Codetrace-Benchmark
收藏Hugging Face2026-03-31 更新2026-04-01 收录
下载链接:
https://huggingface.co/datasets/Codetrace-Bench/Codetrace-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
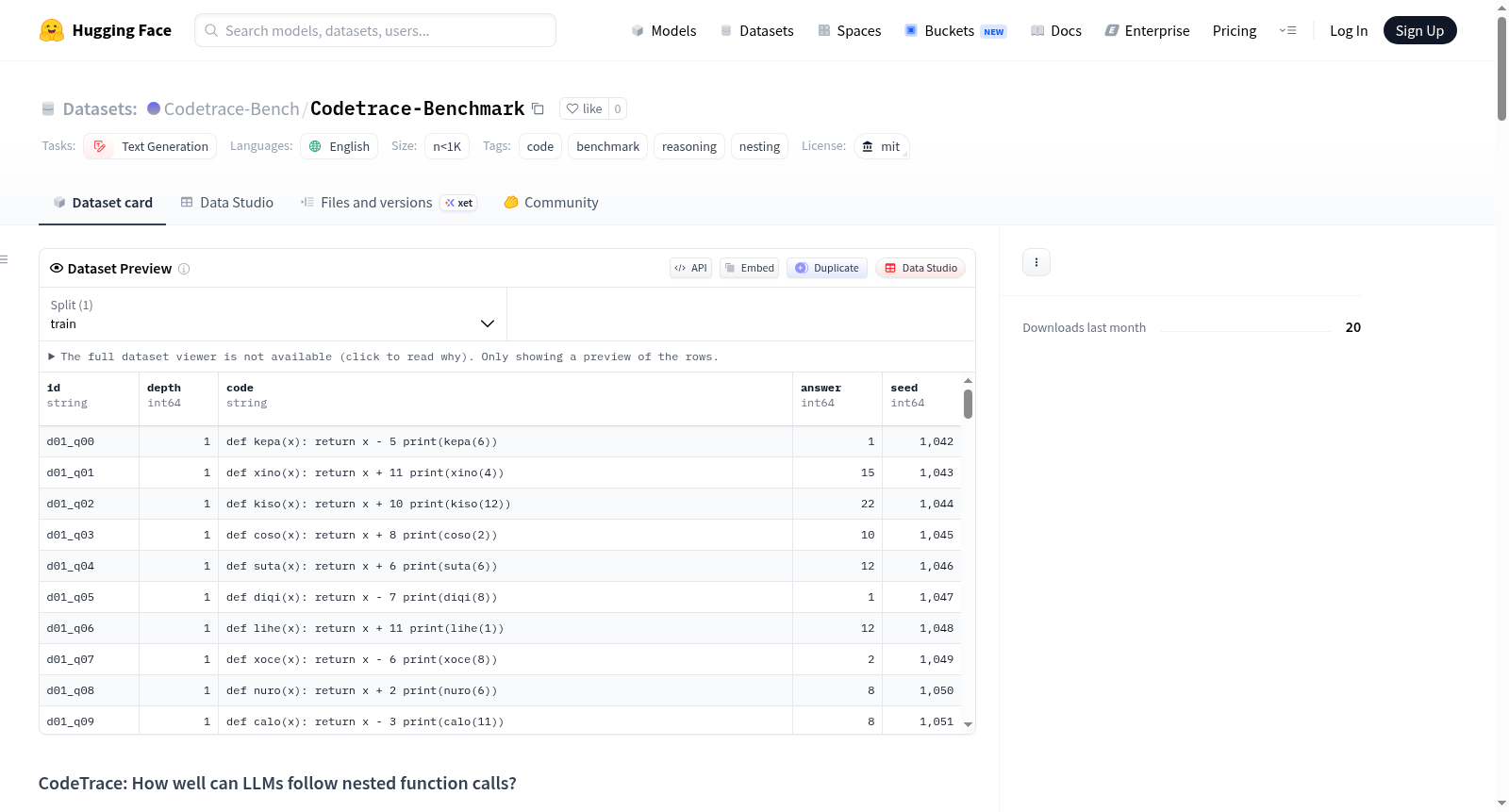
CodeTrace Benchmark是一个专为评估大型语言模型(LLMs)追踪嵌套函数调用能力而设计的基准测试数据集。该数据集包含400个代码追踪问题,覆盖1到20层嵌套深度,每个问题均采用无意义函数名和简单加法运算构成,要求模型追踪执行过程并报告最终打印的数字。数据集旨在通过精确测量模型在不同嵌套深度下的准确率曲线,揭示模型在代码审查、调试和程序分析任务中的实际推理能力边界。
数据集特点包括:使用无意义函数名防止记忆和模式匹配;简单算术运算隔离组合推理难度;每个深度20个问题(N=20)确保5%的准确度估计粒度;确定性生成保证结果可复现。数据集文件包含预生成问题、问题生成器、评分脚本及本地/API测试工具,支持对HuggingFace模型及各类API端点(OpenAI、Anthropic、Google等)的测试。
基准测试结果显示,模型性能会在特定嵌套深度出现断崖式下降,且该临界深度受训练方法(如RL蒸馏)和提示策略(分步追踪)显著影响。数据集采用MIT许可证,鼓励用户提交测试结果以共建模型性能排行榜。
创建时间:
2026-03-30
原始信息汇总
CodeTrace Benchmark 数据集概述
数据集基本信息
- 数据集名称:CodeTrace Benchmark
- 托管地址:https://huggingface.co/datasets/Codetrace-Bench/Codetrace-Benchmark
- 许可证:MIT
- 任务类别:文本生成
- 主要语言:英语
- 标签:代码、基准测试、推理、嵌套
- 数据规模:小于1K样本
核心目标
评估大型语言模型在追踪嵌套函数调用方面的能力,具体探究模型能够可靠追踪的嵌套深度层级。
基准测试内容
- 问题数量:400个代码追踪问题。
- 嵌套深度范围:覆盖深度1至20。
- 问题形式:每条问题均为一个由嵌套函数调用组成的链,函数名均为无意义的随机名称,内部仅包含简单的加减法算术运算。
- 模型任务:模型必须追踪执行过程并报告最终打印的数字。
- 设计特点:
- 使用无意义函数名以防止记忆和模式匹配。
- 仅使用小整数的加减法运算,以隔离组合推理与数学计算难度。
- 每个深度包含20个问题,准确率估计具有5%的粒度。
- 基于种子确定性生成,确保结果完全可复现。
主要发现
- 性能“断崖”现象:模型性能并非逐渐下降,而是在达到特定嵌套深度时出现急剧下降。
- 训练方法的影响:“断崖”出现的位置更多取决于训练方法而非模型大小。
- 逐步追踪提示的影响:强制模型进行逐步追踪在中等嵌套深度下能显著提升准确率,但在高嵌套深度下反而会损害性能,存在一个模型依赖的“交叉点”深度。
示例结果
| 模型 | 参数量 | 标准提示下的断崖深度 | 逐步追踪提示下的断崖深度 | 备注 |
