OpenSeeSimE-Fluid-Mini
收藏Hugging Face2026-04-24 更新2026-04-25 收录
下载链接:
https://huggingface.co/datasets/JessicaE/OpenSeeSimE-Fluid-Mini
下载链接
链接失效反馈官方服务:
资源简介:
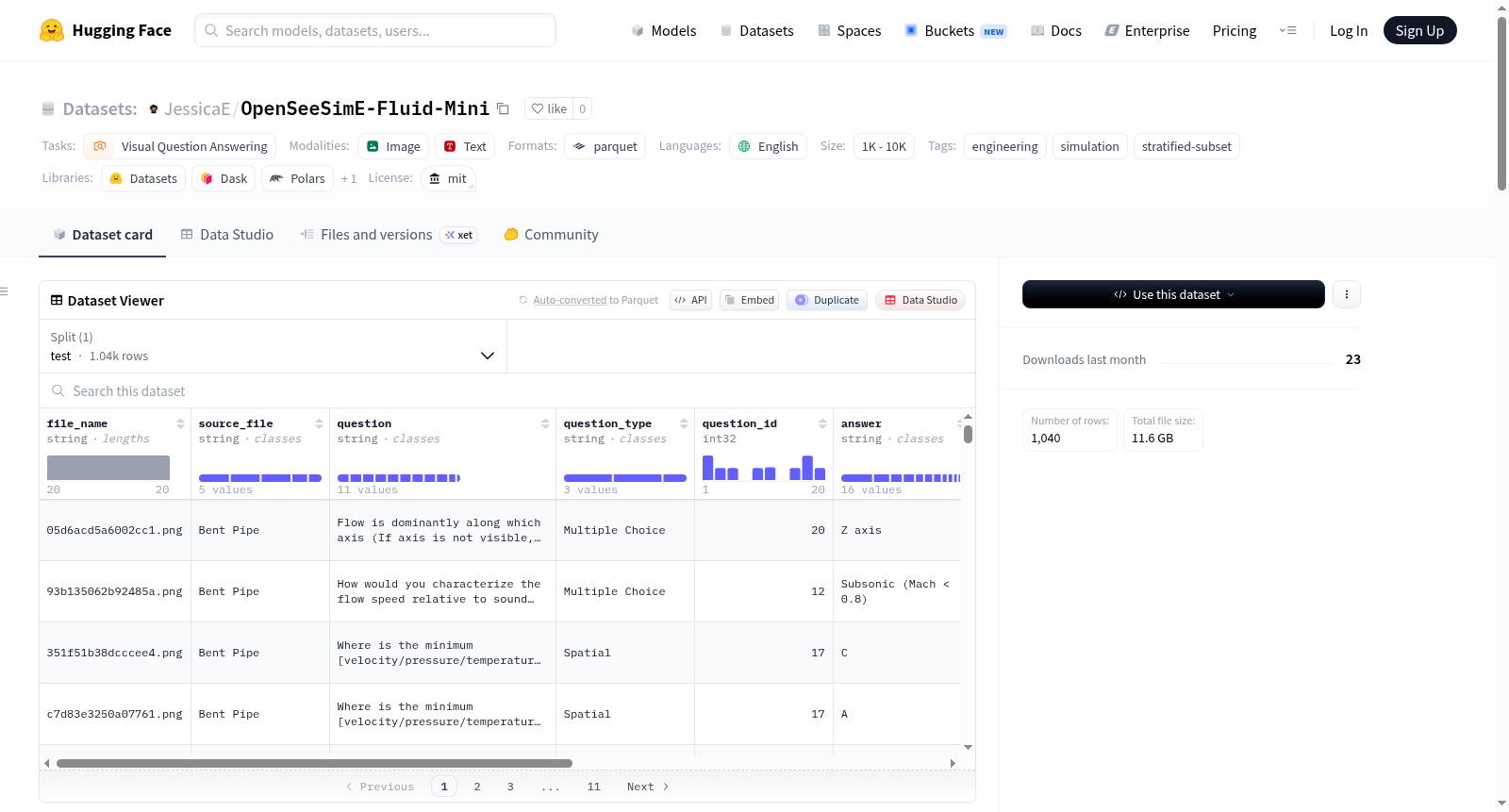
OpenSeeSimE-Fluid-Mini是OpenSeeSimE-Fluid数据集的1%分层子集,旨在以较低的计算成本评估视觉语言模型,同时保持模拟类型、问题类型、媒体类型和问题ID的联合分布。数据集包含1,040个样本,分为图像和视频两种媒体类型,各占50%。数据来源包括Bent Pipe、Converging Nozzle、Heat Exchanger、Heat Sink和Mixing Pipe五种模拟模型。问题类型包括Binary、Multiple Choice和Spatial。数据集的特征包括文件名称、来源文件、问题文本、问题类型、问题ID、答案、答案选项、正确答案索引、图像、视频和媒体类型。该数据集适用于工程模拟问答的基准评估、评估管道的冒烟测试以及存储或带宽受限的比较研究。数据集采用MIT许可证,允许学术和商业使用,需注明出处。
创建时间:
2026-04-23
原始信息汇总
OpenSeeSimE-Fluid-Mini 数据集概述
基本信息
- 数据集地址:https://huggingface.co/datasets/JessicaE/OpenSeeSimE-Fluid-Mini
- 许可证:MIT(可自由用于学术和商业用途,需注明来源)
- 语言:英语
- 任务类别:视觉问答(Visual Question Answering)
- 数据规模:1K < n < 10K
- 标签:engineering, simulation, stratified-subset
数据来源与采样
- 父数据集:
cmudrc/OpenSeeSimE-Fluid(共98,326行) - 子集规模:1,040行(占父数据集的1.06%)
- 来源类别:Bent Pipe、Converging Nozzle、Heat Exchanger、Heat Sink、Mixing Pipe
- 存储格式:3个Parquet分片,约11.61 GB
- 采样方法:按层(strata)进行随机洗牌(种子为42),每层取
ceil(n * fraction)行,非空层至少保留1行 - 分层依据:
(source_file, question_type, media_type, question_id)四维联合分层 - 嵌套关系:该1%子集是10%子集的字面子集(所有分片使用相同的洗牌前缀)
数据组成
按 source_file 分布
| source_file | 行数 | 占比 (%) |
|---|---|---|
| Heat Exchanger | 220 | 21.15 |
| Mixing Pipe | 220 | 21.15 |
| Bent Pipe | 204 | 19.62 |
| Converging Nozzle | 204 | 19.62 |
| Heat Sink | 192 | 18.46 |
按 media_type 分布
| media_type | 行数 |
|---|---|
| image | 520 |
| video | 520 |
按 (source_file, question_type) 分布
| source_file | Binary | Multiple Choice | Spatial | 总计 |
|---|---|---|---|---|
| Bent Pipe | 82 | 82 | 40 | 204 |
| Converging Nozzle | 82 | 82 | 40 | 204 |
