FinReflectKG
收藏FinReflectKG 数据集概述
数据集基本信息
- 名称: FinReflectKG
- 创建者: Domyn
- 语言: 英语
- 许可证: CC-BY-NC-4.0
- 数据规模: 1751万条规范化三元组
- 时间跨度: 2014-2024年
- 覆盖公司: 743家标普500公司
核心特征
- 从标普500公司10-K SEC文件中提取的大规模金融知识图谱数据集
- 每个三元组采用
(实体, 关系, 目标)格式表示结构化事实 - 包含时间边界和丰富的上下文信息
- 提供完整的文本上下文
- 实体和关系经过规范化处理
- 包含时间信息(开始/结束日期)
- 丰富的元数据,包括源文档信息
数据结构
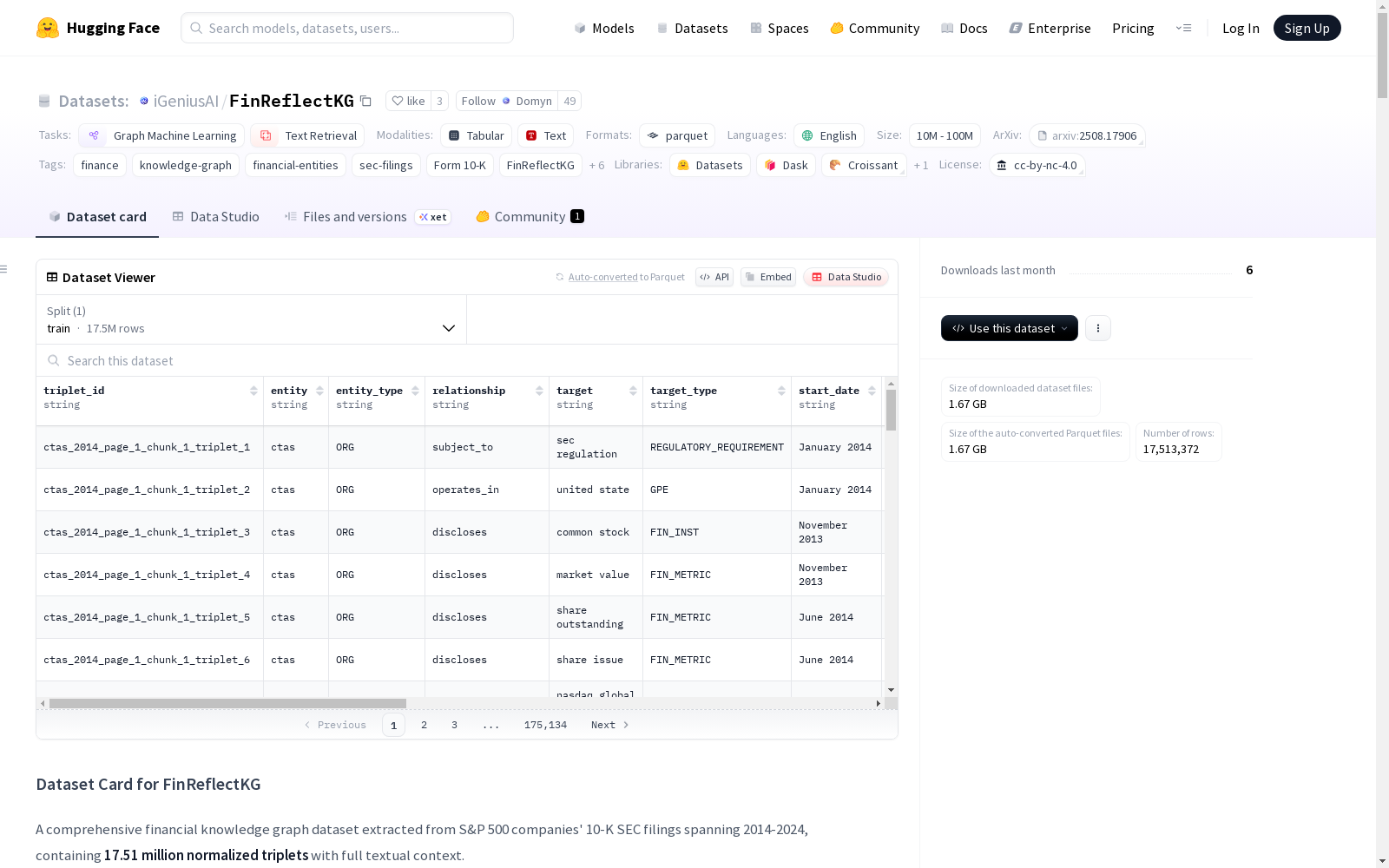
核心三元组组件
triplet_id: 每个三元组的唯一标识符entity: 命名实体(规范化)entity_type: 实体类别relationship: 关系类型(规范化)target: 目标实体(规范化)target_type: 目标实体类别start_date: 关系开始日期(月份 YYYY 格式)end_date: 关系结束日期(月份 YYYY 格式或"default_end_timestamp")extraction_type: 提取方法("default"或"extracted")
文档元数据
ticker: 公司股票代码year: 申报年份source_file: 原始PDF文件名page_id: PDF页面标识符chunk_id: 文本块标识符
上下文和特征
chunk_text: 三元组的完整文本上下文triplet_length: 三元组文本表示长度chunk_text_length: 上下文文本长度has_context: 是否提供上下文文本
时间信息
时间字段说明
- 格式: "月份 YYYY"(例如:"January 2024")
- 目的: 捕获每个关系的时间有效期
默认时间戳
当无法从文本上下文中可靠提取明确的时间信息时:
default_start_timestamp: 未提及或无法推断明确开始日期时使用default_end_timestamp: 未提及或无法推断明确结束日期时使用
提取类型分类
- "extracted": 开始日期和结束日期都成功从文本中提取
- "default": 开始日期或结束日期(或两者)使用默认值
实体类型
包含与财务文档相关的各种实体类型,包括ORG、ORG_GOV、ORG_REG、GPE、PERSON、COMP、PRODUCT、EVENT、SECTOR、ECON_IND、FIN_INST、FIN_MARKET、CONCEPT、RAW_MATERIAL、LOGISTICS、ACCOUNTING_POLICY、RISK_FACTOR、LITIGATION、SEGMENT、FIN_METRIC、ESG_TOPIC、MACRO_CONDITION、REGULATORY_REQUIREMENT、COMMENTARY
关系类型
