Persona Hub 网络数据中自动整理的 10 亿个不同角色数据集
收藏超神经2024-07-07 更新2024-07-06 收录
下载链接:
https://hyper.ai/cn/datasets/32732
下载链接
链接失效反馈官方服务:
资源简介:
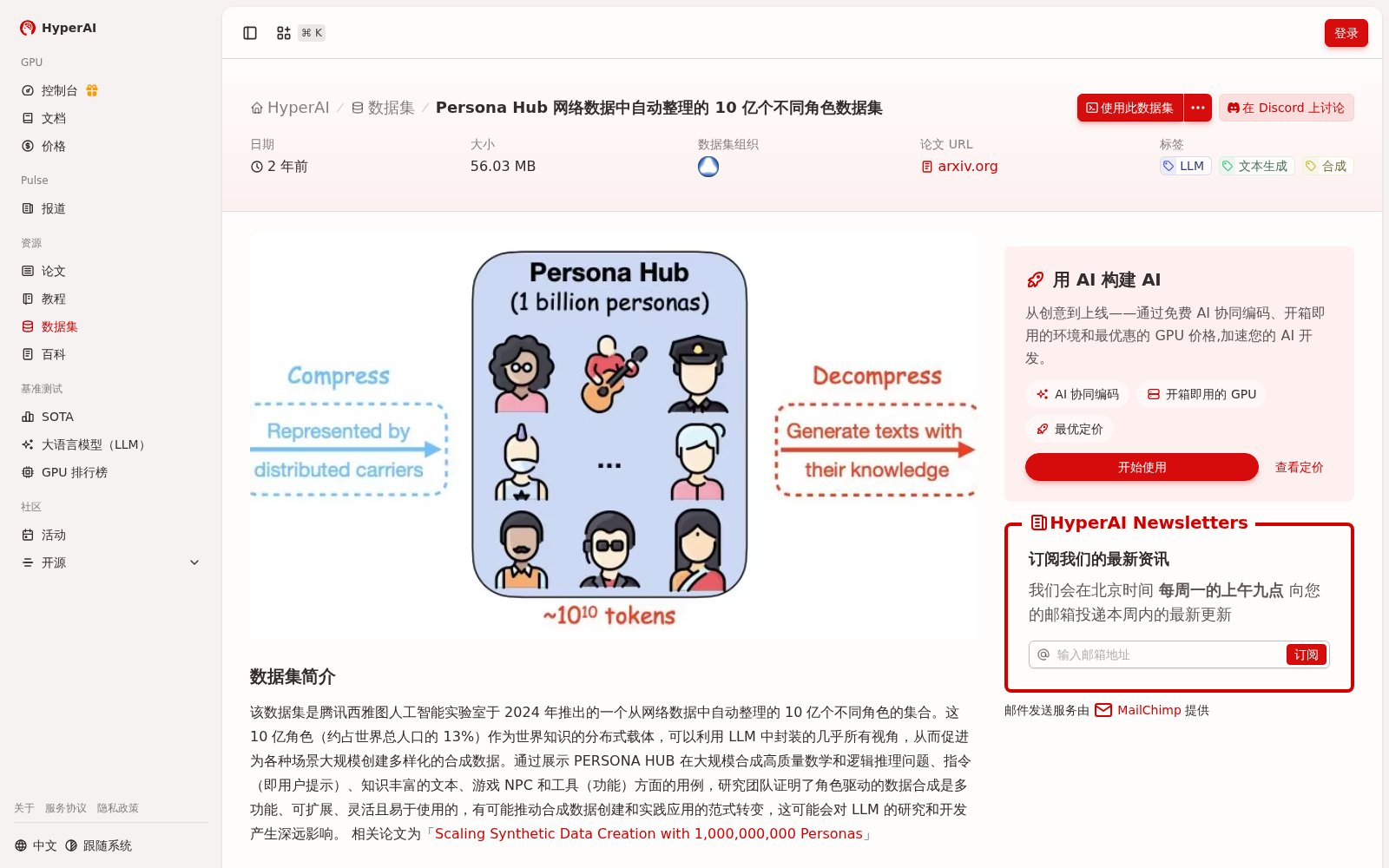
该数据集是腾讯西雅图人工智能实验室于 2024 年推出的一个从网络数据中自动整理的 10 亿个不同角色的集合。这 10 亿角色(约占世界总人口的 13%)作为世界知识的分布式载体,可以利用 LLM 中封装的几乎所有视角,从而促进为各种场景大规模创建多样化的合成数据。通过展示 PERSONA HUB 在大规模合成高质量数学和逻辑推理问题、指令(即用户提示)、知识丰富的文本、游戏 NPC 和工具(功能)方面的用例,研究团队证明了角色驱动的数据合成是多功能、可扩展、灵活且易于使用的,有可能推动合成数据创建和实践应用的范式转变,这可能会对 LLM 的研究和开发产生深远影响。
This dataset is a collection of 1 billion distinct personas automatically curated from web data, launched by Tencent Seattle AI Lab in 2024. Accounting for approximately 13% of the world's total population, these 1 billion personas serve as distributed carriers of global knowledge, and can leverage nearly all perspectives encapsulated in large language models (LLMs), thereby facilitating the large-scale generation of diverse synthetic data across various scenarios. By showcasing the use cases of PERSONA HUB in large-scale synthesis of high-quality mathematical and logical reasoning problems, instructions (i.e., user prompts), knowledge-rich texts, game NPCs, and tools (functions), the research team verified that persona-driven data synthesis is versatile, scalable, flexible and user-friendly, with the potential to trigger a paradigm shift in synthetic data creation and practical applications, which may exert far-reaching impacts on the research and development of LLMs.
创建时间:
2024-07-03
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集由腾讯西雅图人工智能实验室于2024年推出,包含从网络数据自动整理的10亿个不同角色,约占世界总人口的13%。这些角色作为世界知识的分布式载体,利用大语言模型中的多种视角,可大规模生成多样化的合成数据,如数学推理问题和指令,有望推动合成数据创建和应用范式的转变。
以上内容由遇见数据集搜集并总结生成


