mls-mimi-codes
收藏Hugging Face2026-04-28 更新2026-04-29 收录
下载链接:
https://huggingface.co/datasets/shangeth/mls-mimi-codes
下载链接
链接失效反馈官方服务:
资源简介:
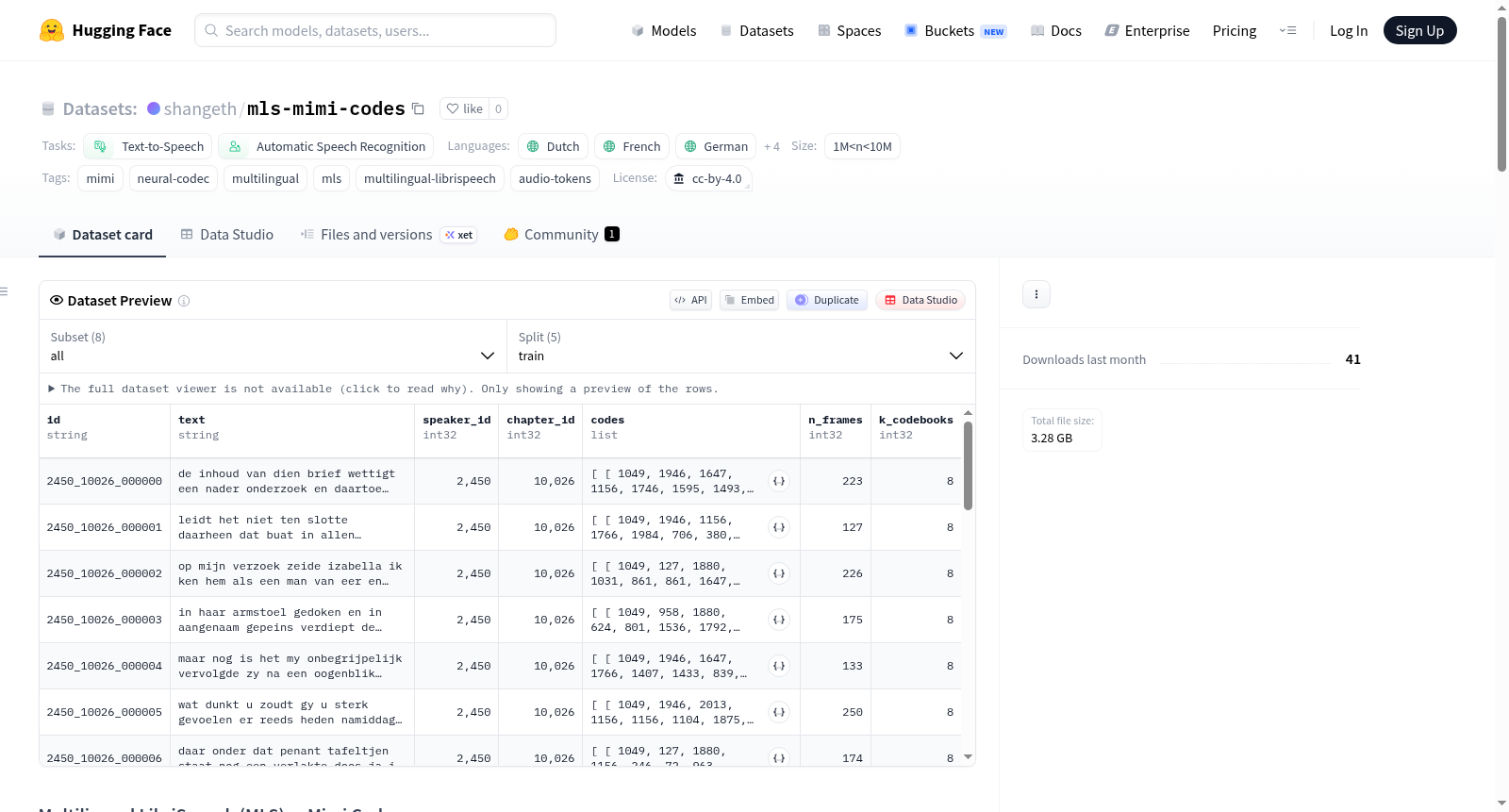
Multilingual LibriSpeech (MLS) Mimi Codes 数据集是一个专为文本到语音(TTS)和自动语音识别(ASR)任务设计的多语言数据集。该数据集包含从 LibriVox 有声读物中提取的七种非英语语言(荷兰语、法语、德语、意大利语、波兰语、葡萄牙语和西班牙语)的神经编解码器标记。数据集按语言配置组织,每种语言包含训练集(train)、开发集(dev)、测试集(test)以及两个低资源子集(9_hours 和 1_hours)。此外,还提供了一个虚拟的“all”配置,用于训练单一多语言模型。数据集的每条记录包含以下字段:ID(utterance ID)、文本(转录文本)、说话者ID、章节ID、编解码器索引(codes)、帧数(n_frames)和编解码器数量(k_codebooks)。编解码器标记使用 Kyutai Mimi 模型在 24 kHz 下提取,帧率为 12.5 fps。该数据集适用于多语言语音合成和识别研究,尤其适合需要处理非英语语音的任务。
创建时间:
2026-04-28
原始信息汇总
Multilingual LibriSpeech (MLS) Mimi Codes 数据集详情
数据集概述
该数据集是预先提取的 Kyutai Mimi 神经编解码器(neural-codec)令牌,基于 Multilingual LibriSpeech (MLS) 数据集,涵盖7种非英语语言的 LibriVox 有声书音频。数据集明确排除了英语内容。
数据集信息
| 属性 | 内容 |
|---|---|
| 许可证 | CC-BY-4.0 |
| 任务类别 | 文本转语音(TTS)、自动语音识别(ASR) |
| 语言 | 荷兰语、法语、德语、意大利语、波兰语、葡萄牙语、西班牙语 |
| 标签 | mimi、neural-codec、多语言、MLS、多语言LibriSpeech、音频令牌 |
| 数据规模 | 100万至1000万条记录 |
数据集语言配置(Configs)
数据集为每种语言提供了一个独立的 Hugging Face 数据集配置:
| 配置名称 | 语言 | ISO代码 | 训练集大约时长 |
|---|---|---|---|
dutch |
荷兰语 | nl | 约1500小时 |
french |
法语 | fr | 约1100小时 |
german |
德语 | de | 约3300小时 |
italian |
意大利语 | it | 约250小时 |
polish |
波兰语 | pl | 约100小时 |
portuguese |
葡萄牙语 | pt | 约160小时 |
spanish |
西班牙语 | es | 约920小时 |
此外,还提供一个虚拟的 all 配置,用于训练单一的多语言模型。
数据集划分(Splits)
每种语言配置包含以下数据划分:
| 划分名称 | 描述 |
|---|---|
train |
完整训练集 |
dev |
开发集 |
test |
测试集 |
9_hours |
低资源训练子集(约9小时) |
1_hours |
低资源训练子集(约1小时) |
数据模式(Schema)
每条记录包含以下字段:
| 字段 | 类型 | 说明 |
|---|---|---|
id |
字符串 | 话语ID,格式:{说话人}_{章节}_{片段} |
text |
字符串 | 文本转录(保留原始大小写) |
speaker_id |
整数 | 说话人ID |
chapter_id |
整数 | 章节ID |
codes |
整型数组 [8][帧数] |
Mimi 码书索引,帧率12.5 fps |
