webis/tldr-17
收藏Hugging Face2023-06-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/webis/tldr-17
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含从Reddit平台收集的预处理帖子,用于摘要生成任务。数据集包含3,848,330个帖子,平均内容长度为270个单词,摘要长度为28个单词。数据集的特征包括作者、正文、标准化正文、内容、摘要、子版块和子版块ID。数据集主要用于摘要生成任务,特别是抽象摘要生成。数据集的创建目的是为了补充现有的摘要生成数据集,特别是新闻类数据集。数据集的语言为英语,数据集的创建者通过过滤Reddit上的帖子来收集数据,并排除了由机器人生成的内容。
提供机构:
webis
原始信息汇总
数据集概述
名称: Reddit Webis-TLDR-17
描述: 该数据集包含从Reddit收集的预处理帖子,用于抽象摘要任务。数据集包含3,848,330个帖子,内容平均长度为270字,摘要平均长度为28字。
语言: 英语
许可: CC-BY-4.0
数据集大小:
- 下载大小: 3.14 GB
- 生成数据集大小: 18.94 GB
任务: 抽象摘要
评估指标: ROUGE
数据集结构
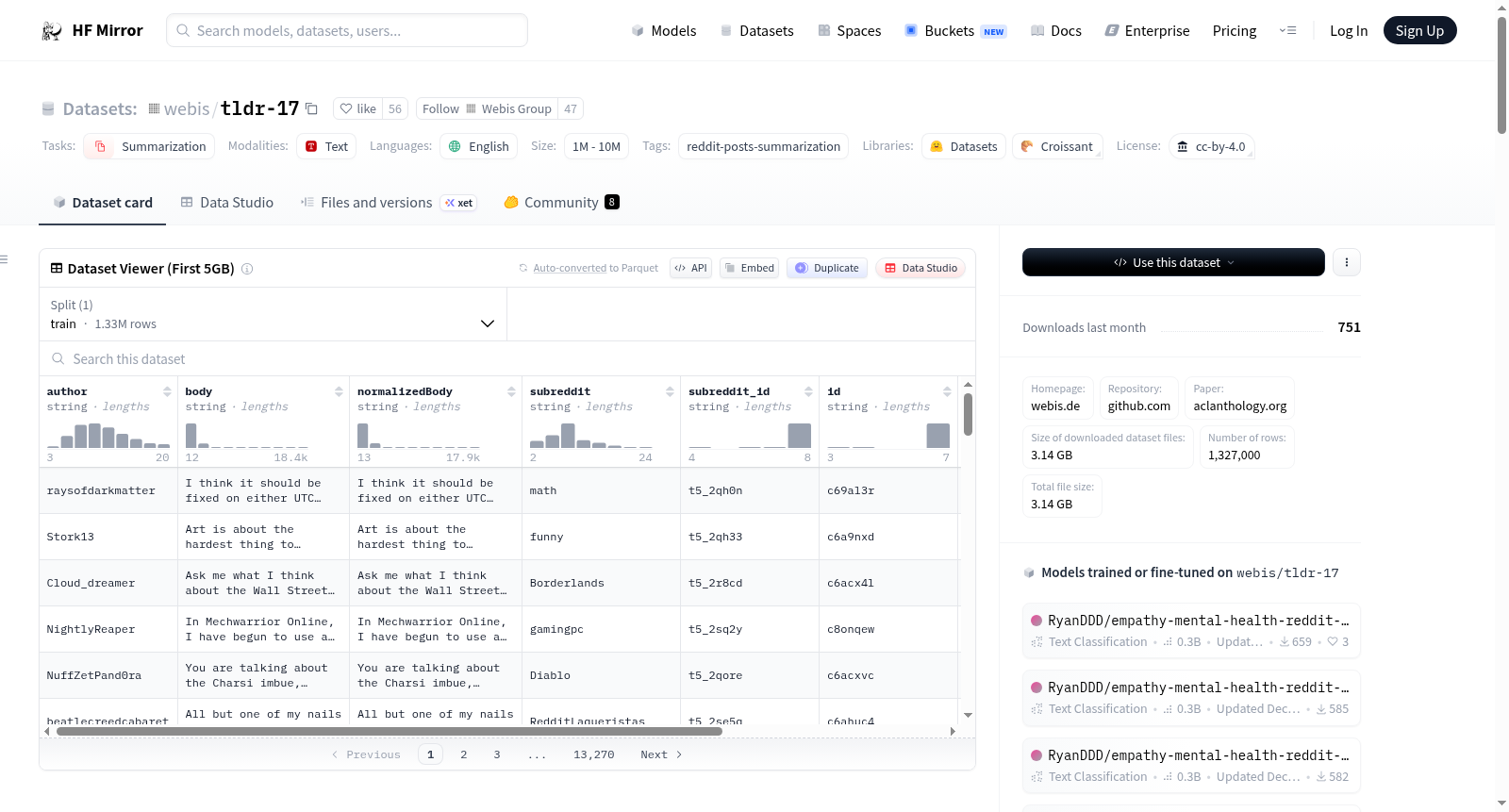
数据实例:
- 包含字段: author, body, normalizedBody, subreddit, subreddit_id, id, content, summary
- 数据类型: 所有字段均为字符串类型
数据分割:
- 训练集: 3,848,330个实例
数据集创建
源数据: 来自Reddit的帖子,包含"TL;DR"标记,时间范围为2006至2016年。
数据收集与规范化: 初始数据包括2.86亿个提交和16亿条评论,经过五步过滤流程处理。
数据标注: 数据集未提供具体的标注过程和标注者信息。
使用数据集的考虑
社会影响: 数据集旨在作为大规模摘要训练数据的来源,特别是针对抽象摘要任务。
已知限制: 数据集中可能包含滥用语言,且Reddit用户添加"TL;DR"的目的多样,可能影响摘要模型的训练。
搜集汇总
数据集介绍
构建方式
