MASKGROUPS-2M, MASKGROUPS-HQ
收藏arXiv2025-06-06 更新2025-06-07 收录
下载链接:
https://Ref2Any.github.io
下载链接
链接失效反馈官方服务:
资源简介:
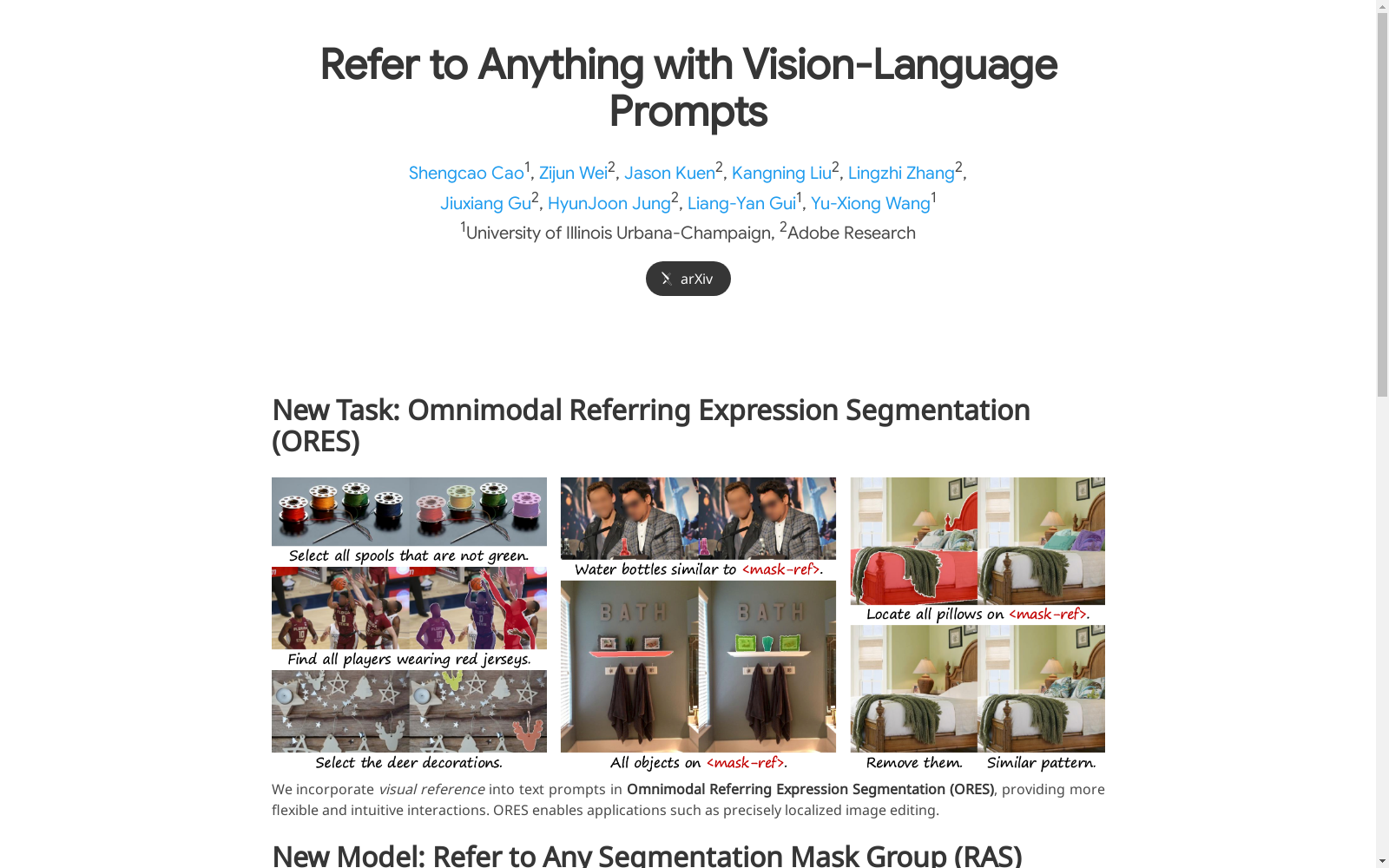
本研究引入了一种新型的视觉语言任务,称为全模式指代表达式分割(ORES),该任务要求模型根据文本或文本加参考视觉实体的提示生成一组相关的掩码。为此,我们提出了一个名为“参考任何分割掩码组”(RAS)的框架,它通过掩码中心的大多模态模型增强分割掩码的语义理解,并生成满足用户指定指令的掩码组。为了训练和评估ORES模型,我们创建了数据集MASKGROUPS-2M和MASKGROUPS-HQ,这些数据集包含由文本和参考实体指定的多样化掩码组。通过广泛评估,我们证明了RAS在我们的新ORES任务以及经典的指代表达式分割(RES)和广义指代表达式分割(GRES)任务上的优越性能。
This study introduces a novel vision-language task named Full-Modal Referring Expression Segmentation (ORES), which mandates models to generate a set of relevant masks based on textual prompts or prompts integrating text and reference visual entities. To address this task, we propose a framework called Referring Any Segmentation Mask Groups (RAS), which employs a mask-centered multimodal large model to enhance the semantic understanding of segmentation masks and generate mask groups that comply with user-specified instructions. For training and evaluating ORES models, we construct two datasets: MASKGROUPS-2M and MASKGROUPS-HQ, which contain diverse mask groups specified by text and reference entities. Through extensive experimental evaluations, we demonstrate that RAS achieves superior performance on our newly proposed ORES task, as well as the classic Referring Expression Segmentation (RES) and Generalized Referring Expression Segmentation (GRES) tasks.