|---|---|---|---|---|
| Qwen2.5-7B-Instruct | 7B | 深度 4 | — | 基础模型 |
| DeepSeek-R1-Distill-Qwen-7B | 7B | 深度 6 | 深度 8 | 从R1进行RL蒸馏的模型 |
数据集文件结构
benchmark/ ├── questions.json # 包含已验证答案的400个问题 ├── generator.py # 生成任意深度的新问题 ├── scorer.py # 为模型响应评分 ├── run_benchmark.py # 在本地HuggingFace模型上运行 └── run_benchmark_api.py # 通过API运行(兼容OpenAI、Anthropic、Google) results/ ├── deepseek_r1_7b_standard.json ├── deepseek_r1_7b_constrained.json └── qwen_2_5_7b.json plots/ ├── nesting_accuracy.png # 主要对比图表 └── scaffolding_crossover.png # 逐步追踪帮助与损害对比图
使用方式
- 环境设置:克隆仓库并安装依赖。
- 生成问题:可使用提供的
questions.json或运行生成器脚本生成新问题。 - 运行基准测试:
- 对本地HuggingFace模型使用
run_benchmark.py。 - 通过API(兼容OpenAI、Anthropic、Google)使用
run_benchmark_api.py。
- 对本地HuggingFace模型使用
- 评分:使用
scorer.py脚本对模型输出进行评分,得到各嵌套深度的准确率曲线及“断崖”深度等指标。 - 提交结果:鼓励用户提交自己模型的测试结果以共建排行榜。
基准测试特点
与多数仅提供单一总分的基准测试不同,CodeTrace提供一条准确率曲线,清晰展示模型在每个嵌套深度上的性能表现,精确指出模型开始失效的位置,便于比较不同模型的性能衰减方式。
搜集汇总
数据集介绍
构建方式
在代码分析与推理评估领域,Codetrace-Benchmark的构建采用了系统化的生成策略。该数据集包含400道代码追踪问题,覆盖了嵌套深度从1到20的完整范围。每个问题均由一系列嵌套函数调用构成,其中函数名称均为无意义的随机字符串,旨在彻底杜绝模型通过模式匹配或记忆进行猜测的可能性。问题内容仅涉及简单的加减法算术运算,从而将评估焦点严格限定于模型对嵌套结构的顺序推理能力。数据生成过程完全基于确定性种子实现,确保了结果的高度可复现性,并为每个深度级别提供了20个样本,以保障统计估计的可靠性。
特点
该数据集的核心特征在于其专注于评估大语言模型在代码嵌套调用追踪任务中的极限性能。区别于传统基准测试仅提供单一综合分数,Codetrace-Benchmark通过绘制模型在不同嵌套深度上的准确率曲线,精确揭示其性能断崖式下降的“临界深度”。这一设计使得研究者能够直观比较不同模型在组合推理能力上的本质差异。数据集通过使用无意义函数名和基础算术,有效隔离了符号推理与数学计算复杂度,纯粹考验模型对程序执行流的逻辑跟踪能力。其提供的结构化评估框架,能够清晰展示分步提示策略在不同深度区间产生的助益与损害效应。