包含金融知识图谱的全面关系类型,包括Has_Stake_In、Announces、Operates_In、Introduces、Produces、Regulates、Involved_In、Impacted_By、Impacts、Positively_Impacts、Negatively_Impacts、Related_To、Member_Of、Invests_In、Increases、Decreases、Depends_On、Causes_Shortage_Of、Affects_Stock、Stock_Decline_Due_To、Stock_Rise_Due_To、Market_Reacts_To、Discloses、Faces、Guides_On、Complies_With、Subject_To、Supplies、Partners_With
数据质量
- 99.08%的日期采用正确的"月份 YYYY"格式
- 经过规范化的实体和关系(使用词形还原)
- 去重后的三元组
- 过滤无效数据
- 全面的数据结构和完整性验证
时间覆盖
总三元组数: 17,513,372 年份范围: 2014-2024 公司数量: 743
| 年份范围 | 三元组数量 | 精确数量 | 公司数量 |
|---|---|---|---|
| 2014-2018 | 7.55M | 7,549,552 | 743 |
| 2019-2021 | 5.04M | 5,043,004 | 743 |
| 2022-2024 | 4.92M | 4,920,816 | 743 |
| 总计 | 17.51M | 17,513,372 | 743 |
应用场景
研究应用
- 金融自然语言处理:命名实体识别、关系提取
- 知识图谱构建:构建金融知识库
- 时间分析:研究金融关系随时间的变化
- 风险评估:分析风险因素及其演变
- 合规研究:理解监管关系
行业应用
- 金融情报:SEC文件的自动化分析
- 尽职调查:全面的公司关系映射
- ESG分析:环境、社会和治理洞察
- 市场研究:理解竞争格局
- 监管技术:合规和风险监控
数据来源
数据集源自标普500公司向SEC提交的10-K年度报告
伦理考虑
- 公共数据:所有源数据都是公开可用的SEC文件
- 无个人信息:专注于公司和金融实体
- 监管合规:尊重SEC披露要求
- 研究用途:用于学术和研究目的
引用
bibtex @article{arun2025finreflectkg, title={FinReflectKG: Agentic Construction and Evaluation of Financial Knowledge Graphs}, author={Arun, Abhinav and Dimino, Fabrizio and Agarwal, Tejas Prakash and Sarmah, Bhaskarjit and Pasquali, Stefano}, journal={arXiv preprint arXiv:2508.17906}, year={2025}, url={https://arxiv.org/pdf/2508.17906} }
联系方式
Reetu Raj Harsh (reeturaj.harsh@domyn.com)