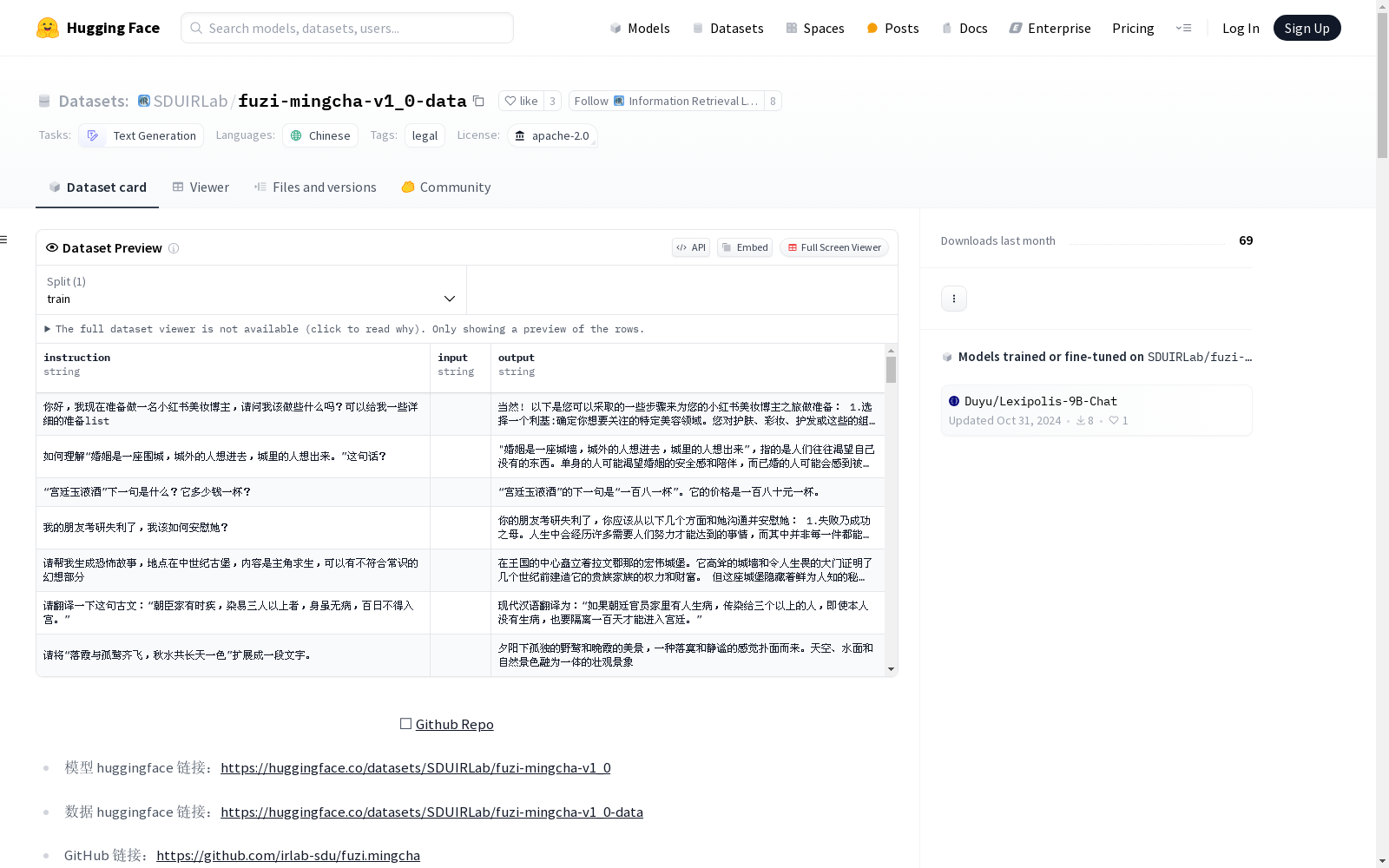
fuzi-mingcha-v1_0-data
收藏夫子•明察司法大模型微调训练数据归档
数据信息
数据集主要分为四类:
- 通用微调数据集
- 基于法条的问答数据集
- 案例检索、案例分析类数据集
- 三段论判决数据集
数据集目录
| Directory | Filename | Num Samples |
|---|---|---|
| . | oaast_sft_zh.json | 689 |
| alpaca | alpaca_data_zh_51k.json | 5,000 |
| alpaca | alpaca_gpt4_data_zh.json | 5,000 |
| belle | belle.jsonl | 10,000 |
| cail2021_rc | cail_21_rc.jsonl | 4,200 |
| cail2022_summarization.wo_art | cail_22_summarization.jsonl | 5,750 |
| case_retrieval | new_candidates.jsonl | 9,208 |
| case_retrieval | new_pretrain.jsonl | 6,026 |
| case_retrieval | new_query.jsonl | 107 |
| case_retrieval | query.jsonl | 107 |
| hanfei | zh_law_conversation_v2.jsonl | 20,000 |
| hanfei | zh_law_instruction_v2.jsonl | 20,000 |
| lawGPT_zh | lawgpt4analyse_v2.jsonl | 15,000 |
| lawGPT_zh | lawgpt4answer_v2.jsonl | 10,000 |
| lawGPT_zh | lawgpt4fatiao_v2.jsonl | 10,000 |
| lawyerllama | lawyer_llama_4analyse_v1.jsonl | 1,000 |
| lawyerllama | lawyer_llama_4answer_v1.jsonl | 1,000 |
| lawyerllama | lawyer_llama_4fatiao_v1.jsonl | 1,000 |
| lawyerllama_counsel | legal_advice.json | 3,000 |
| lawyerllama_counsel | legal_counsel_v2.json | 5,000 |
| OL_CC | OL_CC.jsonl | 10006 |
| pretrain_judge_w_article | judge_w_article_v6.jsonl | 15,000 |
| pretrain_small_law | complement.json | 12,000 |
| pretrain_small_law | pretrain_case.json | 52 |
| pretrain_small_law | query_item.json | 20,000 |
| syllogism[1] | legal_article.json | 11,237 |
| syllogism[1] | syllogism.json | 11,237 |
注 1:三段论推理数据集已发表在 EMNLP 2023,详细信息请参考论文代码。
数据来源
case_retrieval目录下的数据集通过爬取的裁判文书数据进行构建,结合 ChatGPT 构建部分 query。pretrain_*目录下的数据由预训练数据(裁判文书、法律法规等)构造完成。syllogism目录下数据来源见注 1。- 其他数据收集整理和筛选于网络公开信息。
如何使用
