nb-asr-mt-gold
收藏Hugging Face2026-05-25 更新2026-05-26 收录
下载链接:
https://huggingface.co/datasets/NbAiLab/nb-asr-mt-gold
下载链接
链接失效反馈官方服务:
资源简介:
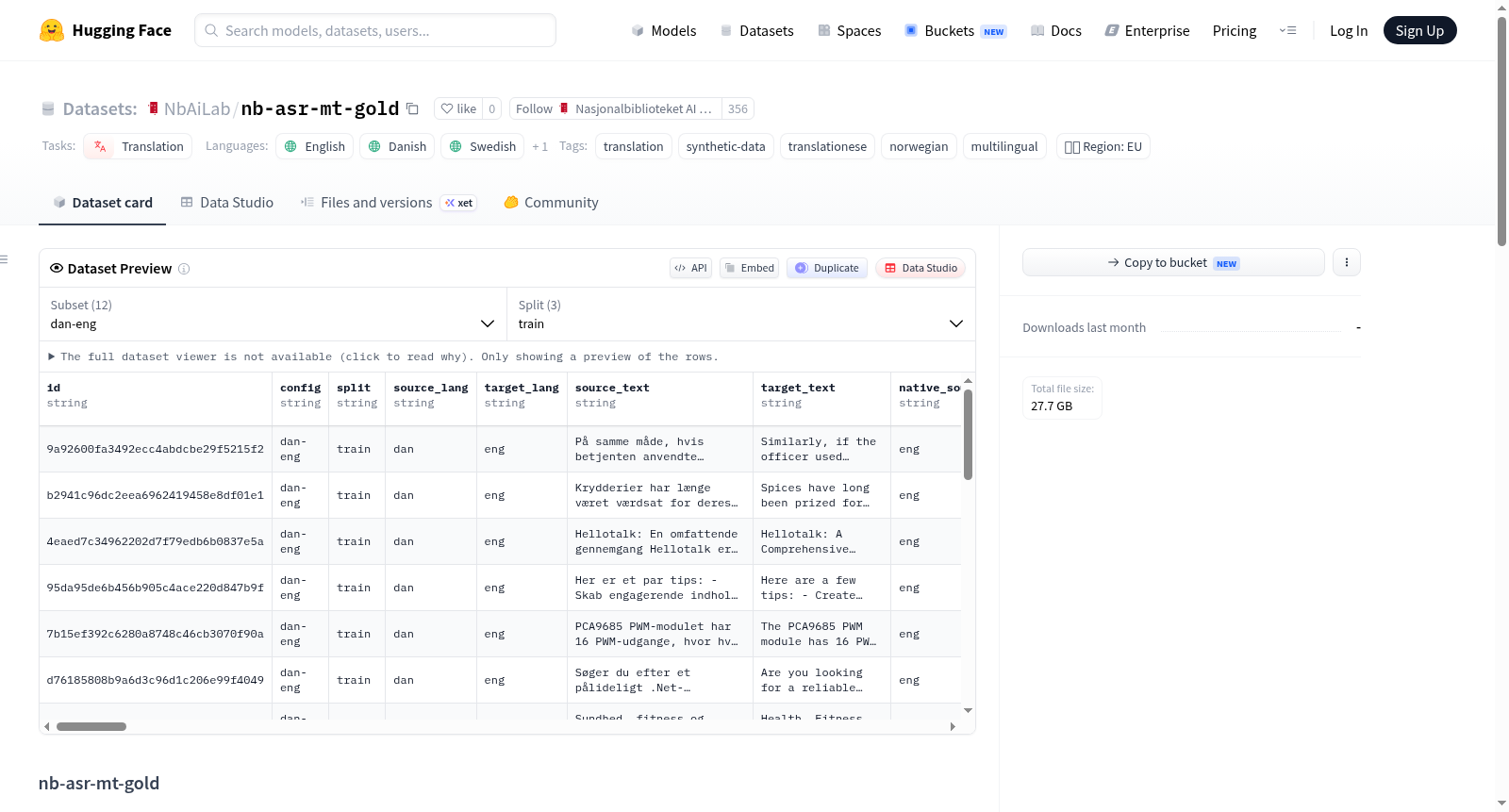
nb-asr-mt-gold是一个基于NB-ASR翻译语料库管道生成的机器翻译清单数据集,专门用于机器翻译训练和翻译语料库感知数据构建研究。该数据集包含12个语言对配置,涵盖英语(eng)、丹麦语(dan)、瑞典语(swe)和挪威语(nob)之间的双向翻译。其核心构建理念采用反向合成数据使用策略:当一种语言(X)的母语文本被翻译成合成语言(Y)时,生成的数据行被用作从语言Y到语言X的训练样本,因此监督目标始终是地道的母语文本,而源端文本可能保留翻译过程中产生的翻译语料库特征。该数据集是经过严格过滤的“黄金”变体,通过多语言嵌入模型对母语原始文本和同语言回译文本进行相似度评估,仅保留高度相似的样本,旨在提供高置信度的训练数据,注重有用的覆盖范围而非严格的字符串一致性。数据总规模为3,397,227行,按照95%训练集、2.5%验证集和2.5%测试集的比例进行确定性分割,其中规模较大的配置包括eng-nob(568,812行)、dan-nob(569,273行)和swe-nob(574,352行)。数据生成过程使用了四种模型家族进行翻译路径生成,并采用不同模型进行回译,数据集保留了模型ID、版本信息、验证元数据、使用元数据、时间元数据、母语原始文本、枢轴翻译文本和回译文本等丰富字段。该数据集主要适用于机器翻译模型训练,使用时以source_text作为模型输入,target_text作为监督学习的母语目标输出。
nb-asr-mt-gold is a machine translation list dataset generated based on the NB-ASR translation corpus pipeline, specifically designed for machine translation training and translation corpus-aware data construction research. The dataset includes 12 language pair configurations, covering bidirectional translations among English (eng), Danish (dan), Swedish (swe), and Norwegian (nob). Its core construction concept employs a reverse synthetic data usage strategy: when native text in one language (X) is translated into a synthetic language (Y), the generated data row is used as a training sample from language Y to language X. Thus, the supervised target is always authentic native text, while the source text may retain translation corpus characteristics generated during the translation process. This dataset is a strictly filtered gold variant that uses a multilingual