earnings-call-data
收藏Hugging Face2026-04-12 更新2026-04-13 收录
下载链接:
https://huggingface.co/datasets/RudrakshNanavaty/earnings-call-data
下载链接
链接失效反馈官方服务:
资源简介:
S&P 500收益事件数据集(2005-2025年)是一个增强版的数据集,基于Bose345/sp500_earnings_transcripts,整合了收益电话会议记录、市场价格、SEC文件和标签数据。每个数据行代表一个公司-季度的电话会议,包含完整的收益电话会议记录、SEC新闻材料、收益前价格背景、OHLCV锚点、SEC XBRL基本面数据(xbrl_*列)以及收益后回报标签。数据集规模约为33,000行,涵盖2005-2025年期间的数百种股票。适用于文本分类、摘要、特征提取、文本检索和强化学习等任务。数据集包含主文件episodes.parquet和子集文件episodes_press_release_8k.parquet,后者仅包含SEC 8-K正文文本不为空的行。数据集还提供了Sweetviz HTML报告,用于探索性分析。使用该数据集时需注意上游数据的许可条款和SEC的公平访问政策。
创建时间:
2026-04-11
搜集汇总
数据集介绍
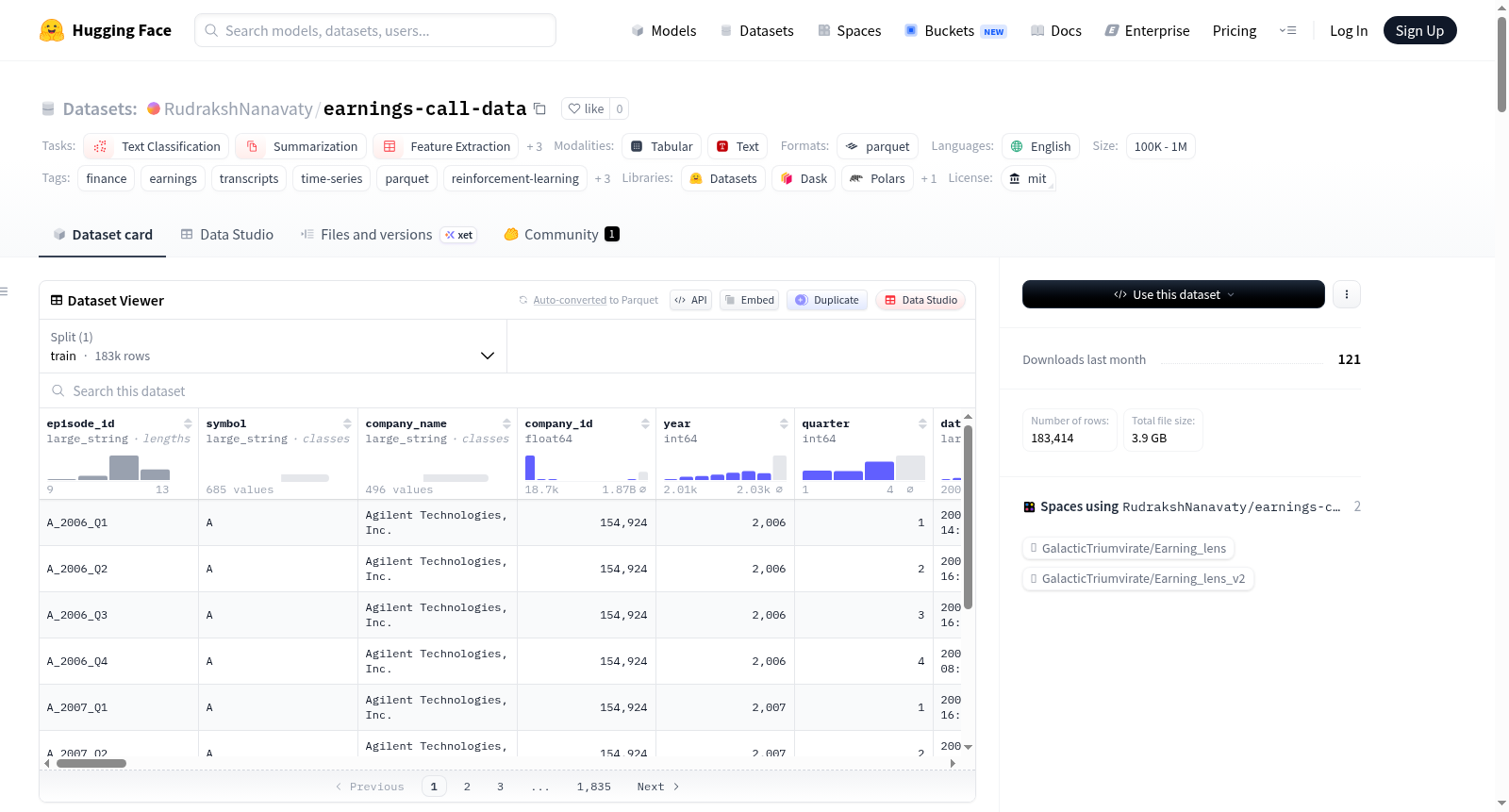
构建方式
在金融文本分析领域,本数据集通过系统化的多源数据融合流程构建而成。其核心基础源自Hugging Face平台上的标准普尔500指数成分股收益电话会议文本集合,时间跨度覆盖2005年至2025年。构建过程整合了雅虎财经的市场价格数据、美国证券交易委员会(SEC)EDGAR系统中的8-K文件正文及附件文本,并进行了特征工程处理。关键环节包括通过SEC公司事实JSON接口提取并匹配XBRL格式的标准化财务数据,最终将所有信息按公司-季度通话事件进行对齐与合并,形成以稳定事件ID为键的完整观测记录。
特点
该数据集的核心特征在于其多维度的结构化信息集成。每条记录不仅包含完整的收益电话会议文本,还融合了会前价格动量、成交量等市场特征,以及会后短期与中期的价格回报标签。尤为突出的是,数据集引入了源自SEC官方XBRL数据的标准化财务指标,涵盖利润表、资产负债表和现金流量表的关键项目,为结合文本与量化信息的研究提供了统一框架。数据集还提供了详细的审计字段与数据来源标识,确保了研究的可追溯性与透明度。
使用方法
