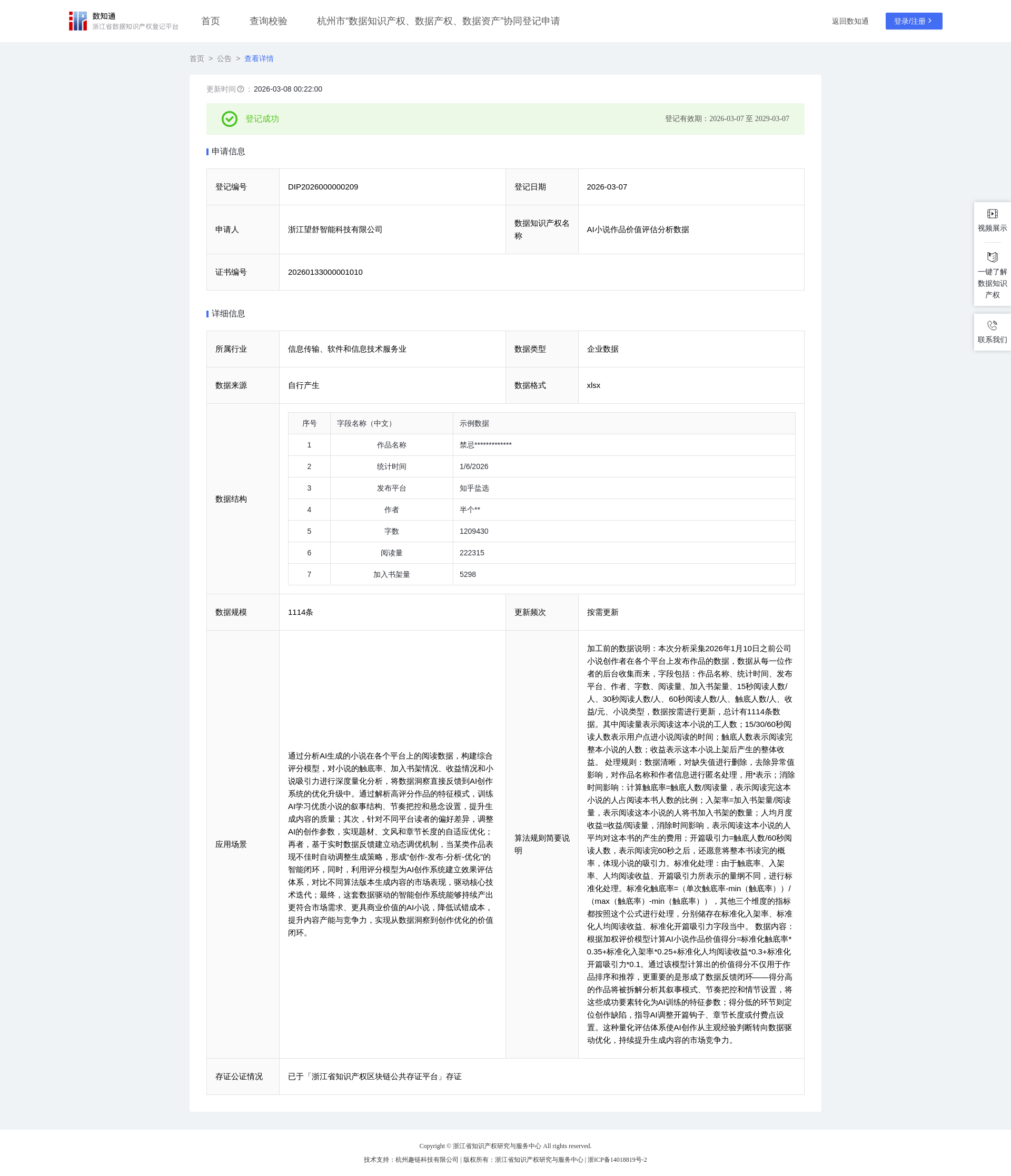
AI小说作品价值评估分析数据
收藏浙江省数据知识产权登记平台2026-03-08 更新2026-03-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8433793
下载链接
链接失效反馈官方服务:
资源简介:
通过分析AI生成的小说在各个平台上的阅读数据,构建综合评分模型,对小说的触底率、加入书架情况、收益情况和小说吸引力进行深度量化分析,将数据洞察直接反馈到AI创作系统的优化升级中。通过解析高评分作品的特征模式,训练AI学习优质小说的叙事结构、节奏把控和悬念设置,提升生成内容的质量;其次,针对不同平台读者的偏好差异,调整AI的创作参数,实现题材、文风和章节长度的自适应优化;再者,基于实时数据反馈建立动态调优机制,当某类作品表现不佳时自动调整生成策略,形成“创作-发布-分析-优化”的智能闭环,同时,利用评分模型为AI创作系统建立效果评估体系,对比不同算法版本生成内容的市场表现,驱动核心技术迭代;最终,这套数据驱动的智能创作系统能够持续产出更符合市场需求、更具商业价值的AI小说,降低试错成本,提升内容产能与竞争力,实现从数据洞察到创作优化的价值闭环。加工前的数据说明:本次分析采集2026年1月10日之前公司小说创作者在各个平台上发布作品的数据,数据从每一位作者的后台收集而来,字段包括:作品名称、统计时间、发布平台、作者、字数、阅读量、加入书架量、15秒阅读人数/人、30秒阅读人数/人、60秒阅读人数/人、触底人数/人、收益/元、小说类型,数据按需进行更新,总计有1114条数据。其中阅读量表示阅读这本小说的工人数;15/30/60秒阅读人数表示用户点进小说阅读的时间;触底人数表示阅读完整本小说的人数;收益表示这本小说上架后产生的整体收益。
