CHIRP
收藏arXiv2025-01-21 更新2025-02-25 收录
下载链接:
https://huggingface.co/datasets/cerc-aai/CHIRP
下载链接
链接失效反馈官方服务:
资源简介:
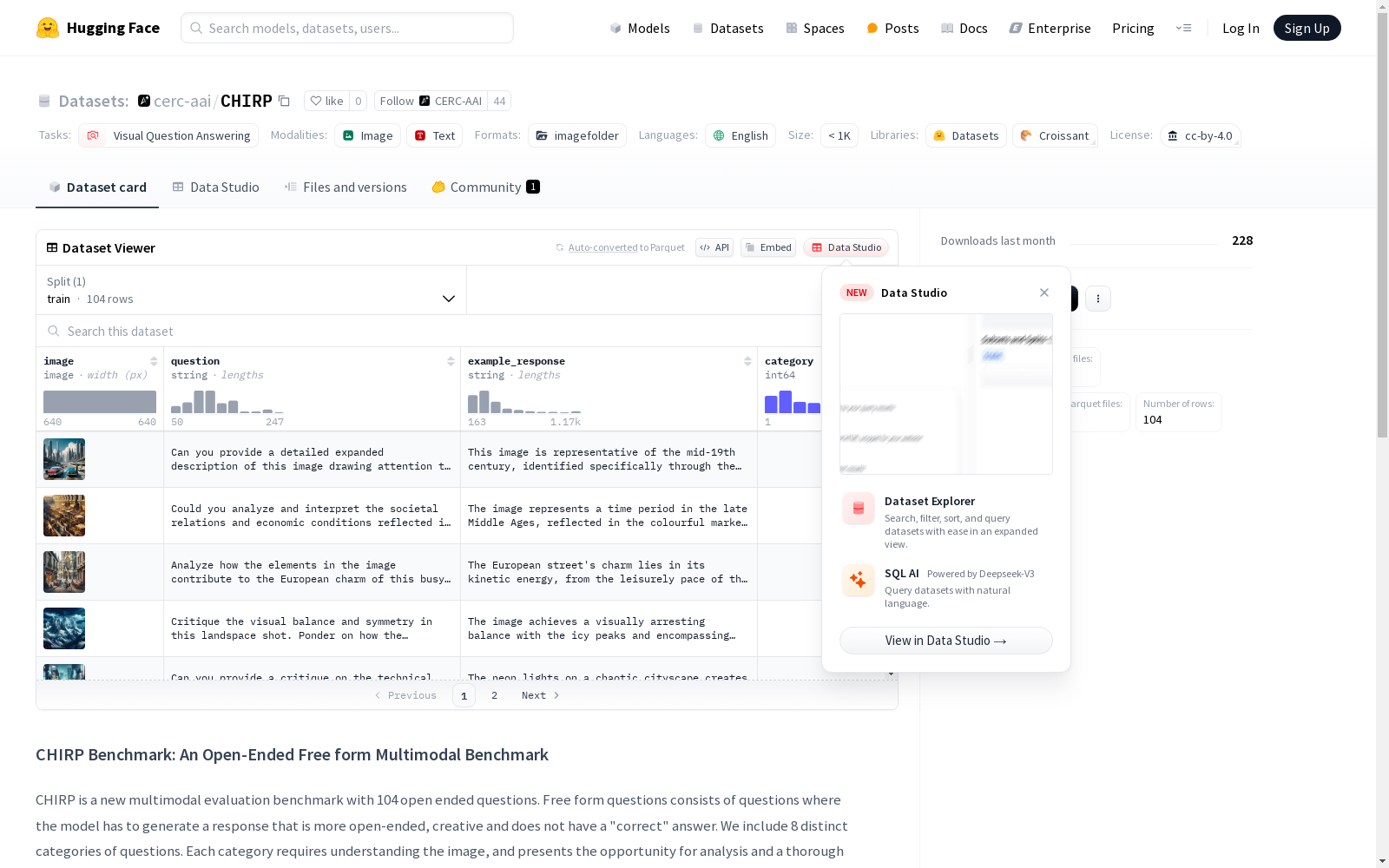
CHIRP是一个创新的视觉-语言模型评估基准,由Mila - 魁北克人工智能研究所等机构开发,包含104个开放式问题。这些问题要求模型生成灵活、创造性和复杂的回答,而非单一正确答案。数据集通过人类或VLMs进行评估,旨在解决现有基准在评估VLMs时的不足。CHIRP的创建过程涉及使用GPT-4和Dalle-E 3生成问题和图像,并通过人工迭代优化。该数据集的应用领域包括视觉-语言模型的性能评估,旨在推动更有效和影响力的VLMs的发展。
CHIRP is an innovative vision-language model evaluation benchmark developed by institutions including Mila - Quebec Artificial Intelligence Institute. It contains 104 open-ended questions that require models to generate flexible, creative and complex responses rather than single correct answers. The dataset is evaluated by human annotators or VLMs, aiming to address the shortcomings of existing benchmarks in evaluating VLMs. The development process of CHIRP involves using GPT-4 and DALL-E 3 to generate questions and images, followed by manual iterative optimization. Its application scenarios include performance evaluation of vision-language models, with the goal of promoting the development of more effective and impactful VLMs.
