MFAQ
收藏arXiv2021-10-05 更新2024-06-21 收录
下载链接:
https://huggingface.co/datasets/clips/mfaq
下载链接
链接失效反馈官方服务:
资源简介:
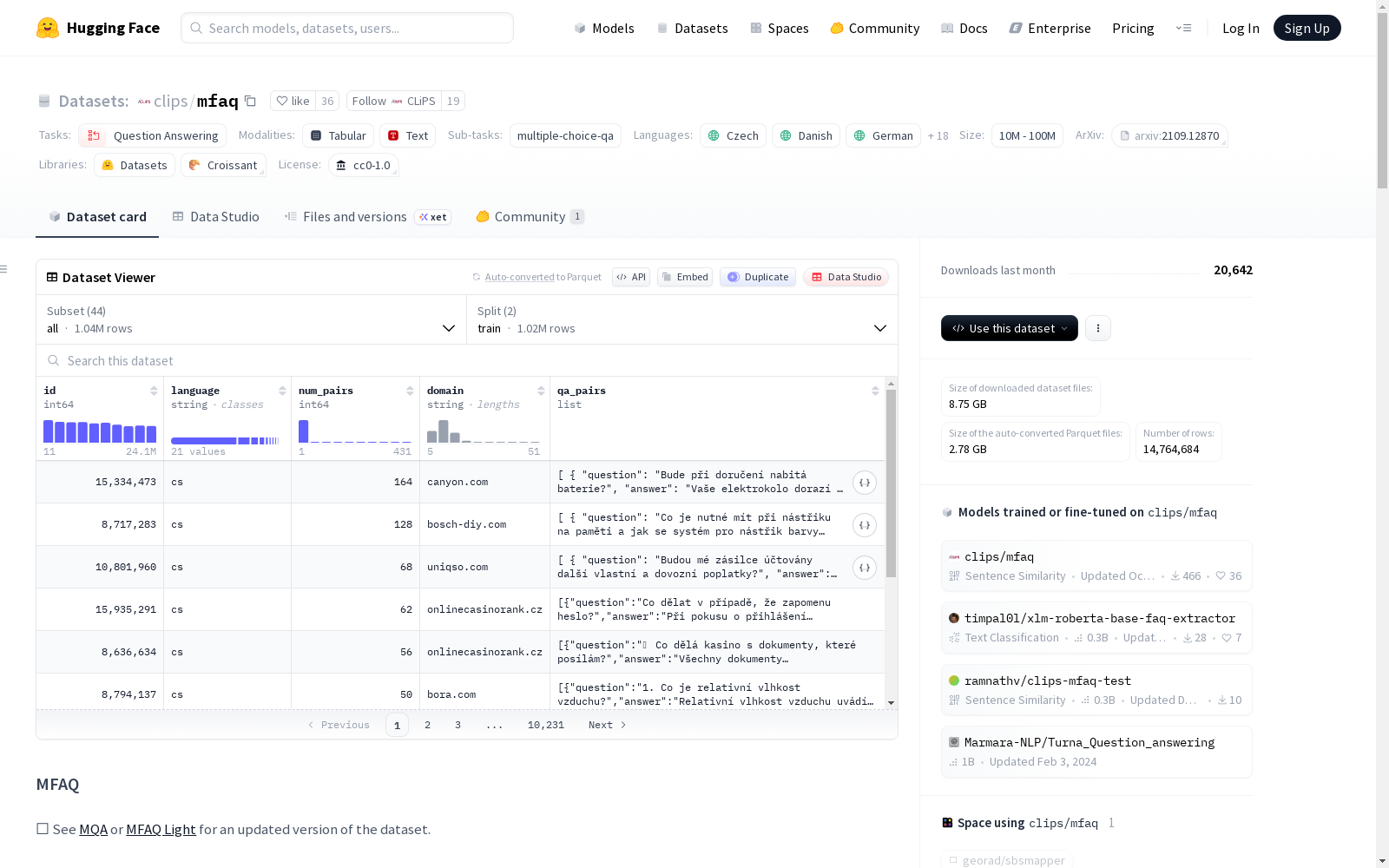
MFAQ是一个公开的多语言FAQ数据集,由CLiPS研究中心在安特卫普大学创建。该数据集从网络收集了约613万条FAQ对,涵盖21种不同语言,显著大于现有的FAQ检索数据集。MFAQ数据集面临内容重复和话题分布不均的挑战,但通过采用与Dense Passage Retrieval类似的设置,并测试多种双编码器,发现基于XLM-RoBERTa的多语言模型表现最佳。数据集的应用领域包括FAQ检索,旨在通过自动回答最常见问题,优化用户服务体验,如邮件、聊天机器人或搜索栏。
MFAQ is a publicly available multilingual FAQ dataset created by the CLiPS Research Center at the University of Antwerp. This dataset collects approximately 6.13 million FAQ pairs from the web across 21 distinct languages, and is significantly larger than existing FAQ retrieval datasets. The MFAQ dataset faces challenges including content duplication and uneven topic distribution. However, by adopting a setup similar to that of Dense Passage Retrieval and testing multiple dual encoders, it was found that multilingual models based on XLM-RoBERTa achieve the best performance. The application scenarios of the dataset include FAQ retrieval, which aims to optimize user service experiences such as those via emails, chatbots, or search bars by automatically answering frequently asked questions.