处理规则:数据清晰,对缺失值进行删除,去除异常值影响,对作品名称和作者信息进行匿名处理,用*表示;消除时间影响:计算触底率=触底人数/阅读量,表示阅读完这本小说的人占阅读本书人数的比例;入架率=加入书架量/阅读量,表示阅读这本小说的人将书加入书架的数量;人均月度收益=收益/阅读量,消除时间影响,表示阅读这本小说的人平均对这本书的产生的费用;开篇吸引力=触底人数/60秒阅读人数,表示阅读完60秒之后,还愿意将整本书读完的概率,体现小说的吸引力。标准化处理:由于触底率、入架率、人均阅读收益、开篇吸引力所表示的量纲不同,进行标准化处理。标准化触底率=(单次触底率-min(触底率))/(max(触底率)-min(触底率)),其他三个维度的指标都按照这个公式进行处理,分别储存在标准化入架率、标准化人均阅读收益、标准化开篇吸引力字段当中。
数据内容:根据加权评价模型计算AI小说作品价值得分=标准化触底率*0.35+标准化入架率*0.25+标准化人均阅读收益*0.3+标准化开篇吸引力*0.1。通过该模型计算出的价值得分不仅用于作品排序和推荐,更重要的是形成了数据反馈闭环——得分高的作品将被拆解分析其叙事模式、节奏把控和情节设置,将这些成功要素转化为AI训练的特征参数;得分低的环节则定位创作缺陷,指导AI调整开篇钩子、章节长度或付费点设置。这种量化评估体系使AI创作从主观经验判断转向数据驱动优化,持续提升生成内容的市场竞争力。
By analyzing the reading data of AI-generated novels across various platforms, this work constructs a comprehensive scoring model to conduct in-depth quantitative analysis on the completion rate (bottom-out rate, i.e., the proportion of readers who finish the entire novel), bookshelf addition status, revenue performance, and novel attractiveness, and directly feeds the data insights into the optimization and upgrading of the AI creation system.
