ausmlab/yuto-semantic
收藏Hugging Face2024-10-04 更新2025-04-26 收录
下载链接:
https://hf-mirror.com/datasets/ausmlab/yuto-semantic
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-4.0
---
# YUTO: A Large Scale Aerial LiDAR Data Set for Semantic Segmentation
## Overview
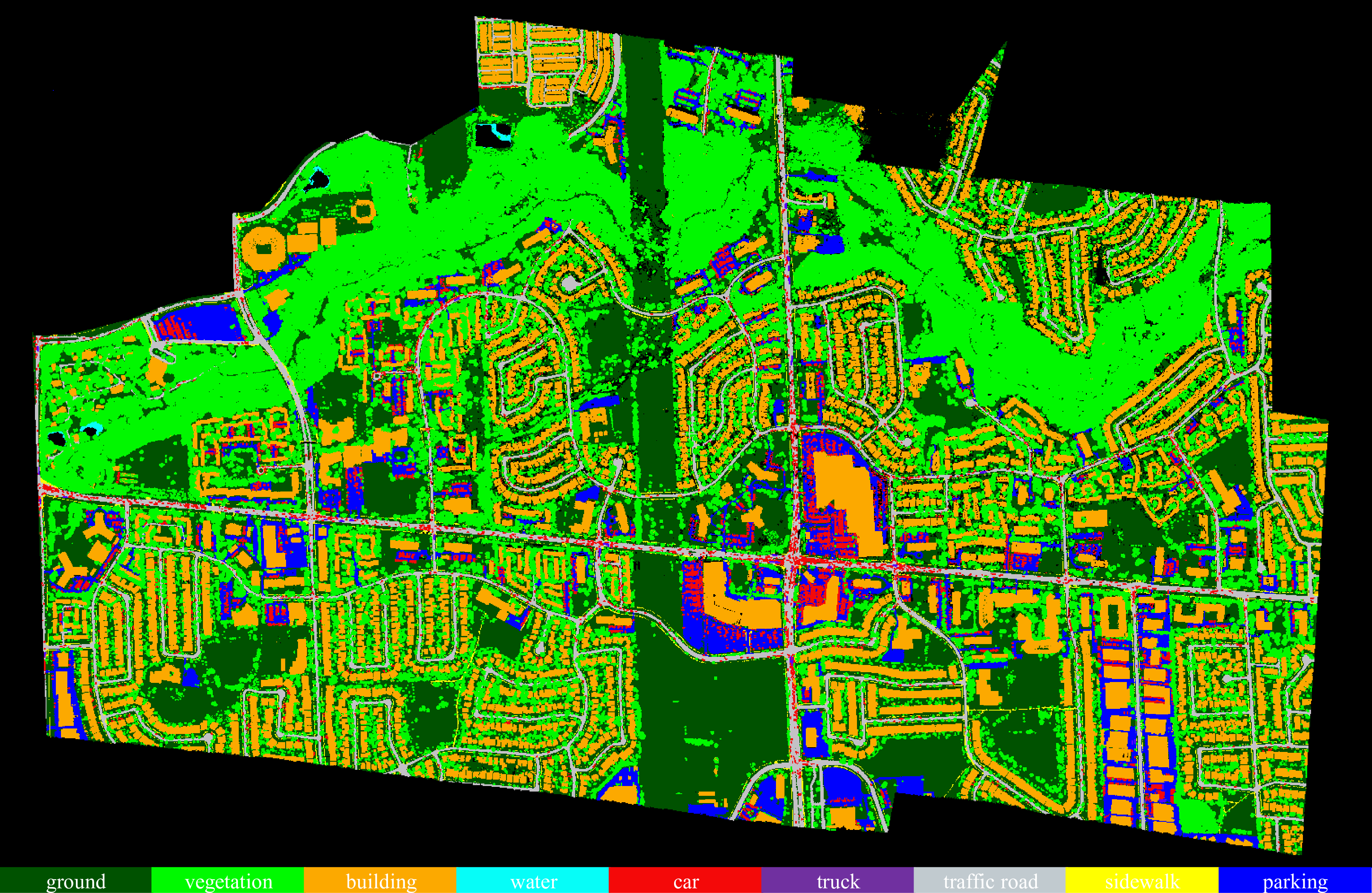
YUTO Semantic is a multi-mission large-scale aerial LiDAR dataset specifically designed for 3D point cloud semantic segmentation. The dataset comprises approximately 738 million points, covering an area of 9.46 square kilometers of York University Campus in Toronto, Ontario Canada. Each point in the dataset is annotated with one of nine semantic classes.
