ViANLI
收藏Hugging Face2025-10-23 更新2025-10-24 收录
下载链接:
https://huggingface.co/datasets/uitnlp/ViANLI
下载链接
链接失效反馈官方服务:
资源简介:
ViANLI(越南语对抗性自然语言推理)是第一个针对越南语NLI的抗性基准数据集,旨在评估模型在面对复杂语言现象时的鲁棒性。该数据集通过人类与机器相结合的方式,并经过多轮对抗性生成和双重人类-机器验证构建而成,包含了超过10,000个高质量的前提-假设对,覆盖了来自越南新闻文章的13个不同领域。每个前提-假设对都按照标准的NLI框架被标记为蕴含、矛盾或中立。
创建时间:
2025-10-22
原始信息汇总
ViANLI 数据集概述
数据集简介
ViANLI(越南语对抗性自然语言推理)是首个针对越南语NLI的对抗性基准数据集,旨在评估模型对复杂语言现象的鲁棒性。该数据集采用人机协同方法和多轮对抗生成机制,经过双重人机验证。包含超过10,000个高质量的前提-假设对,涵盖越南新闻文章的13个不同领域。
语言信息
- 越南语(vi)
数据特征
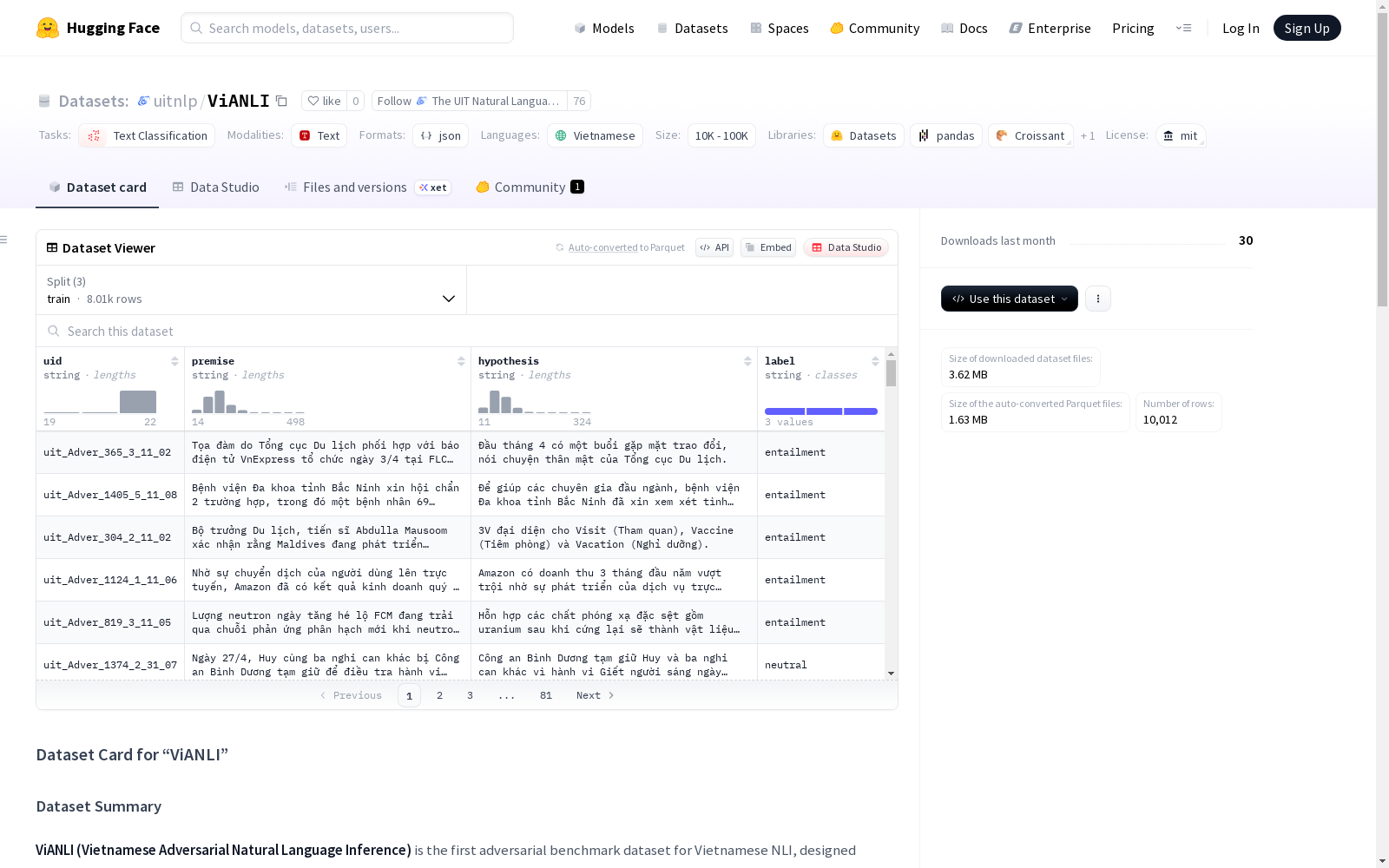
实例结构
每个实例为JSON行格式,包含以下字段:
uid:字符串类型,实例唯一标识符premise:字符串类型,从越南新闻提取的前提句子hypothesis:字符串类型,标注者编写的假设句子label:字符串类型,三类标签之一:entailment、neutral、contradiction
数据划分
| 划分 | 数量 |
|---|---|
| 训练集 | 8,012 |
| 验证集 | 1,000 |
| 测试集 | 1,000 |
许可信息
- 许可证:CC BY-NC-SA 4.0(知识共享署名-非商业性使用-相同方式共享4.0国际许可协议)
引用格式
bibtex @article{tin2025vianli, title={A New Benchmark Dataset and Mixture-of-Experts Language Models for Adversarial Natural Language Inference in Vietnamese}, author={Tin Van Huynh, Kiet Van Nguyen and Ngan Luu-Thuy Nguyen}, journal={Expert Systems with Applications}, year={2025}, publisher={Elsevier} }
搜集汇总
数据集介绍
构建方式
在自然语言推理领域,构建对抗性基准数据集对于评估模型鲁棒性至关重要。ViANLI采用人机协同循环策略,通过多轮对抗生成机制,从越南新闻语料中提取前提句,并由标注者撰写假设句。所有数据均经过双重人工与机器验证流程,确保超过一万个前提-假设对在语义逻辑上的精确性,涵盖新闻、法律、文化等13个专业领域,最终形成符合国际标注规范的三分类标签体系。