First, by analyzing the characteristic patterns of high-scoring works, the AI is trained to learn the narrative structure, rhythm control, and suspense setting of high-quality novels, thereby improving the quality of generated content. Second, in response to the preference differences of readers across different platforms, the AI's creation parameters are adjusted to achieve adaptive optimization of themes, writing styles, and chapter lengths. Furthermore, a dynamic tuning mechanism is established based on real-time data feedback, which automatically adjusts the generation strategy when certain types of works perform poorly, forming an intelligent closed loop of "creation - release - analysis - optimization". Additionally, the scoring model is used to establish an effect evaluation system for the AI creation system, compare the market performance of content generated by different algorithm versions, driving the iteration of core technologies. Finally, this data-driven intelligent creation system can continuously produce AI novels that better meet market demands and have higher commercial value, reduce trial-and-error costs, improve content production capacity and competitiveness, and realize the value closed loop from data insights to creation optimization.
### Pre-processing Data Description
The data for this analysis was collected from the backend of each author, covering works published by the company's novel creators across various platforms before January 10, 2026. The fields include: work name, statistical time, publishing platform, author, word count, reading volume, number of bookshelf additions, number of users who read for 15/30/60 seconds, number of users who finish the entire novel, revenue (yuan), and novel genre. The data is updated as needed, with a total of 1114 records. Among them, reading volume refers to the number of users who have read this novel; the number of users who read for 15/30/60 seconds refers to the number of users who spent at least 15/30/60 seconds after entering the novel; the number of users who finish the entire novel refers to those who have read the complete novel; revenue refers to the total revenue generated after this novel is launched on the shelves.
### Processing Rules
The data is cleaned first: missing values are deleted, the impact of outliers is removed, and work names and author information are anonymized using *.
Time effect elimination: Calculate the completion rate (bottom-out rate) = number of users who finish the entire novel / reading volume, which represents the proportion of readers who finish the entire novel among all readers; Bookshelf addition rate = number of bookshelf additions / reading volume, which represents the number of books added to the shelf by readers of this novel; Per capita reading revenue = revenue / reading volume, which eliminates time effects and represents the average revenue generated by each reader of this novel; Opening attractiveness = number of users who finish the entire novel / number of users who read for 60 seconds, which represents the probability that readers who have read for at least 60 seconds will finish the entire novel, reflecting the attractiveness of the novel.
Standardization processing: Since the four indicators (completion rate, bookshelf addition rate, per capita reading revenue, opening attractiveness) have different measurement units, standardization is performed. The formula for standardized indicator is: Standardized Indicator = (Single Indicator Value - Min(Indicator Values)) / (Max(Indicator Values) - Min(Indicator Values)). The other three indicators are processed using the same formula, and the results are stored in the fields of standardized bookshelf addition rate, standardized per capita reading revenue, and standardized opening attractiveness respectively.
### Data Content
The value score of AI novel works is calculated according to the weighted evaluation model: Value Score = Standardized Completion Rate * 0.35 + Standardized Bookshelf Addition Rate * 0.25 + Standardized Per Capita Reading Revenue * 0.3 + Standardized Opening Attractiveness * 0.1. The value scores calculated by this model are not only used for work ranking and recommendation, but more importantly, form a data feedback closed loop. Works with high scores will be disassembled and analyzed for their narrative patterns, rhythm control, and plot settings, and these successful elements will be transformed into feature parameters for AI training. Links with low scores will be positioned for creative defects, guiding the AI to adjust opening hooks, chapter length, or payment point settings. This quantitative evaluation system shifts AI creation from subjective empirical judgment to data-driven optimization, continuously improving the market competitiveness of generated content.
提供机构:
衢州望舒智能科技有限公司
创建时间:
2026-01-14
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集专注于AI生成小说的价值评估分析,基于1114条来自多个平台的作品数据,通过计算触底率、入架率、人均收益和开篇吸引力等标准化指标,构建加权评分模型来量化作品价值。其核心特点在于形成数据驱动的智能闭环,将高评分作品的叙事模式反馈给AI训练,同时针对低分作品调整创作参数,实现从市场表现到系统优化的持续迭代,旨在提升AI小说的质量和商业竞争力。
以上内容由遇见数据集搜集并总结生成