在自动文本摘要领域,高质量训练数据的匮乏长期制约着抽象式摘要模型的发展。Webis-TLDR-17数据集应运而生,其构建灵感源自社交媒体中用户自发为长文附加“TL;DR”摘要的普遍行为。研究者对2006年至2016年间Reddit平台上的2.86亿条帖文和16亿条评论进行大规模爬取,随后实施了一套包含五个阶段的严格过滤流程:首先筛选出包含“TL;DR”标记的帖文,继而剔除机器人账号生成的内容,并通过规范化处理、去重和质量评估等步骤,最终精选出3,848,330条高质量样本。每条样本均保留了作者、子版块、原始正文、规范化正文、摘要等结构化字段,为抽象式摘要研究提供了丰富的语料资源。
特点
该数据集在规模与多样性上展现出显著优势。其包含近四百万条训练样本,内容平均长度为270词,对应摘要平均长度为28词,形成了天然的长文本-短摘要映射关系。数据来源横跨Reddit平台多个子版块,覆盖科技、生活、娱乐等多元主题,有效弥补了传统摘要数据集多集中于新闻体裁的局限性。值得关注的是,数据集中的“TL;DR”摘要呈现出多种意图——既有真实的总结性描述,也包含提问、评价或结论性表述,这种异质性为探索多任务摘要学习提供了独特视角。此外,数据经过去除机器人内容等清洗处理,但需注意仍可能残留少量非规范性语言。
使用方法
该数据集主要面向抽象式文本摘要任务,用户可通过HuggingFace Datasets库便捷加载。调用`load_dataset('webis/tldr-17')`即可获取默认配置下的训练集,其中`content`字段作为待摘要文档,`summary`字段作为目标摘要。由于数据集未预设验证集和测试集划分,建议研究者按需自行分割,例如采用90%训练、5%验证、5%测试的比例。模型评估可采用ROUGE系列指标,已知基于Transformer+Copy机制的模型在该数据集上取得了ROUGE-1为22、ROUGE-2为6、ROUGE-L为17的基准成绩。数据加载后需注意`body`和`normalizedBody`字段可能为空,实际建模时主要依赖`content`与`summary`字段。
背景与挑战
背景概述
在自动文本摘要领域,抽象式摘要生成一直是自然语言处理中的核心挑战,其性能高度依赖于大规模、高质量的平行语料。然而,传统数据集多集中于新闻体裁,导致模型在多样化领域中的泛化能力受限。为突破这一瓶颈,德国魏玛大学等机构的研究人员Michael Völske、Martin Potthast等人于2017年提出了Webis-TLDR-17数据集。该数据集创新性地挖掘了Reddit社交平台中用户自带的“TL;DR”摘要,覆盖了2006年至2016年间约380万条帖子,平均内容长度达270词,摘要长度约28词。这一开创性工作不仅弥补了非新闻领域摘要语料的匮乏,还通过众包方式获取了天然的作者标注,为抽象式摘要研究提供了全新的训练资源,推动了模型在社区问答、技术讨论等多元场景下的应用探索。