n_frames |
整数 | 帧数 |
k_codebooks |
整数 | 码书数量(固定为8) |
提取技术细节
- 编解码器: Kyutai Mimi,采样率24 kHz,帧率12.5 fps
- 音频重采样: MLS 原始音频为48 kHz Opus格式,提取时重采样至24 kHz
- 码书: 全部8个码书均已提取,可通过
codes[:k]切片获取部分码书 - 数据来源: Facebook 的 Multilingual LibriSpeech 数据集
使用示例
python from datasets import load_dataset import torch
ds = load_dataset("shangeth/mls-mimi-codes", "german", split="dev") ex = ds[0] codes = torch.tensor(ex["codes"], dtype=torch.long) # [8, n_frames] print(ex["id"], "| speaker:", ex["speaker_id"], "|", ex["text"][:60])
解码回24 kHz音频
from transformers import MimiModel mimi = MimiModel.from_pretrained("kyutai/mimi").cuda().eval() with torch.no_grad(): wav = mimi.decode(codes.unsqueeze(0).cuda()).audio_values[0].cpu()
注意事项
- 使用
all配置时,数据集中没有language字段,且speaker_id仅在各自语言内有效,不同语言间的说话人ID可能冲突 - 如需按语言清晰管理说话人,建议分别加载每种语言的配置
搜集汇总
数据集介绍
构建方式
该数据集基于Facebook发布的多语种LibriSpeech(MLS)语料库构建,通过Kyutai开发的Mimi神经编解码器对原始音频进行预处理。原始音频采样率为48 kHz,首先被重采样至24 kHz,随后由Mimi模型以每秒12.5帧的速率提取8个码本(codebook)的离散音频令牌(tokens)。数据集涵盖了荷兰语、法语、德语、意大利语、波兰语、葡萄牙语和西班牙语七种非英语语言,每个语言配置均包含完整的训练集(train)、开发集(dev)、测试集(test),以及约9小时和1小时的低资源训练子集。此外,还提供了一个合并的'all'配置,通过全局通配符将各语言数据聚合,便于多语种联合模型训练。
特点
数据集的核心特点在于其将大规模多语种语音数据转化为紧凑的神经编解码令牌表示,每个样本包含8个码本索引序列,帧率固定为12.5 fps,可灵活裁剪至任意码本数量以适配不同任务需求。数据规模庞大,总训练时长超过7,000小时,且保留了原始语料库中说话人ID、章节ID和文本转录等元信息。值得注意的是,数据集特意排除了英语,专注于非英语语种,为多语种语音合成(TTS)和自动语音识别(ASR)研究提供了标准化资源。所有数据均采用CC-BY-4.0许可协议,确保了学术与商业使用的灵活性。
使用方法
推荐通过HuggingFace Datasets库加载数据,支持按语言配置或合并配置('all')灵活读取。加载后,每个样本的'codes'字段为形状[8, n_frames]的int16数组,可直接转换为PyTorch张量用于模型输入。解码时,需配合HuggingFace Transformers库中的MimiModel,将令牌序列输入模型即可重建为24 kHz的波形音频。对于多语种联合训练,使用'all'配置时需注意各语言间说话人ID可能冲突,建议在需要精细管理说话人信息的场景下单独加载各语言配置。数据集预置了1小时和9小时的低资源子集,便于快速原型验证和少样本学习实验。
背景与挑战
背景概述