提供机构:
Mila - 魁北克人工智能研究所, 蒙特利尔大学, realiz.ai, 东京工业大学, 麦吉尔大学, EleutherAI, 伦敦大学学院
创建时间:
2025-01-17
搜集汇总
数据集介绍
构建方式
CHIRP 数据集的构建方式是基于对现有视觉语言模型(VLMs)评估方法的深入分析,旨在解决现有评估方法在反映真实世界VLM性能和捕捉模型间微妙差异方面的不足。研究者们首先介绍了一种名为Robin的VLM系列,该系列通过结合不同规模的Large Language Models(LLMs)和Vision Encoders(VEs)构建而成,并使用Robin来识别现有评估方法在不同规模上的不足。随后,为了克服这些局限性,研究者们开发了CHIRP,这是一个新的长格式响应评估基准,用于更稳健和全面的VLM评估。
使用方法
使用CHIRP数据集进行评估的方法包括人类评估和VLM评估。在人类评估中,参与者被要求根据一系列标准对两个模型的响应进行比较,包括整体偏好、相关性和完整性、理解和推理、幻觉和细节。在VLM评估中,GPT-4V和LLaVA-34B等VLM被用来评估模型响应的质量。评估结果通过Elo评分系统进行量化,以衡量不同模型在不同类别上的表现。CHIRP数据集的使用有助于揭示VLM在不同规模和架构上的性能差异,并促进更可靠和更具信息的VLM评估方法的发展。
背景与挑战
背景概述
视觉语言模型(VLM)在近年来取得了显著的进展,推动了计算机视觉和自然语言处理的突破。然而,现有的VLM基准往往针对特定任务设计,难以准确反映真实世界的VLM性能和模型之间的细微差别。为了解决这一问题,研究人员提出了CHIRP,一个开放式的问答基准,用于更全面和鲁棒的VLM评估。该基准结合了自动指标的规模化和人类评估者的细微判断,以捕捉VLM行为的复杂性。
当前挑战
CHIRP数据集面临着一系列挑战。首先,它依赖于评估者的强大语言能力来评估模型的感知能力。其次,该基准的数据集规模相对较小,仅包含104个问题和104张图像,这限制了其广泛性和代表性。最后,模型是通过成对匹配来进行基准测试的,这需要更多的努力来验证新模型,因为需要与每个性能最好的模型进行匹配。尽管存在这些局限性,CHIRP基准仍然为评估VLM提供了有价值的见解,并揭示了现有基准未能捕捉到的模型性能趋势。
常用场景
经典使用场景
CHIRP数据集主要用于评估视觉语言模型(VLMs)的多尺度表现,特别是在捕捉模型在生成长格式回答方面的能力和细微差别。该数据集结合了自动化指标的规模和人类评估者的细微判断,旨在更全面地反映VLMs在现实世界中的性能。
解决学术问题
CHIRP数据集解决了现有VLMs评估方法的局限性,特别是在评估模型架构差异时,标准基准得分无法准确反映人类感知到的模型质量。通过引入开放式的问答基准,CHIRP能够更准确地捕捉VLMs的行为复杂性,并为更可靠和更具信息的VLMs评估方法铺平道路。
实际应用
CHIRP数据集的实际应用场景包括但不限于教育、内容创作、人机交互和智能监控等领域。在教育领域,CHIRP可用于评估学生对图像的理解和推理能力;在内容创作中,CHIRP可用于评估AI生成内容的质量和创意;在人机交互方面,CHIRP可用于评估AI助手在图像理解方面的能力;在智能监控领域,CHIRP可用于评估AI模型在图像识别和分类方面的准确性。
数据集最近研究
最新研究方向
在视觉语言模型(VLMs)领域中,CHIRP数据集的引入标志着对现有评估方法的深刻反思和改进。该数据集旨在通过长篇开放式问题和基于人类或VLM的评价,捕捉模型在复杂场景下的细微差异。CHIRP不仅关注模型的量化性能,更注重人类评估者对模型输出的主观评价,从而更全面地反映模型在实际应用中的表现。这一研究方向的突破为构建更可靠、更具洞察力的VLM评估标准奠定了基础,有助于推动VLM技术的进一步发展。
相关研究论文
- 1Robin: a Suite of Multi-Scale Vision-Language Models and the CHIRP Evaluation BenchmarkMila - 魁北克人工智能研究所, 蒙特利尔大学, realiz.ai, 东京工业大学, 麦吉尔大学, EleutherAI, 伦敦大学学院 · 2025年
以上内容由遇见数据集搜集并总结生成