特点
作为越南语首个人工智能对抗推理基准,ViANLI展现出显著的领域多样性特征。其数据实例采用标准化JSON行格式存储,每个样本均配备全局唯一标识符,并严格遵循自然语言推理的三元分类框架。该数据集特别注重语言现象的复杂性设计,通过精心构造的对抗样本有效揭示模型在跨域推理中的脆弱性,为越南语及多语言自然语言处理研究提供重要实验基础。
使用方法
针对自然语言推理模型的鲁棒性评估,研究者可依据标准数据划分方案加载ViANLI的预分割子集。训练集包含八千余个样本,验证集与测试集各千条数据,均以结构化JSON格式呈现。使用时应通过解析uid字段实现样本追踪,将premise-hypothesis对输入目标模型进行推理任务训练或测试,最终根据label字段的黄金标准评估模型在对抗环境下的语义理解能力。
背景与挑战
背景概述
自然语言推理作为自然语言处理领域的核心任务之一,旨在探究前提与假设之间的逻辑关系。2025年,由Tin Van Huynh等学者构建的ViANLI数据集应运而生,成为越南语领域首个对抗性自然语言推理基准。该数据集基于人机协同的构建范式,通过多轮对抗生成与双重验证机制,从越南新闻中提炼出涵盖13个领域的万余条高质量语料,为越南语及多语言推理研究提供了重要支撑。
当前挑战
在自然语言推理任务中,模型常因词汇重叠、句法歧义等表面线索产生误判,而ViANLI通过对抗性构造有效揭示了此类脆弱性。其构建过程面临双重挑战:一方面需设计涵盖反讽、多义等复杂语言现象的假设句,另一方面需协调人工标注与模型验证的迭代流程,确保标注一致性与语言地道性。这些挑战共同推动了鲁棒性推理模型的发展。
常用场景
经典使用场景
在自然语言推理研究领域,ViANLI数据集作为越南语首个对抗性基准,常被用于评估模型对复杂语言现象的鲁棒性。其通过人机协同构建的万余条高质量前提-假设对,覆盖新闻、法律等13个领域,为测试模型在语义蕴含、中立和矛盾关系上的推理能力提供了标准化平台。
衍生相关工作
基于ViANLI的基准特性,学界衍生出多项经典研究,如混合专家语言模型的架构优化研究,以及跨语言对抗训练方法的创新。这些工作不仅深化了对越南语语义表征的理解,更为东南亚语言处理提供了可迁移的技术框架。
数据集最近研究
最新研究方向
在自然语言处理领域,越南语自然语言推理(NLI)正面临对抗性挑战的考验。ViANLI作为首个越南语对抗性基准数据集,通过人机协同构建和多轮对抗生成机制,推动了模型鲁棒性评估的前沿探索。当前研究聚焦于利用该数据集测试多语言模型在复杂语言现象下的泛化能力,尤其在新闻领域中的语义推理偏差和逻辑矛盾检测方面。随着跨语言迁移学习的热度攀升,ViANLI为低资源语言的可信人工智能发展提供了关键支撑,促进了语言模型在真实场景中的抗干扰性能优化。
以上内容由遇见数据集搜集并总结生成