研究者可通过加载主文件`episodes.parquet`直接获取完整的结构化数据集,利用pandas或PyArrow进行高效分析。对于专注于SEC官方新闻稿的研究,可选用`episodes_press_release_8k.parquet`子集。数据集适用于监督学习、强化学习环境构建及多模态金融预测任务。使用时应充分考虑财务数据字段的稀疏性,并注意时间序列的非平稳性,建议结合随附的Sweetviz可视化报告进行探索性数据分析,以理解数据分布与缺失模式。
背景与挑战
背景概述
在金融量化分析领域,收益电话会议作为上市公司与投资者沟通的关键渠道,蕴含了丰富的非结构化文本信息,对市场情绪与资产定价具有深远影响。S&P 500收益电话会议数据集(2005–2025)由研究人员Rudraksh Nanavaty基于Bose345的原始转录本构建,其核心研究问题在于如何将长文本转录、市场价格序列、美国证券交易委员会(SEC)披露文件及可扩展商业报告语言(XBRL)财务数据深度融合,以支持监督学习与强化学习实验。该数据集通过系统性的特征工程,为每一公司-季度收益事件构建了统一的观测单元,显著推动了金融自然语言处理与多模态时序预测的交叉研究。
当前挑战
该数据集致力于解决金融文本与市场信号融合预测的复杂问题,其核心挑战在于如何从异构、高噪声的源数据中提取稳健且可解释的特征。具体而言,领域问题的挑战体现在收益电话会议文本的语义解析、市场反应的因果推断,以及财务数据的时间对齐与概念匹配。在构建过程中,数据集面临多重技术障碍:包括SEC EDGAR数据获取的速率限制、不同数据源(如转录本、价格、XBRL)在时间粒度与标识符上的对齐困难,以及早期年份(2009年前)XBRL财务数据的普遍缺失所导致的数据稀疏性。此外,生存偏差与金融制度的非平稳性亦对模型的泛化能力构成持续考验。
常用场景
经典使用场景
在金融文本分析领域,该数据集为研究提供了宝贵的多模态资源。其经典使用场景聚焦于结合财报电话会议文本与市场数据,构建监督学习或强化学习模型。研究者能够利用完整的收益记录、SEC文件正文以及价格动量等特征,预测短期股价走势或市场情绪标签,从而探索语言信息与资产价格动态之间的复杂关联。
解决学术问题
该数据集有效解决了金融信息处理中的若干关键学术问题。它将非结构化文本(如管理层讨论)与结构化市场数据及SEC XBRL财务指标对齐,为检验语言信号对市场效率的影响提供了实证基础。其意义在于弥合了定性披露与定量金融之间的鸿沟,支持对市场反应、信息扩散及基本面分析的前沿研究,推动了计算金融与自然语言处理交叉领域的理论发展。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。例如,基于其文本与市场特征的多任务学习模型,用于联合预测股价波动与收益方向;利用其构建的强化学习环境,模拟基于收益公告序列的序贯决策问题;此外,结合XBRL财务指标的研究,探索了文本情绪与公司基本面在解释市场异常回报中的交互作用,推动了可解释AI在金融领域的应用。
以上内容由遇见数据集搜集并总结生成


