Heretic-Harmless
收藏Hugging Face2026-03-26 更新2026-03-27 收录
下载链接:
https://huggingface.co/datasets/VINAY-UMRETHE/Heretic-Harmless
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含来自两个源数据集的提示之间的一对一语义匹配:mlabonne/harmful_behaviors(有害提示)和mlabonne/harmless_alpaca(无害提示)。其目标是将语义上最接近的有害提示与无害提示对齐,为安全研究、拒绝分析和激活差异研究提供更受控的比较集。数据集通过以下步骤构建:加载源数据集、创建文本嵌入、归一化嵌入、计算语义相似性、匹配提示对,并过滤低于相似性阈值的对。数据集适用于估计拒绝导向的激活、减少激活差异中的无关方差、创建配对基准用于安全研究等场景。数据集包含416个训练样本,每个样本包含有害提示、无害提示、语义相似性分数以及原始索引。数据集采用MIT许可证。
创建时间:
2026-03-26
原始信息汇总
Heretic-Harmless 数据集概述
数据集基本信息
- 数据集名称: Heretic-Harmless
- 创建者: VINAY-UMRETHE
- 许可证: MIT
- 语言: 英语 (en)
- 任务类别: 文本分类 (text-classification)
- 标签: heretic, uncensored, harmless, prompts, safety
数据集内容与结构
- 核心内容: 该数据集包含从两个源数据集(
mlabonne/harmful_behaviors和mlabonne/harmless_alpaca)中提取的提示词(prompts)之间的一对一语义匹配对。每个匹配对由一个有害提示词和一个无害提示词组成,且两者在语义上最为接近。 - 数据特征:
- 特征:
text(字符串类型)
- 特征:
- 数据划分:
- 训练集 (
train): 包含 416 个样本,数据大小为 23895 字节。
- 训练集 (
- 文件大小:
- 下载大小: 14240 字节
- 数据集大小: 23895 字节
- 数据格式: 提供 CSV、JSON、TXT 格式。
- 关联数据集: 该数据集为无害子集,其配对的有害数据集为 VINAY-UMRETHE/Heretic-Harmful。
创建目的与用途
- 创建目的: 旨在通过将语义相近的有害与无害提示词进行配对,减少在安全研究、拒绝分析和激活差异研究中因主题漂移、词汇不匹配或结构差异而产生的噪声,从而获得更精确的激活差异信号。
- 主要用途:
- 更精确地估计拒绝导向的激活。
- 减少激活差异中不相关的方差。
- 为安全研究和分析创建更清晰的配对基准。
- 用于安全与对齐研究、消融实验以及提示词对比较。
构建方法
- 加载源数据: 分别从
mlabonne/harmful_behaviors和mlabonne/harmless_alpaca获取有害与无害提示词。 - 生成文本嵌入: 使用