使用方法
使用该数据集进行模型评估具备高度的灵活性与可扩展性。研究人员可通过提供的脚本,在本地直接加载HuggingFace模型进行测试,或通过兼容OpenAI的API接口对云端模型进行评估,支持包括vLLM、Anthropic、Google在内的多种服务。基准测试流程包含问题生成、模型推理与结果评分三个标准化步骤。用户可自由选择标准提示或强制分步追踪的约束提示策略,以探究不同交互方式对模型性能的影响。完成评估后,利用评分脚本可自动计算各深度准确率并拟合性能曲线,所得结果可提交至项目以参与公开排行榜的构建。
背景与挑战
背景概述
随着大型语言模型在代码审查、调试及程序分析等领域的广泛应用,评估其逻辑推理能力成为研究热点。Codetrace-Benchmark数据集由相关研究团队于近期构建,旨在探究模型追踪嵌套函数调用的深度极限。该数据集通过设计包含随机无意义函数名的代码链,剥离了模式匹配的干扰,聚焦于模型对程序执行路径的纯顺序推理能力。其核心研究问题在于量化模型在不同嵌套层级下的准确率变化,揭示模型性能的突变边界,为模型训练方法与架构优化提供了关键实证依据。
当前挑战
该数据集针对代码推理领域中的嵌套调用追踪问题,挑战在于模型往往在特定嵌套深度遭遇性能断崖式下降,而非渐进衰减。构建过程中的挑战包括确保问题生成的确定性以避免偏差,以及通过无意义命名和简单算术隔离组合推理的复杂性,防止模型依赖记忆或数学计算能力。此外,设计需平衡提示策略的效益,例如逐步追踪在中等深度提升准确性,却在深层嵌套中因错误传播导致性能下降,这要求基准能精确捕捉模型失效的临界点。
常用场景
经典使用场景
在代码智能与程序分析领域,Codetrace-Benchmark 被广泛用于评估大型语言模型在追踪嵌套函数调用时的推理能力。该数据集通过设计深度从1到20的嵌套函数链,要求模型执行纯粹的序列化逻辑推理,以计算最终输出值。经典使用场景包括模型能力基准测试,特别是在代码审查、调试和程序理解任务中,研究者利用该数据集精确测量模型在不同嵌套深度下的准确率曲线,从而揭示模型在复杂逻辑结构中的性能边界。
解决学术问题
该数据集解决了大型语言模型在代码推理中关于组合性泛化与深度逻辑追踪的学术研究问题。通过消除函数名的语义信息与简化算术操作,它隔离了模型对模式匹配的依赖,迫使模型进行逐步的符号执行。其意义在于量化了模型在嵌套调用中的“崩溃点”,即准确率急剧下降的深度,这为理解模型内部推理机制、训练方法(如强化学习蒸馏)对性能的影响提供了实证基础,推动了代码推理评估从单一分数向细粒度性能曲线的转变。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在模型架构与训练方法的改进上。例如,基于深度蒸馏的 DeepSeek-R1 模型在嵌套追踪任务中表现出更强的深度泛化能力,引发了关于强化学习在代码推理中作用的研究。同时,对“脚手架效应”的深入分析——即分步提示在中等深度有益却在高度嵌套时有害的现象——催生了自适应推理策略的探索,这些工作推动了代码追踪基准从静态评估向动态、上下文感知的评估框架演进。
以上内容由遇见数据集搜集并总结生成