多语言语音处理领域的发展长期受限于高质量、大规模标注语料库的匮乏,尤其是非英语语言资源的不平衡严重阻碍了跨语言语音技术的进步。在此背景下,Multilingual LibriSpeech (MLS) Mimi Codes数据集应运而生,该数据集由Shangeth Rajaa等人基于Facebook于2020年发布的MLS语料库构建,利用Kyutai Mimi神经编解码器对七种非英语语言(荷兰语、法语、德语、意大利语、波兰语、葡萄牙语、西班牙语)的有声读物音频进行预编码,旨在为多语言文本转语音与自动语音识别研究提供标准化的音频令牌表示。作为连接大规模多语言原始语音与高效神经编解码表示的桥梁,该数据集为统一多语言语音建模提供了关键资源,显著推动了跨语言语音系统通用范式的探索。
当前挑战
该数据集所解决的核心领域挑战在于多语言语音表征的高效统一建模,传统方法需分别处理各语言的声学与音系特征,而基于神经编解码的令牌化方案虽能压缩语音信息,却面临不同语言音素分布与韵律结构差异带来的编码效率问题。在构建过程中,主要挑战包括:从MLS语料库中处理48kHz Opus格式音频至24kHz重采样时的保真度控制,确保编解码器各码本索引的完整提取;多语言混合训练时需协调各语种特有的说话人ID冲突问题,避免跨语言说话人身份混淆;同时为支持低资源场景研究,需在低至1至9小时的训练子集中维持语音多样性,这对编解码器的泛化能力提出了严苛要求。
常用场景
经典使用场景
在当今多语言语音处理领域,预训练神经编解码器已成为连接连续语音信号与离散表示空间的关键桥梁。mls-mimi-codes数据集作为Multilingual LibriSpeech的配套资源,为研究者提供了覆盖荷兰语、法语、德语、意大利语、波兰语、葡萄牙语和西班牙语七种语言的预提取Mimi模型音频令牌,每帧包含8个码本索引,帧率为12.5fps。其经典使用场景聚焦于多语言神经语音编解码与生成任务,研究人员可直接利用这些离散化表示训练统一的文本到语音或自动语音识别模型,无需重复处理原始音频数据。数据集的‘all’配置支持跨语言联合训练,而细粒度的‘9_hours’和‘1_hours’子集则为低资源语言场景下的模型鲁棒性评估提供了标准测试床。该格式与HuggingFace Datasets和Transformers库无缝衔接,通过调用MimiModel的decode方法即可将令牌高效还原为24kHz音频信号,极大简化了从特征提取到生成验证的全流程链路。
衍生相关工作
作为多语言神经音频令牌库的关键组成部分,mls-mimi-codes衍生出了一系列富有影响力的研究工作。在统一语音-文本建模方向,Wren系列模型直接依托该数据集进行预训练,通过离散音频令牌与文本令牌的联合学习实现了跨模态的语义对齐,开辟了小规模开放权重模型在多语言口语理解任务中的新路径。在低资源语音处理领域,该数据集启发了基于令牌级数据增强与课程学习策略的学术探索,研究者利用其分层子集设计渐进式训练方案,验证了从1小时到完整训练集规模下模型性能的缩放规律。在跨语言说话人验证方面,该数据集对speaker_id潜在冲突的明确标注促使学者研发了语言无关的说话人嵌入方法,通过对比学习解耦语言与身份特征。此外,它还作为基准被广泛应用于神经编解码器的码本利用率分析与离散表示质量评估,推动了诸如残差矢量量化优化和码本共享机制等后续改进工作的开展。
数据集最近研究
最新研究方向
在当前多模态语音处理的前沿阵地上,mls-mimi-codes数据集通过提供七种非英语语言(荷兰语、法语、德语、意大利语、波兰语、葡萄牙语、西班牙语)的神经编解码器(Neural Codec)标记,为多语言统一语音建模开辟了崭新路径。该数据集创新性地抽取并存储了来自Kyutai Mimi模型的高质量音频标记,使得研究人员能够无缝训练单一模型处理多种语言,核心解决了跨语言语音表示学习的瓶颈问题。随着Wren等小规模开放权重模型的提出,这一资源正推动着从传统文本到语音(TTS)和自动语音识别(ASR)的分离式研究,迈向更为高效、统一的语音-文本联合建模范式。其内置的低资源子集(1小时与9小时)更呼应了少样本学习的热潮,为资源稀缺语种的语音技术突破提供了关键支撑。
以上内容由遇见数据集搜集并总结生成