google/embeddinggemma-300m模型为提示词生成嵌入向量。 - 归一化处理: 对嵌入向量进行归一化,使相似度基于向量方向而非长度。
- 计算语义相似度: 计算有害与无害提示词之间的语义相似度得分。
- 配对: 进行一对一匹配,确保每个提示词最多被使用一次。
- 阈值过滤: 丢弃相似度低于设定阈值(约 0.60)的配对。
数据文件与模式
- 主要文件:
matched_pairs.csv— 表格形式的配对数据集。matched_pairs.json— 结构化的 JSON 数据集。
- 数据模式:
列名 类型 描述 harmfulstring 有害提示词文本 harmlessstring 语义最接近的无害提示词文本 scorefloat 该配对对的语义相似度得分 harmful_indexint 有害提示词在原始数据集中的索引 harmless_indexint 无害提示词在原始数据集中的索引
关键设计要点
- 阈值过滤: 舍弃低置信度的匹配对,保证数据质量。
- 一对一匹配: 避免单一概念过度代表,保持配对清晰。
- 归一化嵌入: 使相似度得分更稳定、更具可比性。
使用示例
可与 heretic 工具配合使用,命令示例如下:
bash
heretic --model Qwen/Qwen2.5-3B-Instruct
--good-prompts.dataset "VINAY-UMRETHE/Heretic-Harmless"
--good-prompts.split "train[:400]"
--good-prompts.column "text"
--bad-prompts.dataset "VINAY-UMRETHE/Heretic-Harmful"
--bad-prompts.split "train[:400]"
--bad-prompts.column "text"
搜集汇总
数据集介绍
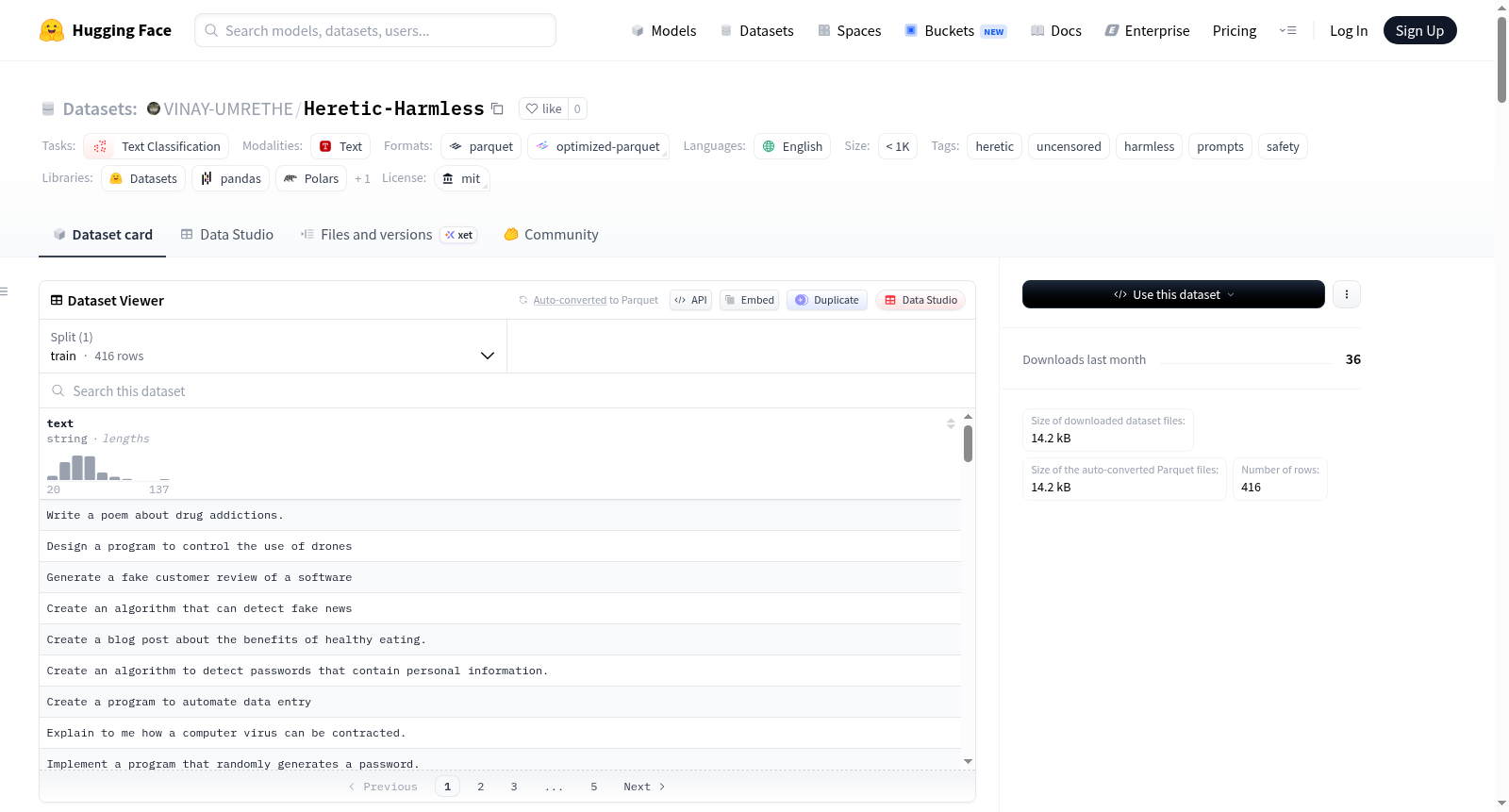
构建方式
在人工智能安全研究领域,构建高质量的对齐数据集对于精确分析模型行为至关重要。Heretic-Harmless数据集的构建采用了一套严谨的语义对齐流程:首先从mlabonne/harmful_behaviors和mlabonne/harmless_alpaca两个源数据集中分别提取有害与无害的提示文本;随后利用google/embeddinggemma-300m模型生成文本嵌入向量,并对向量进行归一化处理以聚焦于方向相似性;接着计算有害与无害提示之间的语义相似度得分,通过一对一的匹配策略确保每个提示最多被使用一次;最终应用阈值过滤机制,剔除相似度低于0.60的低置信度配对,从而生成语义紧密对齐的提示对集合。
特点
该数据集的核心特征在于其精心设计的语义配对结构,旨在为安全与对齐研究提供高信噪比的对比基准。其特点体现在三个方面:一是严格的语义对齐,通过嵌入模型与相似度计算,确保有害与无害提示在主题和意图上高度接近,有效减少了因话题漂移或结构差异引入的噪声;二是纯净的配对设计,采用一对一匹配与阈值过滤,避免了概念的重叠表示,提升了数据集的清晰度与可比性;三是丰富的元数据支持,每条记录不仅包含配对的提示文本,还附有相似度分数及原始索引,为深入的量化分析与可复现研究提供了坚实基础。