若您想将数据集用于您的模型训练,您可以克隆本仓库,以下命令为 huggingface 网站提供的提示。
bash
Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
When prompted for a password, use an access token with write permissions.
Generate one from your settings: https://huggingface.co/settings/tokens
git clone https://huggingface.co/datasets/SDUIRLab/fuzi-mingcha-v1_0-data
请确保您的磁盘空间足够存储数据集,数据集大小约为 1.12GB。
致谢
本项目基于如下开源项目展开,在此对相关项目和开发人员表示感谢:
- Alpaca
- BELLE
- ChatGLM-6B
- ChatGLM-Efficient-Tuning
- Lawyer LLaMA
- LaWGPT
- JEC-QA
- PKU Opendata
- LawRefBook
- CAIL 2018-2021
- HanFei
- BAAI
声明
本项目的内容仅供学术研究之用,不得用于商业或其他可能对社会造成危害的用途。 在涉及第三方代码的使用时,请切实遵守相关的开源协议。 本项目中大模型提供的法律问答、判决预测等功能仅供参考,不构成法律意见。 如果您需要法律援助等服务,请寻求专业的法律从业者的帮助。
协议
本仓库的代码依照 Apache-2.0 协议开源,我们对 ChatGLM-6B 模型的权重的使用遵循 Model License。
引用
如果本项目有帮助到您的研究,请引用我们:
@misc{fuzi.mingcha, title={fuzi.mingcha}, author={Shiguang Wu, Zhongkun Liu, Zhen Zhang, Zheng Chen, Wentao Deng, Wenhao Zhang, Jiyuan Yang, Zhitao Yao, Yougang Lyu, Xin Xin, Shen Gao, Pengjie Ren, Zhaochun Ren, Zhumin Chen} year={2023}, publisher={GitHub}, journal={GitHub repository}, howpublished={url{https://github.com/irlab-sdu/fuzi.mingcha}}, }
@inproceedings{deng-etal-2023-syllogistic, title = {Syllogistic Reasoning for Legal Judgment Analysis}, author = {Deng, Wentao and Pei, Jiahuan and Kong, Keyi and Chen, Zhe and Wei, Furu and Li, Yujun and Ren, Zhaochun and Chen, Zhumin and Ren, Pengjie}, year = 2023, month = dec, booktitle = {Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing}, publisher = {Association for Computational Linguistics}, address = {Singapore}, pages = {13997--14009}, doi = {10.18653/v1/2023.emnlp-main.864}, url = {https://aclanthology.org/2023.emnlp-main.864}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika} }