| Heat Exchanger | 88 | 88 | 44 | 220 |
| Heat Sink | 76 | 72 | 44 | 192 |
| Mixing Pipe | 88 | 88 | 44 | 220 |
特征模式
所有特征与父数据集一致,具体如下:
| 特征名 | 类型 | 说明 |
|---|---|---|
| file_name | 字符串 | 唯一标识符 |
| source_file | 字符串 | 基础仿真模型名称 |
| question | 字符串 | 问题文本 |
| question_type | 字符串 | 问题类型(Binary/Multiple Choice/Spatial) |
| question_id | 整数 | 问题标识符(1-20) |
| answer | 字符串 | 标准答案 |
| answer_choices | 字符串列表 | 选项列表 |
| correct_choice_idx | 整数 | 正确答案索引 |
| image | 图像 | PIL图像(1920×1440),视频行为空 |
| video | 视频 | 视频数据,图像行为空 |
| media_type | 字符串 | 媒体类型(image或video) |
预期用途
- 在降低计算开销的前提下,评估视觉语言模型在工程仿真问答任务上的表现
- 在运行完整基准测试前,对评估流程进行烟雾测试
- 适用于存储或带宽受限场景下的对比研究
引用
bibtex @article{ezemba2024opensesime, title={OpenSeeSimE: A Large-Scale Benchmark to Assess Vision-Language Model Question Answering Capabilities in Engineering Simulations}, author={Ezemba, Jessica and Pohl, Jason and Tucker, Conrad and McComb, Christopher}, year={2025} }
联系方式
Jessica Ezemba — jezemba@andrew.cmu.edu
卡内基梅隆大学机械工程系
搜集汇总
数据集介绍
构建方式
OpenSeeSimE-Fluid-Mini是基于大规模工程仿真数据集OpenSeeSimE-Fluid精心构建的层化子集,旨在以更低的计算开销保留原始数据分布的关键特性。该子集通过联合层化采样策略,依据(source_file, question_type, media_type, question_id)四维组合将数据划分为多个层级,并在每一层内使用numpy.random.default_rng(42)进行独立随机洗牌,随后取每层ceil(n * fraction)个样本,确保每一非空层至少贡献一条数据。最终从原始98,326条记录中抽取了1,040条,占比约1.06%,涵盖了弯管、收敛喷嘴、换热器、散热器和混合管五种典型仿真类型,并均衡地包含图像与视频两种媒体形式。
使用方法
该数据集专为视觉语言模型在工程仿真问答任务上的轻量级评估而设计,可直接加载至评测管道中,以极低的存储与计算开销完成模型表现的快速验证或流水线调试。使用者可通过HuggingFace Datasets库加载默认配置,获取包含文件标识、问题文本、答案选项、正确索引以及图像或视频媒体的结构化样本。研究者在进行全量基准测试前,可先在此子集上进行预测试,也可在存储或带宽受限的场景下将其用作替代性评估集合,同时需引用原始论文以标注数据来源。
背景与挑战
背景概述