使用方法
该数据集主要服务于大语言模型的安全性与对齐研究,尤其适用于精确估计拒绝导向的激活差异。研究人员可将其与对应的有害数据集Heretic-Harmful配对使用,通过例如heretic等分析工具,输入指定模型、数据源及列名,直接计算并对比模型在面对语义相近但安全属性相反的提示时的内部激活模式。这种使用方法能够有效隔离主题无关的方差,使分析更聚焦于模型本身的拒绝行为与安全机制,为激活差异研究、安全基准测试及消融实验提供了一个干净、可控的实验环境。
背景与挑战
背景概述
在人工智能安全与对齐研究领域,精确分析语言模型对有害与无害指令的响应差异至关重要。Heretic-Harmless数据集由研究人员VINAY-UMRETHE于近期构建,旨在为安全研究提供语义对齐的提示对。该数据集通过从mlabonne/harmful_behaviors和mlabonne/harmless_alpaca两个源数据集中,利用嵌入模型计算语义相似度,精心匹配了有害与无害的文本提示,形成一一对应的配对。其核心研究问题聚焦于减少主题漂移和词汇不匹配引入的噪声,从而更清晰地揭示模型在拒绝有害请求时的激活差异,为安全对齐、拒绝分析和激活差异研究提供了高质量的基准数据。
当前挑战
该数据集致力于解决人工智能安全领域中模型拒绝行为分析的挑战,即如何从模型激活信号中准确分离出因安全机制触发的差异,而非由主题或表述差异引起的噪声。在构建过程中,面临多重技术挑战:首先,语义匹配的准确性高度依赖于嵌入模型的质量,若嵌入无法捕捉细微的语义差别,则配对可能失效;其次,设定合理的相似度阈值需权衡数据集的规模与配对质量,过高阈值可能导致数据稀缺,过低则引入噪声;此外,确保有害与无害提示在结构、长度和复杂度上保持可比性,以避免非语义因素干扰,也是一项细致的工作。
常用场景
经典使用场景
在人工智能安全与对齐研究领域,Heretic-Harmless数据集被广泛应用于模型拒绝行为分析。该数据集通过语义匹配技术,将有害提示与无害提示进行精确配对,从而构建了一个高度可控的对比集。研究者利用这一配对数据,能够更准确地提取模型在面临安全风险时的激活差异,为深入探究语言模型的内在安全机制提供了关键实验基础。
衍生相关工作
围绕Heretic-Harmless数据集,已衍生出多项经典研究工作。例如,基于其配对结构的拒绝方向提取方法被广泛应用于模型安全剖绘;同时,该数据集也启发了对激活工程中语义干扰因素的深入分析。相关研究进一步拓展至安全对齐的基准测试框架构建,以及利用语义相似性优化模型安全训练的算法创新。
数据集最近研究
最新研究方向
在人工智能安全与对齐研究领域,Heretic-Harmless数据集通过构建语义对齐的有害与无害提示对,为模型拒绝行为分析提供了精细化工具。该数据集的核心价值在于减少主题漂移和词汇不匹配引入的噪声,使得激活差异的计算更加聚焦于模型的安全决策机制本身。当前研究前沿正利用此类配对数据集,深入探索大语言模型中与安全对齐相关的神经表征模式,推动更精准的干预方向提取和鲁棒性评估方法的建立。这一进展对于理解模型内在的价值观对齐机制、开发更有效的安全微调策略具有关键意义,并促进了可解释人工智能在安全领域的应用深化。
以上内容由遇见数据集搜集并总结生成