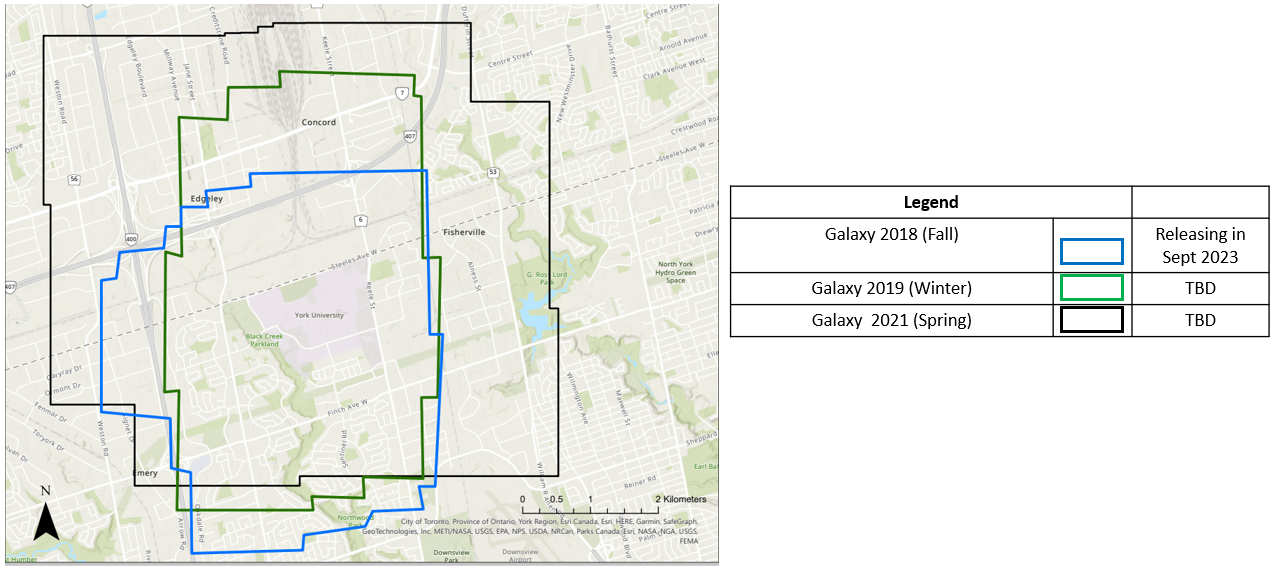
At this time, we are releasing one mission, Galaxy 2018 Fall. We are planning to release the rest of the missions. Details of the dataset can be found in ISPRS GSW 2023.
## Available Classes
* Ground: This class includes unpaved surfaces, grass, and natural terrain.
* Vegetation: This class encompasses trees, bushes, and other forms of vegetation.
* Building: This class represents both commercial and residential buildings.
* Water: This class includes bodies of water such as lakes and rivers.
* Car: This class includes all types of vehicles except for commercial trucks.
* Truck: This class specifically represents commercial trucks.
* Traffic Road: This class corresponds to vehicle roads.
* Sidewalk: This class represents pedestrian walkways.
* Parking: This class represents parking lots.
## Available Attributes
* x, y, z: The position coordinates of each point recorded in UTM zone 17N using the NAD83 horizontal datum.
* Intensity: The normalized LiDAR intensity value of each point, ranging from 0 to 255.
* Number of Return: The number of times the laser pulse was reflected back.
* GPS time: The GPS time of each point, providing temporal information about the data acquisition.
* Scan Angle: The scan angle of each point, indicating the angle at which the laser beam hit the target.
* Class: The label assigned to each point, representing the semantic class or category of the object or surface the point belongs to.
## Semantic Segmentation Results
New results will be updated.
| Method | OA | mIoU | ground | vegetaion | building | water | car | truck | traffic road | sidewalk | parking |
|------------------|--------|--------|--------|----------|---------|----------|-----------|--------|--------|--------|--------|
|PointNet| --| 33.22| 74.5| 76.8| 63.3| 0| 39.94| 0| 15.1| 0| 29.8|
|PointNet++| --| 26.16| 68.10| 66.70| 31.80| 0| 14.10| 0| 26.00| 2,50| 26.20|
|SPG | --| 36.68| 79.31| 97.92| 0.00| 57.37| 0.00| 36.92| 0.39| 39.51| 0.00|
|SFL-Net | --| 51.05| 80.91| 94.10| 88.33| 0.00| 74.47| 0.00| 53.71| 23.08| 44.81|
|RandLA | 84.19| 58.37| 80.61| 94.44| 95.39| 3.34| 74.59| 13.87| 78.10| 23.43| 61.56|
|KPConv | 85.22| 56.14| 86.94| 96.25| 94.01| 0.00| 84.02| 0.00| 79.93| 3.26| 60.83|
|EyeNet | 87.41| 63.44| 86.26| 95.94| 96.78| 13.61| 83.02| 14.26| 84.65| 31.08| 65.34|
## Citation
If you find this work useful, please consider citing our work.
