TAIX-Ray
收藏Hugging Face2026-02-08 更新2026-02-09 收录
下载链接:
https://huggingface.co/datasets/TLAIM/TAIX-Ray
下载链接
链接失效反馈官方服务:
资源简介:
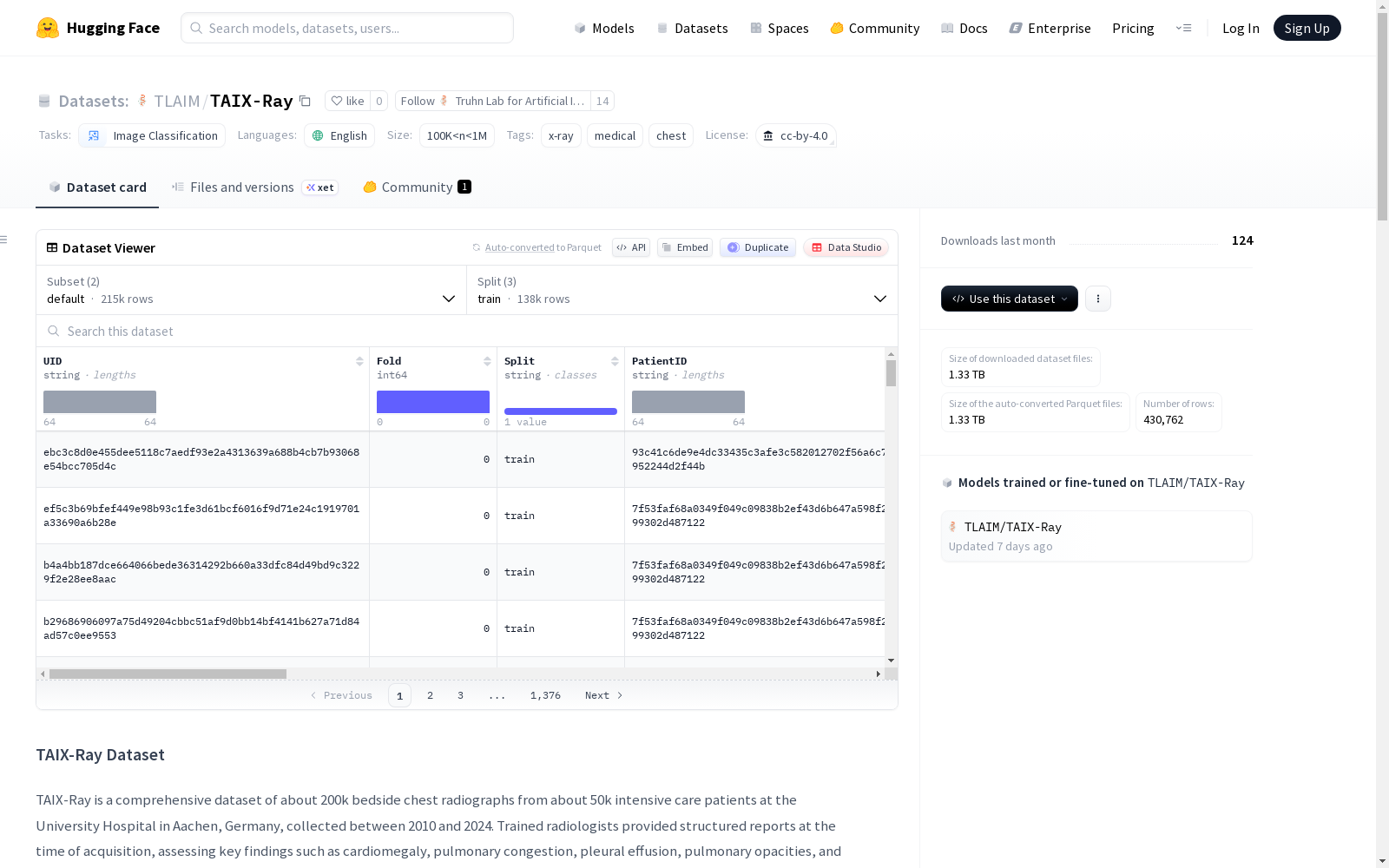
TAIX-Ray 是一个包含约20万张床边胸部X光片的综合数据集,这些数据来自德国亚琛大学医院约5万名重症监护患者,采集时间跨度为2010年至2024年。训练有素的放射科医生在采集时提供了结构化报告,评估了关键发现,如心脏扩大、肺充血、胸腔积液、肺混浊和肺不张,并按序数尺度进行评分。数据集包含两个配置:默认配置(62GB,图像大小为512px)和原始配置(1.2TB,图像大小可变)。每个样本包含唯一标识符(UID)、患者ID、医生ID、研究日期、年龄、性别等元数据,以及多个临床指标的评分和图像数据。数据集适用于医学图像分类任务,特别是胸部X光片的自动分析。
创建时间:
2026-02-05
原始信息汇总
TAIX-Ray 数据集概述
数据集基本信息
- 数据集名称: TAIX-Ray
- 托管地址: https://huggingface.co/datasets/TLAIM/TAIX-Ray
- 许可协议: CC BY 4.0
- 主要任务类别: 图像分类
- 语言: 英语
- 标签: X射线、医学、胸部
- 数据规模: 10万到100万之间
数据来源与描述
TAIX-Ray 是一个包含约20万张床边胸部X光片的综合数据集,这些X光片来自德国亚琛大学医院约5万名重症监护患者,采集时间跨度为2010年至2024年。训练有素的放射科医生在采集时提供了结构化报告,评估了关键发现,如心脏扩大、肺充血、胸腔积液、肺混浊和肺不张,并采用序数尺度进行评分。
数据集配置
该数据集提供两种配置。
| 配置名称 | 下载大小 | 数据集大小 | 图像尺寸 |
|---|---|---|---|
| default | 58.34 GB | 57.02 GB | 512px |
| original | 1.27 TB | 1.23 TB | 可变 |
配置详情
配置:default
- 数据文件路径:
- 训练集:
data/train-* - 测试集:
data/test-* - 验证集:
data/val-*
- 训练集:
- 数据量:
- 训练集: 137,593 个样本,约 36.72 GB
- 测试集: 42,928 个样本,约 11.09 GB
- 验证集: 34,860 个样本,约 9.21 GB
配置:original
- 数据文件路径:
- 训练集:
original/train-* - 测试集:
original/test-* - 验证集:
original/val-*
- 训练集:
- 数据量:
- 训练集: 137,593 个样本,约 793.58 GB
- 测试集: 42,928 个样本,约 235.10 GB
- 验证集: 34,860 个样本,约 197.76 GB
数据特征
两种配置均包含以下特征字段:
- UID: 字符串,唯一标识符。
- Fold: 整型,折叠编号。
- Split: 字符串,数据划分(train/test/val)。
- PatientID: 字符串,患者标识符。
- PhysicianID: 字符串,医师标识符。
- StudyDate: 字符串,研究日期。
- Age: 整型,年龄。
- Sex: 字符串,性别。
- HeartSize: 整型,心脏大小评分。
- PulmonaryCongestion: 整型,肺充血评分。
- PleuralEffusion_Right: 整型,右侧胸腔积液评分。
- PleuralEffusion_Left: 整型,左侧胸腔积液评分。
- PulmonaryOpacities_Right: 整型,右侧肺混浊评分。
- PulmonaryOpacities_Left: 整型,左侧肺混浊评分。
- Atelectasis_Right: 整型,右侧肺不张评分。
- Atelectasis_Left: 整型,左侧肺不张评分。
- Image: 图像,X光片。
使用方式
前置依赖
需安装以下Python库:datasets, matplotlib, huggingface_hub, pandas, tqdm。
选项A:在Hugging Face框架内使用
使用 datasets 库直接加载数据集,并可进行可视化。
选项B:下载数据集到本地
通过流式加载将数据集下载到指定文件夹,生成包含图像文件(data/目录)和元数据CSV文件(metadata/目录)的本地结构。
相关资源
- 代码与详细信息: 数据加载、预处理和基线实验的代码位于:https://github.com/mueller-franzes/TAIX-Ray
搜集汇总
数据集介绍
构建方式
在医学影像分析领域,构建高质量数据集是推动人工智能辅助诊断技术发展的基石。TAIX-Ray数据集源自德国亚琛大学医院重症监护病房,涵盖了2010年至2024年间约5万名患者的近20万张床旁胸部X光影像。该数据集的构建过程严格遵循临床实践规范,由经验丰富的放射科医师在影像采集时提供结构化报告,对心脏增大、肺淤血、胸腔积液、肺部阴影和肺不张等关键病理特征进行有序尺度评估,确保了标注的准确性和临床相关性。
使用方法
利用TAIX-Ray数据集开展研究,研究者可通过Hugging Face的datasets库直接加载数据,支持流式读取以适配不同存储环境。数据加载后,可便捷访问训练集、验证集和测试集,每个样本均包含影像及其对应结构化标注。用户能够灵活提取图像进行可视化分析,同时获取相关临床元数据。数据集亦支持完整下载至本地,自动构建包含影像文件和标注CSV的目录结构,便于离线处理与集成。这种设计兼顾了云端实验的便利性与本地部署的灵活性,为医学影像算法的开发与验证提供了高效平台。