embedding model to evaluate the similarity between native original text and back-translated text in the same language, retaining only highly similar samples to provide high-confidence training data, focusing on useful coverage rather than strict string consistency. The total data size is 3,397,227 rows, deterministically split into 95% training set, 2.5% validation set, and 2.5% test set, with larger configurations including eng-nob (568,812 rows), dan-nob (569,273 rows), and swe-nob (574,352 rows). The data generation process utilizes four model families for translation path generation and employs different models for back-translation. The dataset retains rich fields such as model ID, version information, validation metadata, usage metadata, temporal metadata, native original text, pivot translation text, and back-translated text. This dataset is primarily suitable for machine translation model training, where source_text is used as model input and target_text as the supervised native target output.
提供机构:
Nasjonalbiblioteket AI Lab
创建时间:
2026-05-25
搜集汇总
数据集介绍
构建方式
该数据集基于NB-ASR翻译腔流水线构建,核心策略在于反向运用合成数据:当语种X的母语文本被翻译为合成语种Y后,所得结果被用作Y到X方向的训练数据,确保监督目标始终为自然母语文本,而源端可能残留翻译腔痕迹。具体流程借助Olivia平台上的四种翻译模型族(如Google TranslateGemma系列与Qwen系列)生成翻译路径,并使用与正向模型不同的模型进行回译。最终的金标准版本进一步引入多语言嵌入模型,对母语原文与同语种回译结果进行相似性评估,仅保留高置信度的样本。
特点
数据集共含约340万条样本,涵盖英语、挪威语、瑞典语、丹麦语间的12个语言对方向。其独特之处在于通过严格的嵌入相似性筛选机制,在避免完全字符串匹配的前提下,保留具有实用覆盖度的高置信度训练数据。每条记录均保留模型标识、版本、验证元数据及原文、枢轴翻译、回译文本等多层信息,支持翻译腔感知的数据构建研究。数据划分按配置和源块ID确定性分配为95%训练集、2.5%验证集与2.5%测试集。
使用方法
该数据集专为机器翻译训练及翻译腔感知的数据构建研究而设计。使用时,将`source_text`字段作为模型输入,`target_text`字段作为监督目标(即自然母语文本)。用户可根据研究需要选择特定语言对配置(如`eng-nob`、`swe-dan`等),并加载对应的训练、验证或测试分片。由于数据集处于积极开发阶段,外部使用需获得原始项目团队的明确许可。