在工程仿真领域,视觉-语言模型(VLM)的评估亟需高质量、多模态的基准数据集。OpenSeeSimE-Fluid-Mini由卡内基梅隆大学机械工程系的Jessica Ezemba、Jason Pohl、Conrad Tucker和Christopher McComb于2025年创建,作为OpenSeeSimE-Fluid数据集的1%分层子集,旨在以降低的计算成本评估VLM在工程流体仿真问答任务中的表现。该数据集涵盖弯曲管道、收敛喷嘴、换热器、散热器和混合管道五类工程仿真场景,包含1040个图像与视频样本,支持二元、多项选择和空间三类问题,为检验模型对工程域知识的理解与推理能力提供了标准化测试平台。其科学抽样策略确保了仿真类型、问题类型和媒体类型的联合分布得到保留,在推动VLM在工程领域的应用方面具有重要影响力。
当前挑战
OpenSeeSimE-Fluid-Mini所解决的领域挑战在于,工程仿真问答不同于自然图像问答,需要模型同时理解流体动力学原理、几何结构的三维空间关系以及动态过程,这对VLM的视觉感知与物理推理能力提出了严峻考验。在构建过程中,挑战主要体现为:1)数据生成需从复杂仿真模型中精准提取地面真值,确保答案的物理正确性;2)大规模数据(原数据集98326行)的存储与处理效率低下,子集的抽样必须在不破坏关键分布特征的前提下实现显著规模缩减;3)多模态数据(图像与视频)的格式统一与标注一致性维护要求严密。该数据集的策略性分层抽样方案,为缓解这些挑战提供了可行路径。
常用场景
经典使用场景
在工程仿真与计算机视觉交叉领域,OpenSeeSimE-Fluid-Mini数据集被广泛用于评估视觉-语言模型在工程模拟问答任务上的表现。该数据集通过分层抽样策略,从完整数据集中保留了仿真类型、问题类型、媒体类型和问题标识的联合分布,使得研究者在降低计算开销的同时,仍能获得具有代表性的评估结果。其经典使用场景包括对模型在管道弯曲、收敛喷嘴、换热器、散热器和混合管道等五种工程构型下的视觉理解与推理能力进行基准测试,涵盖二元分类、多项选择和空间定位三类问题,并以图像和视频两种媒体形式呈现,全面考察模型对流体动力学仿真视觉信息的处理能力。
解决学术问题
该数据集有效解决了工程领域视觉-语言模型评估中缺乏标准化、可复现基准的关键学术难题。在OpenSeeSimE-Fluid-Mini出现之前,研究者难以系统衡量模型对工程仿真图像和视频的理解深度,尤其是在涉及空间关系与物理规律的问答任务中。该数据集通过精心设计的问题类型和结构化标注,为模型在工程模拟领域的视觉推理能力提供了量化评价框架,推动了多模态学习在工程应用中的方法论创新。其意义在于降低了大规模基准测试的计算资源门槛,使得更多研究团队能够开展有意义的对比实验,从而加速了面向工程领域的专用视觉-语言模型的发展。
实际应用
在实际工程应用中,OpenSeeSimE-Fluid-Mini数据集为自动化工程仿真分析与智能辅助设计工具的开发提供了关键支撑。基于该数据集训练的视觉-语言模型能够自动识别仿真结果中的物理流动特征,例如判别管道内流体是否发生分离、判断喷嘴出口速度分布是否均匀,或定位换热器中的高温区域。这些能力可被集成到计算机辅助工程软件中,帮助工程师快速解读仿真结果、生成分析报告,或为设计优化提供智能建议。此外,该数据集支持图像与视频两种媒体形式,使其适用于连续动态过程的实时监测场景,例如在工业生产线中通过视频流检测流体异常行为。
数据集最近研究
最新研究方向
OpenSeeSimE-Fluid-Mini作为工程仿真领域视觉-语言模型评估的轻量级基准,正引领着多模态理解研究向工业级流体力学场景深入。该数据集通过分层采样策略,在保持原始数据集仿真类型、问题类型、媒体类型及问题标识联合分布完整性的前提下,将计算开销压缩至1%,为资源受限场景下的模型验证提供了高效方案。当前前沿方向聚焦于利用该子集评估大规模视觉语言模型在弯管、换热器等复杂流体部件上的物理理解能力,尤其是对二值选择、多元选择与空间定位三类问题的推理水平。其分层子集设计不仅支持了仿真问答评估流水线的快速迭代,还为跨模态知识迁移与因果推理研究提供了可控的工程领域试验田,对于推进AI在数字孪生与计算机辅助工程中的可信应用具有关键意义。
以上内容由遇见数据集搜集并总结生成


