music-ocr-vectors
收藏Hugging Face2026-05-18 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/Dddixyy/music-ocr-vectors
下载链接
链接失效反馈官方服务:
资源简介:
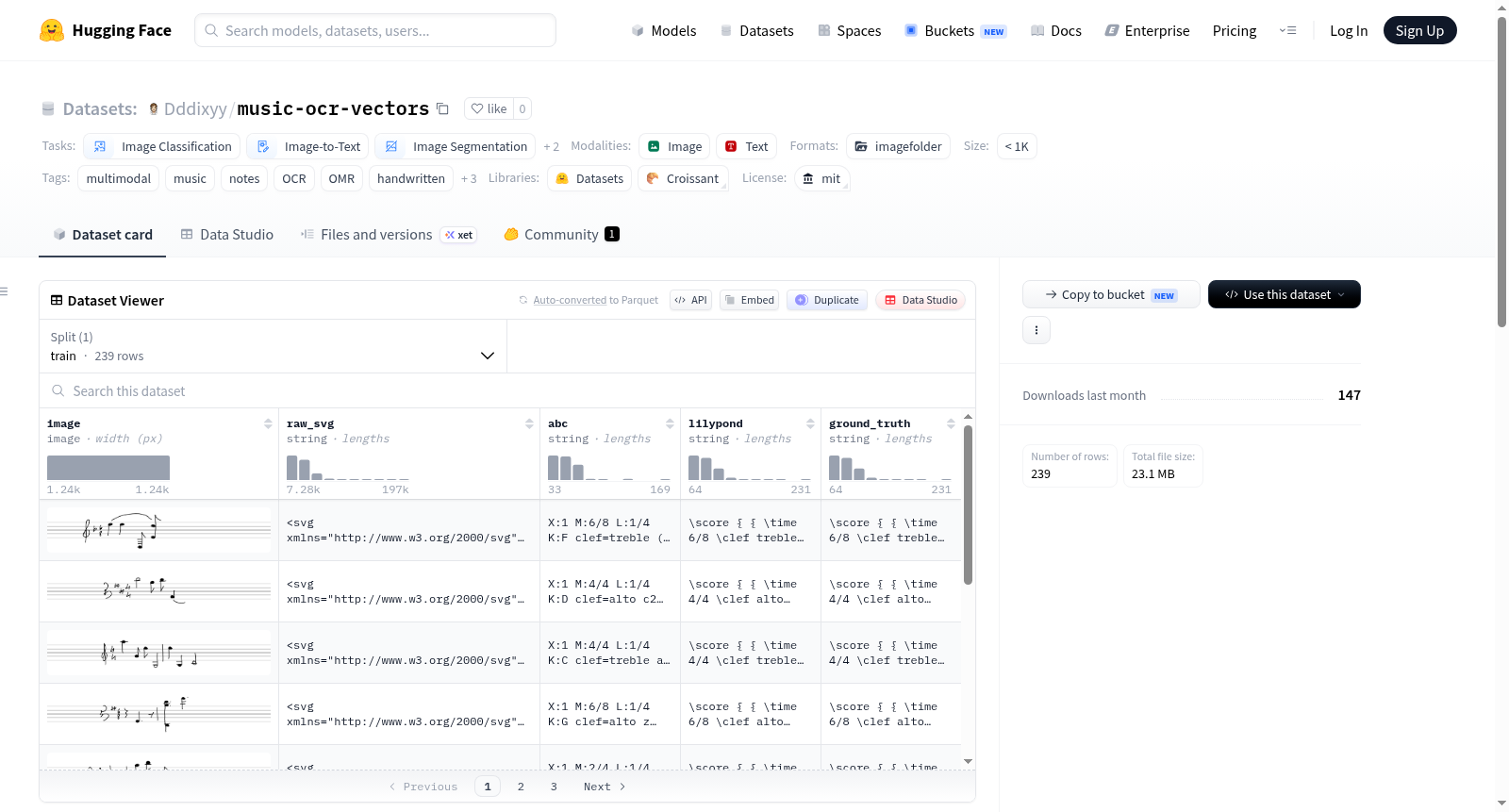
Music-OCR-Vectors(在HuggingFace上显示为ScoreStroke)是一个开源免费的数据集,专为光学音乐识别、机器学习和计算机视觉研究设计。其核心目标是桥接手写音乐符号与机器可读格式之间的鸿沟。数据集包含手绘乐谱及其对应的多种数字表示形式:SVG矢量图形(用于精确视觉布局和笔画路径)、ABC记谱法(用于轻量级文本序列表示)和LilyPond文件(用于高质量专业数字排版)。该数据集适用于多种任务,包括训练模型进行手写音乐到可播放/可编辑数字格式的转换(OMR)、图像到文本的序列到序列模型训练(如图像到ABC记谱法)、基于图像和SVG的栅格到矢量转换模型训练,以及手写分析和生成式AI应用。数据集起源于热那亚大学学生Davide Brunori的想法和基础工作,采用MIT许可证,允许无限制地用于学术研究、个人项目和商业应用。
Music-OCR-Vectors (displayed as ScoreStroke on HuggingFace) is an open-source, free dataset designed for optical music recognition (OMR), machine learning, and computer vision research. It aims to bridge the gap between handwritten music notation and machine-readable formats. The core content consists of hand-drawn music scores and their corresponding digital representations: SVG vector graphics for precise visual layout and stroke paths, ABC notation for lightweight text sequence representation, and LilyPond (.ly) files for high-quality professional digital typesetting. The dataset is suitable for various tasks, such as training models for converting handwritten music to playable/editable digital formats (OMR), image-to-text sequence-to-sequence model training (e.g., image to ABC notation), raster-to-vector conversion model training based on images and SVGs, and handwriting analysis and generative AI applications. It originated from the idea and foundational work of Davide Brunori, a student at the University of Genoa, and is licensed under the MIT license, allowing unrestricted use for academic research, personal projects, and commercial applications.