背景与挑战
背景概述
在机器翻译(MT)与语音识别(ASR)交叉领域,高质量平行语料的匮乏长期制约着北欧小语种(如挪威语、瑞典语、丹麦语)的技术突破。由挪威国家图书馆(NB)的Per Egil Kummervold与Thea Tollersrud主导的nb-asr-mt-gold数据集应运而生,旨在通过创新的翻译腔(translationese)逆向使用策略,构建高置信度的机器翻译训练语料。该数据集创建于当前阶段,依托四种大模型家族(如Google TranslateGemma、SalamandraTA等)生成合成数据,并经过多轮严格过滤,最终包含约340万条记录,覆盖英-挪、挪-英、瑞-英等12个语言对。其核心研究问题聚焦于如何利用逆向合成数据(即源语言为翻译腔、目标语言为原生文本)提升翻译模型的鲁棒性与低资源语言翻译质量,对斯堪的纳维亚语系的NLP生态具有里程碑意义。
当前挑战
该数据集所解决的领域核心挑战在于:低资源北欧语言(如书面挪威语、瑞典语、丹麦语)在传统机器翻译中因平行语料稀缺而表现欠佳,且现有数据常混杂翻译腔(translationese)噪声,导致模型难以学习自然语言表达。在构建过程中,团队面临多重技术挑战:首先,需设计可靠的合成数据流水线,避免前向翻译中的幻觉(hallucination)、截断(truncation)及语言识别错误;其次,为确保数据质量,开发了分层过滤机制——基础版(nb-asr-mt)仅做语言ID验证,过滤版(nb-asr-mt-filtered)利用多语言嵌入模型消除严重误差,而黄金版(nb-asr-mt-gold)则通过同语言回译与原文本的嵌入相似度对比,在容忍非完全字符串匹配的前提下保留高置信度样本,这对相似度阈值的设置和计算效率提出了极高要求。
常用场景
经典使用场景
在机器翻译领域,高置信度平行语料的获取始终是制约模型性能提升的关键瓶颈。nb-asr-mt-gold数据集通过巧妙的逆向合成数据构建策略,为斯堪的纳维亚语系(挪威语、瑞典语、丹麦语)与英语之间的翻译任务提供了纯正且可靠的训练资源。每个样本的监督目标均为母语文本,源端虽有翻译腔痕迹,但经同语言回译嵌入相似性筛选后,确保了翻译对的高质量对齐。该数据集特别适用于双语翻译模型的微调与鲁棒性评估,尤擅长解决翻译腔对模型泛化能力的侵蚀问题,成为北欧语言神经机器翻译研究中的基准测评平台。
衍生相关工作
nb-asr-mt-gold数据集的诞生催生了系列关联性学术工作。基于其翻译腔筛选范式,研究者进一步提出了“多教师评分融合”策略,通过集成多个翻译模型的后验概率来提升回译质量判别精度。同时,该数据集的构建流程已衍生出面向冰岛语、芬兰语等非印欧语系的高质量平行语料生产管线,将逆向合成数据方法论拓展至更广泛的低资源语言场景。此外,部分工作探索了以其gold筛选结果为监督信号,训练轻量级质量评估模型,实现了动态过滤网络翻译流中的噪声文本的能力,推动机器翻译从“数据驱动”迈向“质量感知”的新阶段。
数据集最近研究
最新研究方向
当前,北欧小语种神经机器翻译研究正面临高质量平行语料匮乏的严峻挑战,而翻译腔伪影对模型泛化能力的侵蚀更是亟待突破的瓶颈。nb-asr-mt-gold数据集凭借其独创性的逆向合成数据构建范式,开创性地将多语言嵌入模型的高置信度筛选机制融入语料精炼流程,通过对原生文本与回译结果的语义相似性进行严格度量,有效剔除了伪翻译与噪声数据,从而锻造出兼具高纯净度与实用覆盖范围的多语对黄金标准语料库。这一前沿研究路径不仅为英语-挪威语、瑞典语-丹麦语等十二组斯堪的纳维亚语言对提供了高质量训练基准,更通过引入翻译腔感知数据构造理念,揭示了在资源受限场景下通过代理任务反向利用合成数据以提升低资源语言机器翻译鲁棒性的新范式,其方法论有望辐射至全球小语种翻译系统的构建与评估体系。
以上内容由遇见数据集搜集并总结生成