@article{yoo2023yuto,
title={Yuto Semantic: a Large Scale Aerial LIDAR Dataset for Semantic Segmentation},
author={Yoo, S and Ko, C and Sohn, G and Lee, H},
journal={The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences},
volume={48},
pages={209--215},
year={2023},
publisher={Copernicus GmbH}
}
---
license: CC-BY-NC-4.0
---
# YUTO:面向语义分割的大规模航空激光雷达(LiDAR)数据集
## 概览

YUTO语义数据集是专为三维点云语义分割设计的多航次大规模航空激光雷达数据集。该数据集包含约7.38亿个点,覆盖加拿大安大略省多伦多市约克大学校园9.46平方公里的区域。数据集中的每个点均标注有9个语义类别之一。

目前仅发布2018年秋季Galaxy航次的数据集,剩余航次的发布计划正在筹备中。该数据集的详细信息可查阅ISPRS GSW 2023会议论文。
## 可用语义类别
* 地面(Ground):该类别包含未铺装路面、草地及自然地形。
* 植被(Vegetation):该类别涵盖树木、灌木及其他各类植被。
* 建筑物(Building):该类别涵盖商用与民用建筑。
* 水域(Water):该类别包含湖泊、河流等各类水体。
* 小型汽车(Car):该类别包含除商用货运卡车外的所有类型车辆。
* 商用卡车(Truck):该类别特指商用货运车辆。
* 机动车道(Traffic Road):该类别对应供机动车通行的道路。
* 人行道(Sidewalk):该类别指代行人专用步道。
* 停车场地(Parking):该类别指代停车场区域。
## 可用属性
* x、y、z:采用北美大地基准84(NAD83)水平基准面、通用横轴墨卡托17N带(UTM zone 17N)坐标系记录的各点位置坐标。
* 强度(Intensity):各点的归一化激光雷达强度值,取值范围为0至255。
* 回波次数(Number of Return):激光脉冲的反射次数。
* GPS时间(GPS time):各点对应的GPS采集时刻,提供数据采集的时序信息。
* 扫描角(Scan Angle):各点的扫描角度,表征激光束入射目标时的夹角。
* 类别标签(Class):为各点分配的语义标签,代表该点所属物体或表面的语义类别。
## 语义分割实验结果
后续将更新最新实验结果。
| 方法 | 总体精度(OA) | 平均交并比(mIoU) | 地面 | 植被 | 建筑物 | 水域 | 小型汽车 | 商用卡车 | 机动车道 | 人行道 | 停车场地 |
|------|--------|--------|--------|----------|---------|----------|-----------|--------|--------|--------|--------|
| PointNet | -- | 33.22 | 74.5 | 76.8 | 63.3 | 0 | 39.94 | 0 | 15.1 | 0 | 29.8 |
| PointNet++ | -- | 26.16 | 68.10 | 66.70 | 31.80 | 0 | 14.10 | 0 | 26.00 | 2.50 | 26.20 |
| SPG | -- | 36.68 | 79.31 | 97.92 | 0.00 | 57.37 | 0.00 | 36.92 | 0.39 | 39.51 | 0.00 |
| SFL-Net | -- | 51.05 | 80.91 | 94.10 | 88.33 | 0.00 | 74.47 | 0.00 | 53.71 | 23.08 | 44.81 |
| RandLA | 84.19 | 58.37 | 80.61 | 94.44 | 95.39 | 3.34 | 74.59 | 13.87 | 78.10 | 23.43 | 61.56 |
| KPConv | 85.22 | 56.14 | 86.94 | 96.25 | 94.01 | 0.00 | 84.02 | 0.00 | 79.93 | 3.26 | 60.83 |
| EyeNet | 87.41 | 63.44 | 86.26 | 95.94 | 96.78 | 13.61 | 83.02 | 14.26 | 84.65 | 31.08 | 65.34 |
