究等任务。
创建时间:
2026-03-30
原始信息汇总
OAS95-aligned-cleaned 数据集概述
数据集来源与性质
- 本数据集是一个经过清洗且依据IMGT方案进行比对后的抗体序列数据集。
- 数据源自Observed Antibody Space (OAS) 数据库。
数据准备流程
- 起始数据为经过IgLM流程预处理,并在95%序列同一性水平下进行聚类的OAS数据集。
- 所有序列均使用ANARCII工具,按照IMGT编号方案进行了编号。
- 移除了在第一个框架位置存在编号间隙的重链和轻链序列。
- 移除了短于90个残基的轻链序列。
- 最终保留了涵盖6个生物体标签和2种链类型的203,968,932条训练序列和11,819,793条测试序列。
数据列说明
| 列名 | 描述 |
|---|---|
sequence |
包含间隙字符的、经过IMGT比对的氨基酸序列。 |
init_seq |
不含比对间隙的原始氨基酸序列。 |
class |
生物体标签。 |
type |
抗体链类型:Heavy(重链)或Light(轻链)。 |
数据划分规模
- 训练集:203,968,932 条序列
- 测试集:11,819,793 条序列
- 总计:215,788,725 条序列
搜集汇总
数据集介绍
构建方式
在抗体序列分析领域,OAS95-aligned-cleaned数据集源自Observed Antibody Space(OAS)数据库,经过系统化预处理与精炼。构建过程始于采用IgLM流程预处理的OAS数据,并以95%序列同一性进行聚类,确保序列多样性得到合理控制。随后,利用ANARCII工具对所有序列按IMGT编号方案进行标准化编号,以统一结构参考框架。为进一步提升数据质量,移除了重链和轻链序列中首个框架位置存在编号间隙的条目,并过滤掉长度不足90个残基的轻链序列。最终,数据集保留了涵盖6个生物体标签和2种链类型的训练序列203,968,932条与测试序列11,819,793条,形成了结构一致且高度可靠的抗体序列集合。
使用方法
在应用层面,OAS95-aligned-cleaned数据集适用于抗体序列生成、分类及结构预测等计算生物学任务。用户可直接利用`sequence`列中的IMGT对齐序列进行模型输入,结合`class`和`type`列实现生物体或链类型的条件控制,以探索序列-功能关系。对于原始序列分析,`init_seq`列提供了未经对齐的氨基酸序列,便于对比对齐效果或进行独立处理。数据集的标准化分割允许研究者直接采用训练集进行模型训练,并使用测试集评估性能,确保实验的可重复性与公正性。该设计支持从基础序列分析到高级生成模型的广泛应用,推动抗体发现与优化研究的进展。
背景与挑战
背景概述
抗体序列分析在免疫信息学和计算生物学领域扮演着关键角色,旨在解码抗体多样性及其与抗原的相互作用机制。OAS95-aligned-cleaned数据集源于Observed Antibody Space(OAS)数据库,由研究团队通过IgLM流程预处理,并基于95%序列同一性进行聚类构建而成。该数据集创建于近年,核心研究问题聚焦于提供高质量、标准化的抗体序列数据,以支持抗体工程、免疫应答建模及药物发现等应用。通过采用IMGT编号方案对齐序列,并严格过滤框架位置缺失或长度不足的序列,该数据集显著提升了抗体序列数据的可靠性与一致性,为深度学习模型训练和生物信息学工具开发奠定了坚实基础。
当前挑战
抗体序列数据集的构建面临多重挑战。在领域问题层面,抗体序列具有极高的多样性和复杂性,准确对齐和标准化序列以保留其生物学意义至关重要,这需要克服IMGT编号中框架区域一致性维护的难题。构建过程中,原始OAS数据包含大量未对齐或低质量序列,需开发高效流程进行清洗和聚类,同时确保序列长度与结构完整性;此外,处理海量数据(如超过2亿条序列)对计算资源和存储效率提出了严峻考验,而保持链类型与生物标签的平衡分布亦增加了数据整理的复杂性。
常用场景
经典使用场景
在计算免疫学与生物信息学领域,OAS95-aligned-cleaned数据集为抗体序列分析提供了标准化基础。该数据集通过IMGT编号方案对齐并清洗,常用于训练深度学习模型以预测抗体结构或功能,例如在抗体工程中生成新型候选序列,或评估序列多样性对亲和力成熟的影响。其大规模和高一致性特点,使得研究者能够系统探索抗体序列与空间构象之间的复杂映射关系。
解决学术问题
该数据集有效解决了抗体研究中序列数据标准化不足的挑战。通过严格的IMGT对齐和间隙去除,它提供了高质量的训练样本,支持抗体特异性识别、亲和力预测及免疫库分析等核心问题。其意义在于为计算抗体设计建立了可靠基准,促进了机器学习方法在免疫学中的应用,推动了从序列到功能的可解释性研究,并加速了新型治疗性抗体的理性设计进程。
实际应用
在实际应用中,OAS95-aligned-cleaned数据集被广泛用于抗体药物发现与优化。生物技术公司及研究机构利用其训练生成模型,以设计针对特定抗原的高亲和力抗体,减少实验筛选成本。此外,该数据集支持免疫状态监测工具的开发,例如通过分析抗体库序列变化来评估疾病进展或疫苗效果,为个性化医疗提供数据驱动见解。
数据集最近研究
最新研究方向
在计算免疫学与抗体工程领域,OAS95-aligned-cleaned数据集作为大规模、高质量的抗体序列资源,正推动着前沿研究的深入发展。该数据集通过IMGT标准化对齐和严格清洗,为抗体结构预测与设计提供了精准的训练基础,尤其在基于深度学习的抗体亲和力成熟和特异性优化方向展现出关键价值。近期研究热点聚焦于利用该数据集训练生成模型,以自动化设计针对新兴病原体(如SARS-CoV-2变体)的高效抗体,同时结合图神经网络探索抗体序列与三维构象的映射关系,加速治疗性抗体的理性开发进程。这些进展不仅深化了对抗体多样性的理解,也为精准医疗和生物制药领域带来了革新性工具。
以上内容由遇见数据集搜集并总结生成