提供机构:
CLiPS研究中心,安特卫普大学,比利时
创建时间:
2021-09-27
搜集汇总
数据集介绍
构建方式
在构建MFAQ数据集时,研究团队采用了基于Common Crawl网络爬虫档案的大规模数据收集策略。通过解析网页HTML中的JSON-LD结构化标记,系统性地识别并提取了包含FAQPage语义标签的问答对。针对网络数据固有的冗余性问题,研究团队创新性地应用了MinHash近似匹配算法与局部敏感哈希技术,构建文档相似度图并进行子图分析,最终通过去重处理将原始数据从2400万页面精简至100万页面。数据涵盖21种语言,并通过基于根域分布与页面问答对密度的分层采样策略,构建了具有挑战性的验证集。
特点
MFAQ数据集作为首个公开的大规模多语言FAQ资源,其核心特征体现在规模与语言的多样性上。该数据集收录了约600万对问答数据,显著超越了现有FAQ检索数据集的规模。其语言覆盖范围广泛,包含英语、德语、西班牙语等21种语言,其中英语数据占比58%,形成了以英语为主导的多语言分布格局。数据源自超过100万个独立网页,涵盖约2.6万个根域,主题分布呈现自然的多领域特性。值得注意的是,数据集通过精心设计的去重与采样机制,有效缓解了内容重复与主题分布不均的问题,为模型训练提供了高质量且具有挑战性的评估基准。
使用方法
该数据集主要用于训练与评估FAQ检索模型,特别是基于稠密向量检索的跨语言问答系统。在使用时,通常将数据按语言与页面进行组织,采用双编码器架构进行训练。具体而言,模型以XLM-RoBERTa等多语言预训练模型为基础编码器,独立编码问题与答案文本,通过点积计算相似度得分。训练过程中采用批次内负样本与困难负样本相结合的策略,通过限制批次内语言一致性与页面内候选答案构建,增强模型对语义细微差别的区分能力。评估阶段则采用精确率@1、平均倒数排名等指标,在严格控制根域与语言交叉泄露的验证集上进行性能测试。
背景与挑战
背景概述
在自然语言处理领域,多语言FAQ检索作为提升跨语言信息服务效率的关键任务,长期以来受限于高质量数据集的匮乏。MFAQ数据集由安特卫普大学CLiPS研究中心于2021年发布,作为首个公开的大规模多语言FAQ数据集,其收录了涵盖21种语言、约600万条FAQ问答对,数据源自Common Crawl网络爬虫的JSON-LD结构化标记。该数据集的核心研究目标在于解决传统FAQ检索模型在跨语言场景下的泛化能力不足问题,通过构建统一的多语言评估基准,推动基于Transformer的稠密检索模型在非英语环境中的适应性研究。其发布显著填补了多语言FAQ数据资源的空白,为后续的跨语言语义匹配、低资源语言迁移学习等研究方向提供了重要支撑。
当前挑战
MFAQ数据集所针对的FAQ检索任务,面临语义匹配与语言多样性交织的双重挑战:一方面,用户查询与预设问题之间存在显著的表述差异,模型需克服词汇鸿沟并理解深层语义关联,而非依赖简单关键词重叠;另一方面,数据构建过程需应对网络源数据的固有缺陷,包括内容高度重复、主题分布不均以及低资源语言样本稀缺等问题。研究团队通过MinHash算法与局部敏感哈希进行去重处理,并设计基于根域与语言隔离的验证集划分策略,以缓解数据偏差对模型评估的影响。然而,数据集中关键语言如中文、日文的缺失,以及模型在指代消解与对抗性改写上的脆弱性,仍揭示了当前多语言FAQ检索系统在鲁棒性与覆盖广度上的局限。
常用场景
经典使用场景
在跨语言信息检索与智能客服系统领域,MFAQ数据集为研究者提供了大规模、多语言的常见问题对资源。该数据集最经典的应用场景在于训练和评估基于深度学习的FAQ检索模型,特别是采用双编码器架构的密集检索系统。研究者利用其涵盖21种语言的600万对问答数据,能够系统探究多语言模型在语义匹配任务上的泛化能力与跨语言迁移效应。通过将用户查询与候选答案库进行语义相似度计算,模型能够精准定位最相关的解答,为构建高效的多语言智能问答系统奠定数据基础。
实际应用
在实际应用层面,MFAQ数据集为构建企业级多语言智能客服系统提供了关键训练资源。组织可利用该数据集训练检索模型,将其部署于网站、聊天机器人或邮件自动回复系统,实现跨语言用户咨询的即时响应。例如,在旅游、电商等跨国业务场景中,系统能够自动匹配用户以不同语言提出的问题,从标准化FAQ库中检索出准确答案,显著降低人工客服成本并提升服务效率。数据集涵盖的多样化领域与真实网页来源确保了模型在实际应用中的泛化能力与实用性。
衍生相关工作
基于MFAQ数据集,研究者开展了一系列拓展性工作,推动了多语言检索技术的发展。相关研究重点探索了更高效的跨语言表示学习方法,以及在低资源语言上增强模型鲁棒性的技术路径。部分工作借鉴其数据构建范式,进一步扩充了非印欧语系语言的FAQ资源。同时,该数据集促进了针对FAQ检索特定挑战的模型改进,例如如何更好处理语义相近但表述不同的用户查询,以及如何减少模型对关键词的过度依赖。这些衍生研究共同丰富了多语言问答系统的技术体系与评估方法论。
以上内容由遇见数据集搜集并总结生成


