stepfun-ai/GEdit-Bench
收藏Hugging Face2025-04-29 更新2025-05-31 收录
下载链接:
https://hf-mirror.com/datasets/stepfun-ai/GEdit-Bench
下载链接
链接失效反馈官方服务:
资源简介:
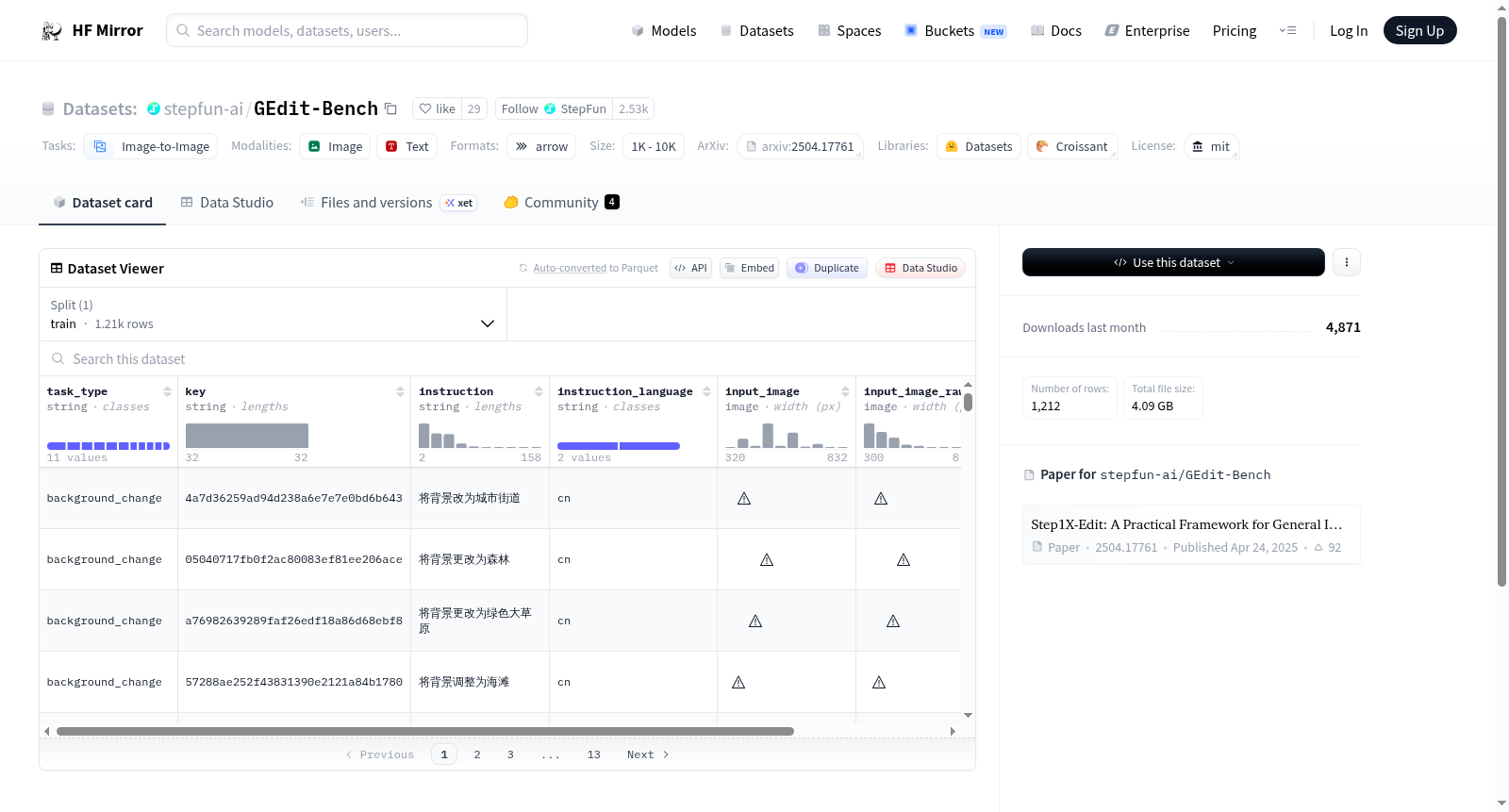
这是一个基于真实世界用例的新基准数据集,旨在支持对图像编辑模型进行更真实和全面的评估。
This dataset is a new benchmark, grounded in real-world usages, developed to support more authentic and comprehensive evaluation of image editing models.