背景与挑战
背景概述
TAIX-Ray数据集由德国亚琛大学医院的研究团队于2024年构建,收录了2010年至2024年间约5万名重症监护患者的近20万张床旁胸部X光影像。该数据集旨在应对医学影像分析领域中对大规模、高质量标注数据的需求,核心研究问题聚焦于利用深度学习技术自动识别胸部X光中的关键病理特征,如心脏扩大、肺淤血、胸腔积液、肺实变和肺不张等。通过提供放射科医师在采集时完成的结构化报告,该数据集为开发鲁棒的计算机辅助诊断模型奠定了坚实基础,显著推动了重症监护环境下胸部影像的智能化分析研究。
当前挑战
在医学影像分析领域,胸部X光自动诊断面临诸多挑战,包括病理特征在影像中表现细微、类间相似度高,以及重症患者影像常伴有设备伪影或体位变异,导致模型泛化能力受限。数据构建过程中,挑战主要体现在确保标注的一致性与专业性,需要多位放射科医师遵循严格标准进行独立评估以消除主观偏差;同时,处理大规模影像数据涉及患者隐私保护、数据脱敏与存储管理,原始影像尺寸不一也增加了预处理与标准化的复杂度。
常用场景
经典使用场景
在医学影像分析领域,TAIX-Ray数据集作为一项大规模胸部X光影像资源,其经典使用场景聚焦于深度学习模型的训练与评估。该数据集通过提供约20万张床边胸片,并附有放射科医师标注的结构化报告,为研究者构建多标签分类模型奠定了坚实基础。这些模型能够自动识别心脏扩大、肺淤血、胸腔积液、肺部混浊和肺不张等关键病理特征,从而辅助临床诊断决策。
解决学术问题
TAIX-Ray数据集有效解决了医学人工智能研究中数据稀缺与标注质量不均的普遍难题。其大规模、高质量且具有时序性的标注信息,为探索模型可解释性、领域适应以及少样本学习等前沿课题提供了宝贵实验平台。该数据集促进了放射学报告自动化生成技术的进步,并推动了跨机构数据协作的标准化进程,对提升医疗AI模型的泛化能力与临床可信度具有深远影响。
实际应用
该数据集的实际应用场景紧密围绕重症监护病房的临床工作流展开。基于TAIX-Ray训练的模型可集成至医院信息系统,实现对危重患者胸部X光片的实时初步筛查与优先级排序。这不仅能减轻放射科医师的高负荷工作压力,还能为早期发现急性心肺并发症提供辅助支持,优化重症患者的诊疗路径与资源分配效率。
数据集最近研究
最新研究方向
在医学影像分析领域,TAIX-Ray数据集凭借其大规模重症监护胸片数据与结构化放射科医师标注,正推动多标签分类与预后预测模型的深度探索。前沿研究聚焦于开发可解释的深度学习架构,以精准量化心脏扩大、肺淤血等关键征象的严重程度,辅助临床决策。该数据集与全球公共卫生事件中肺部病变监测需求相呼应,促进了跨机构数据协作与标准化评估框架的建立,为重症医学的智能化转型提供了关键数据基石。
以上内容由遇见数据集搜集并总结生成