当前挑战
当前Webis-TLDR-17数据集面临多重挑战。首先,在领域问题层面,摘要任务需应对Reddit帖子中语言风格的高度非正式性、主题碎片化及噪声干扰,例如用户撰写的TL;DR可能并非真实摘要,而是提问、评论或结论,导致训练数据标签质量参差不齐,模型难以学习到纯净的摘要映射关系。其次,构建过程中面临严峻的过滤难题:从2.86亿条帖子中通过五步流水线筛选,需精准剔除机器人账户、恶意内容及格式异常,但数据集仍可能存在少量不当语言,影响模型鲁棒性。此外,数据缺乏标准测试集划分,研究者需自行分割,导致评估结果难以统一比较,限制了该基准在社区中的可复现性与公平性。
常用场景
经典使用场景
Webis-TLDR-17数据集在文本摘要研究领域中被广泛用作大规模监督训练语料,尤其聚焦于抽象式摘要任务。该数据集源自Reddit平台上的海量用户帖子,通过挖掘作者自发撰写的“TL;DR”摘要,为模型提供了天然且高质量的文章-摘要对。其典型使用场景包括训练基于Transformer架构的生成式摘要模型,如结合复制机制的序列到序列网络,以及变分自编码器与指针生成网络的混合模型。研究者常利用该数据集评估模型在非新闻领域的泛化能力,因其内容涵盖多个子版块,题材多样,远超传统新闻摘要语料的范畴。
解决学术问题
该数据集的核心学术贡献在于缓解了自动文本摘要领域长期面临的训练数据匮乏与领域单一化问题。传统摘要数据集多集中于新闻体裁,导致模型在社交媒体、论坛讨论等非正式语境下表现欠佳。Webis-TLDR-17通过提供超过380万条来自Reddit的真实用户摘要,使研究者能够探索抽象式摘要在噪声更大、语言更随意、主题更分散的场景中的性能边界。此外,它还推动了关于摘要意图多样性的研究——区分“真实摘要”与提问、评论等非标准摘要类型,从而催生了基于摘要意图分类的细粒度任务设计。
衍生相关工作
Webis-TLDR-17衍生了一系列具有影响力的研究工作。其中,Gehrmann等人提出的Transformer+Copy模型在该数据集上取得了ROUGE-1为22的基准分数,验证了复制机制在生成式摘要中的有效性。Choi等人构建的Unified VAE+PGN架构则探索了变分自编码器与指针生成网络的融合路径,进一步提升了摘要的抽象性与忠实度。此外,该数据集还催生了关于社交媒体摘要中立场检测、情感保持以及多文档摘要的后续研究,成为评估模型在非规范文本上鲁棒性的重要测试平台,推动了摘要技术从新闻领域向更广泛社交媒体场景的拓展。
以上内容由遇见数据集搜集并总结生成