提供机构:
stepfun-ai
搜集汇总
数据集介绍
构建方式
在图像编辑领域,评估模型的真实应用能力至关重要。GEdit-Bench数据集的构建基于实际使用场景,通过系统化的流程收集和整理图像编辑任务,确保数据来源的多样性和真实性。该数据集涵盖了广泛的编辑类型,包括风格转换、对象替换和内容修复等,每一类数据均经过人工筛选与标注,以构建一个全面且可靠的基准测试平台。
特点
GEdit-Bench数据集的特点在于其高度贴近现实应用,不仅包含了丰富的图像编辑案例,还注重编辑任务的复杂性和多样性。数据集中的图像覆盖了多种场景和对象,编辑指令清晰且具有挑战性,能够有效评估模型在真实世界中的泛化能力和编辑精度。这种设计使得该数据集成为推动图像编辑技术发展的有力工具。
使用方法
使用GEdit-Bench数据集时,研究人员可将其作为标准基准来测试和比较不同图像编辑模型的性能。数据集提供了详细的评估指标和指导,用户可以通过加载图像和对应的编辑指令,运行模型并分析输出结果,从而量化模型在各项任务上的表现。这种方法有助于推动图像编辑领域的创新与优化。
背景与挑战
背景概述
在计算机视觉领域,图像编辑技术正逐步从特定任务向通用化、实用化方向演进。stepfun-ai/GEdit-Bench数据集应运而生,由Stepfun AI团队于2025年创建,旨在为通用图像编辑模型提供一个基于真实使用场景的评估基准。该数据集的核心研究问题在于如何突破传统编辑任务在真实性、多样性及综合性方面的局限,推动模型在复杂现实环境中的实际应用能力。其构建依托于论文《Step1X-Edit: A Practical Framework for General Image Editing》所提出的框架,不仅促进了图像编辑技术的标准化评测,也为后续研究提供了关键的数据支撑,对提升编辑模型的泛化性能与实用价值产生了深远影响。
当前挑战
该数据集致力于解决通用图像编辑领域中的核心挑战,即如何使模型在多样化的真实场景中实现高质量、连贯且符合用户意图的编辑效果。具体而言,挑战体现在编辑任务需兼顾语义理解、局部细节保持与全局一致性,同时应对复杂光照、纹理及对象交互等变量。在构建过程中,团队面临数据采集与标注的艰巨性,需确保样本覆盖广泛的实际应用场景,并建立客观、全面的评估指标以量化模型性能。此外,平衡数据集的规模、多样性与标注质量,避免引入偏差或噪声,亦是构建过程中的关键难点。
常用场景
经典使用场景
在图像编辑领域,GEdit-Bench作为一个新兴的基准测试集,其经典使用场景聚焦于对通用图像编辑模型进行系统化、多维度的性能评估。该数据集根植于真实世界的编辑需求,涵盖了从对象替换、风格转换到复杂场景重构等多种编辑任务,为研究者提供了一个贴近实际应用的标准化测试平台,从而能够客观衡量模型在保持图像真实性与编辑一致性方面的能力。
解决学术问题
该数据集主要解决了图像编辑研究中长期存在的评估标准模糊与脱离实际应用的问题。通过构建一个基于真实使用场景的综合性基准,它使得学术界能够更准确地量化模型在语义理解、细节保真以及编辑可控性等方面的性能。这不仅推动了评估方法的规范化,也为图像生成与编辑技术的迭代优化提供了可靠的实证依据,促进了该领域研究从理论探索向实用化迈进。
衍生相关工作
围绕GEdit-Bench数据集,已衍生出若干重要的相关研究工作。其核心关联工作Step1X-Edit框架便是典型代表,该框架利用此基准进行模型训练与验证,提出了一种实用的通用图像编辑解决方案。此外,该基准的建立也激励了后续研究针对特定编辑子任务(如局部编辑、多轮编辑)开发更精细的评估指标与模型,共同丰富了图像编辑技术的研究生态。
以上内容由遇见数据集搜集并总结生成