## 引用说明
若您的工作用到本数据集,请引用以下学术文献:
bibtex
@article{yoo2023yuto,
title={Yuto Semantic: a Large Scale Aerial LIDAR Dataset for Semantic Segmentation},
author={Yoo, S and Ko, C and Sohn, G and Lee, H},
journal={The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences},
volume={48},
pages={209--215},
year={2023},
publisher={Copernicus GmbH}
}
提供机构:
ausmlab
搜集汇总
数据集介绍

构建方式
在遥感与三维地理信息科学领域,大规模高精度标注数据的获取对推动语义分割算法发展至关重要。YUTO数据集通过机载激光雷达系统,对加拿大安大略省多伦多约克大学校园9.46平方公里区域进行多航次扫描,采集了约7.38亿个三维点云数据。每个点均经过人工与自动化流程结合的精标注,归属地面、植被、建筑、水体、车辆等九类语义类别,并附带强度、回波次数、GPS时间等多维度属性,构建过程严格遵循地理空间数据标准,采用UTM坐标系与NAD83基准确保空间精度。
特点
该数据集的核心特征在于其规模宏大且标注粒度精细,覆盖城市校园环境的典型地物类别,尤其区分了轿车与商用卡车等细粒度目标。数据点云密度高,兼具空间坐标、反射强度与时间序列等多模态属性,为算法提供了丰富的特征学习基础。不同航次数据的持续发布计划进一步增强了时序分析潜力,使其成为评估三维点云语义分割模型鲁棒性与泛化能力的权威基准之一。
使用方法
研究人员可通过HuggingFace平台直接加载数据集,利用其提供的坐标、强度及类别标签进行端到端的语义分割模型训练。典型流程包括点云预处理、区块划分与数据增强,继而输入PointNet++、RandLA-Net等主流网络进行训练与验证。数据集的GPS时间与扫描角度属性支持动态场景分析与多任务学习,例如结合时序信息研究地物变化。用户需遵循CC-BY-NC-4.0许可协议,并在学术成果中引用相关文献以符合规范。
背景与挑战
背景概述
YUTO语义分割数据集由澳大利亚机器学习实验室(ausmlab)于2023年发布,旨在推动大规模航空激光雷达点云语义分割研究。该数据集聚焦于城市环境的三维理解,覆盖了加拿大安大略省多伦多约克大学校园9.46平方公里的区域,包含约7.38亿个标注点,涵盖地面、植被、建筑、水体、车辆等九类语义标签。其核心研究问题在于解决复杂城市场景中高精度、细粒度的三维语义分割,为自动驾驶、城市规划及遥感分析等领域提供了关键数据支撑,显著提升了模型在真实世界场景中的泛化能力与实用性。
当前挑战
该数据集致力于应对城市场景点云语义分割中类别不平衡、小目标识别及复杂结构解析等核心难题。具体而言,数据集中某些类别如卡车、水体样本稀少,导致模型难以学习其有效特征;同时,点云数据的稀疏性与噪声干扰,加之大规模场景中几何细节的保留,对算法效率与精度提出了双重考验。在构建过程中,研究人员面临海量点云数据的采集、配准与标注挑战,需克服传感器误差、多时相数据融合以及人工标注一致性等困难,这些因素共同构成了数据集应用与发展的关键瓶颈。
常用场景
经典使用场景
在遥感与地理信息科学领域,大规模点云数据的语义分割是理解复杂城市场景的关键技术。YUTO数据集以其覆盖约9.46平方公里、包含7.38亿个标注点的规模,为研究人员提供了评估三维点云语义分割算法的基准平台。该数据集通过精细标注的地面、植被、建筑、车辆等九类语义信息,支持深度学习模型在复杂空中激光雷达数据上的性能验证与比较,成为推动点云分割技术进步的重要资源。
解决学术问题
YUTO数据集有效应对了城市场景点云语义分割中数据规模不足、类别不平衡及标注粒度粗糙等学术挑战。通过提供大规模、多类别的精细标注,该数据集促进了分割算法在罕见类别(如卡车、人行道)上的泛化能力研究,并支持了基于强度、回波数等多属性特征的融合学习方法探索。其发布显著提升了三维场景理解模型的鲁棒性与准确性,为遥感智能解译提供了可靠的数据支撑。
衍生相关工作
围绕YUTO数据集,学术界衍生了一系列经典研究工作,包括PointNet、PointNet++等基础网络架构的性能评估,以及RandLA-Net、KPConv、EyeNet等先进点云分割模型的对比与优化。这些研究不仅验证了不同算法在大规模空中点云数据上的有效性,还催生了针对LiDAR多属性特征融合、长尾类别处理等问题的创新方法,进一步丰富了三维计算机视觉与遥感分析领域的技术体系。
以上内容由遇见数据集搜集并总结生成