创建时间:
2026-05-18
搜集汇总
数据集介绍
构建方式
Music-OCR-Vectors数据集,亦称ScoreStroke,由热那亚大学的学生Davide Brunori原创构建,旨在弥合手写乐谱与机器可读格式之间的鸿沟。该数据集的核心构建方式在于为每一份手绘乐谱提供三重标注:首先以SVG格式记录精确的视觉布局与笔画路径,其次以ABC Notation这一轻量级文本序列格式保存,最后还包含LilyPond(.ly)格式用于高质量的专业数字排版。这种多模态对齐的构建策略,使得数据在图像、矢量与文本三个层面均有一一对应的Ground Truth,为后续模型训练奠定了结构化的基础。
特点
本数据集的一大显著特点在于其高度的通用性与开放性。它涵盖了图像分类、图像转文本、图像分割、目标检测与翻译等多种任务类型,具备多模态标签,支持手写与数字乐谱的混合应用。许可证采用MIT协议,意味着数据集可毫无限制地用于学术研究、个人项目乃至商业用途。此外,SVG矢量格式的引入使得模型能够学习从光栅图像到矢量笔画的转换,赋予了数据集在光栅到矢量转换、手写分析与生成式AI等前沿领域的独特应用价值。
使用方法
Music-OCR-Vectors数据集的使用方式极为灵活。在光学乐谱识别(OMR)中,研究者可利用手写乐谱图像与其对应的ABC或LilyPond文本,训练序列到序列(seq2seq)模型,实现从图像到可编辑数字格式的自动转换。对于图像转文本任务,可直接使用图像与ABC标注进行端到端训练。针对光栅到矢量转换,图像与SVG对的组合为模型提供了学习笔画矢量化的绝佳素材。数据集已托管于Hugging Face平台,支持直接通过`datasets`库加载,同时兼容标准的图像分类与目标检测流程,便于集成到现有的深度学习框架中。
背景与挑战
背景概述
光学乐谱识别(OMR)作为音乐信息检索领域的核心分支,致力于将乐谱图像转化为可编辑、可播放的数字格式,其发展面临着手写乐谱形态多样性与机器可读表示之间鸿沟的挑战。在此背景下,Music-OCR-Vectors数据集由热那亚大学学生Davide Brunori创建,于近年发布,旨在为手写乐谱与其数字向量及文本表示之间搭建桥梁。该数据集为每张手写乐谱提供SVG、ABC记谱法和LilyPond三种标准格式的真值标注,覆盖图像分类、图像到文本翻译、图像分割、目标检测与翻译等多模态任务。作为开源资源,其无限制许可条款极大促进了OMR、机器学习与计算机视觉领域的交叉研究,对推动手写乐谱数字化、序列到序列模型训练及笔迹分析等方向具有重要影响力。
当前挑战
该数据集主要解决手写乐谱光学识别这一领域难题,其核心挑战在于将非结构化的手写图像精准转换为多种机器可读格式,这要求模型能够克服手写风格多变、笔画粘连、符号尺度不一等视觉歧义性。在构建过程中,挑战首先体现在真值标注的复杂性上:需要为同一张手写乐谱同时生成SVG路径、ABC纯文本序列及LilyPond专业排版本,三者格式差异巨大且需严格保持语义一致性,对标注流程的协调性与准确性提出极高要求。此外,手写样本的采集与向量化处理面临噪声干扰与书写质量参差的问题,现有数据规模尚需通过社区贡献持续扩充,以覆盖更广泛的书写习惯与排版变异,从而提升模型的泛化能力。
常用场景
经典使用场景
Music-OCR-Vectors数据集专为光学音乐识别(OMR)领域设计,其核心应用在于将手绘乐谱图像自动转换为可编辑、可播放的数字格式。研究者可利用该数据集训练模型,实现从乐谱图像到ABC记谱法或LilyPond文本的序列转换,从而精准捕捉音符、节奏及符号布局。此外,数据集中的图像与SVG矢量对为光栅到矢量的转换研究提供了基础,支持模型学习手写笔画的几何特征与语义信息,进而提升OCR系统在音乐符号识别中的鲁棒性和准确性。
实际应用
在现实场景中,Music-OCR-Vectors可直接服务于音乐数字化存档与教育辅助工具的开发。例如,音乐教师或学生的手写乐谱可通过基于该数据集训练的模型快速转换为标准数字乐谱,便于编辑、打印或共享。此外,该技术可集成至音乐创作软件中,实现手稿草图的即时数字化,或应用于古籍乐谱的修复与传播,降低传统人工转录的时间和精力消耗,提升文化遗产保护效率。同时,其SVG输出特性支持艺术家对手写字体的风格分析与生成。
衍生相关工作
基于此数据集,研究者已衍生出多项前沿工作,包括开发针对手写乐谱的图像到ABC记谱法的序列转换模型,以及利用条件生成对抗网络实现矢量路径预测。此外,结合Transformer架构的端到端OMR系统被提出,显著提升了复杂乐谱的识别精度。在生成领域,该数据集被用于训练风格迁移模型,以合成仿手绘的乐谱图像,从而扩充训练数据。这些工作不仅深化了多模态学习在音乐场景的落地,也为通用手写识别与光栅到矢量转化任务提供了新范式。
以上内容由遇见数据集搜集并总结生成