提供机构:
伊利诺伊大学香槟分校和Adobe
创建时间:
2025-06-06
搜集汇总
数据集介绍
构建方式
MASKGROUPS-2M和MASKGROUPS-HQ数据集的构建基于现有图像数据集的对象级注释,通过自动转换和人工标注相结合的方式完成。MASKGROUPS-2M通过模板化方法从MS-COCO、LVIS、Visual Genome等数据集中提取类别、属性和位置信息,生成多样化的掩码组。MASKGROUPS-HQ则由专业标注人员基于EntitySeg数据集的高质量掩码标注,提出有意义的视觉实体组并标注对应的掩码,确保数据的高质量和多样性。
特点
这两个数据集的特点在于其多样性和高质量。MASKGROUPS-2M包含200万个样本,覆盖了广泛的视觉实体和复杂的查询条件,适用于大规模视觉指令调优。MASKGROUPS-HQ则通过人工标注确保了数据的准确性和实用性,特别适用于需要精细语义理解的场景。数据集支持文本和视觉提示的混合输入,增强了模型的表达能力和灵活性。
使用方法
MASKGROUPS-2M主要用于视觉指令调优,训练模型理解和生成复杂的掩码组。MASKGROUPS-HQ则用于模型微调和评估,确保模型在实际应用中的表现。用户可以通过文本或视觉提示指定查询条件,模型将返回满足条件的掩码组。这些数据集特别适用于需要细粒度视觉定位和多模态交互的应用场景,如图像编辑、自动驾驶和增强现实。
背景与挑战
背景概述
MASKGROUPS-2M和MASKGROUPS-HQ是由伊利诺伊大学厄巴纳-香槟分校和Adobe的研究团队于2025年提出的数据集,旨在支持全模态参考表达分割(Omnimodal Referring Expression Segmentation, ORES)任务。该任务扩展了传统的参考表达分割(RES)和广义参考表达分割(GRES)任务,通过结合视觉和语言提示来实现更灵活和实用的交互。这些数据集的创建填补了现有图像分割模型在复杂多模态理解方面的不足,为自动驾驶、机器人技术、增强现实和图像编辑等应用提供了重要支持。
当前挑战
MASKGROUPS-2M和MASKGROUPS-HQ面临的挑战主要包括:1) 领域问题的挑战:现有的图像分割模型难以处理复杂的多模态提示(如结合文本和视觉实体的参考表达),导致在需要细粒度语义理解的场景中表现不佳;2) 构建过程中的挑战:数据集的构建需要从现有数据集中重新利用对象级注释,并通过模板生成多样化的掩码组,同时确保高质量和多样性。此外,人工标注的MASKGROUPS-HQ数据集需要专家标注者提出有意义的视觉实体组,并确保标注的一致性和准确性。
常用场景
经典使用场景
MASKGROUPS-2M和MASKGROUPS-HQ数据集在计算机视觉领域,特别是多模态图像分割任务中具有广泛的应用。这些数据集通过结合视觉和语言提示,支持复杂的图像分割任务,如根据自然语言描述或参考视觉实体进行目标分割。其经典使用场景包括图像编辑、增强现实和机器人视觉导航,其中模型需要根据用户提供的多模态提示精确分割图像中的多个目标。
衍生相关工作
基于MASKGROUPS-2M和MASKGROUPS-HQ数据集,研究者们开发了多种先进的多模态分割模型,如RAS(Refer to Any Segmentation Mask Group)框架。这些模型不仅在传统的指代表达分割(RES)和广义指代表达分割(GRES)任务中表现出色,还在新兴的全模态指代表达分割(ORES)任务中取得了突破性进展。此外,这些数据集还促进了多模态大语言模型(LMM)在视觉任务中的应用和研究。
数据集最近研究
最新研究方向
近年来,MASKGROUPS-2M和MASKGROUPS-HQ数据集在计算机视觉领域引起了广泛关注,特别是在多模态视觉语言任务中。这些数据集通过结合文本和视觉提示,实现了对复杂查询的全面语义理解,推动了全模态参考表达分割(ORES)任务的发展。ORES任务不仅扩展了传统的参考表达分割(RES)和广义参考表达分割(GRES)任务,还通过引入视觉语言提示,提供了更灵活和实用的交互方式。这一研究方向在自动驾驶、机器人技术、增强现实和图像编辑等领域具有重要的应用价值。
相关研究论文
- 1Refer to Anything with Vision-Language Prompts伊利诺伊大学香槟分校和Adobe · 2025年
以上内容由遇见数据集搜集并总结生成


