SpatialViz-Bench
收藏Hugging Face2025-05-28 更新2025-05-29 收录
下载链接:
https://huggingface.co/datasets/Anonymous285714/SpatialViz-Bench
下载链接
链接失效反馈官方服务:
资源简介:
空间可视化基准数据集,用于评估多模态大型语言模型的空间可视化能力,包括心理旋转、心理折叠、视觉穿透和心理动画四个子能力的12个任务,每个任务分为不同难度级别,共计1180个问题-答案对。
This is a spatial visualization benchmark dataset intended to evaluate the spatial visualization abilities of multimodal large language models. It includes 12 tasks covering four sub-capabilities: mental rotation, mental folding, visual penetration, and mental animation. Each task is divided into different difficulty levels, and the dataset totals 1180 question-answer pairs.
创建时间:
2025-05-16
原始信息汇总
Spatial Visualization Benchmark 数据集概述
数据集基本信息
- 语言: 英文
- 许可证: MIT
- 数据集大小: 916235 字节
- 下载大小: 63865 字节
- 测试集样本数: 1180 个
数据集结构
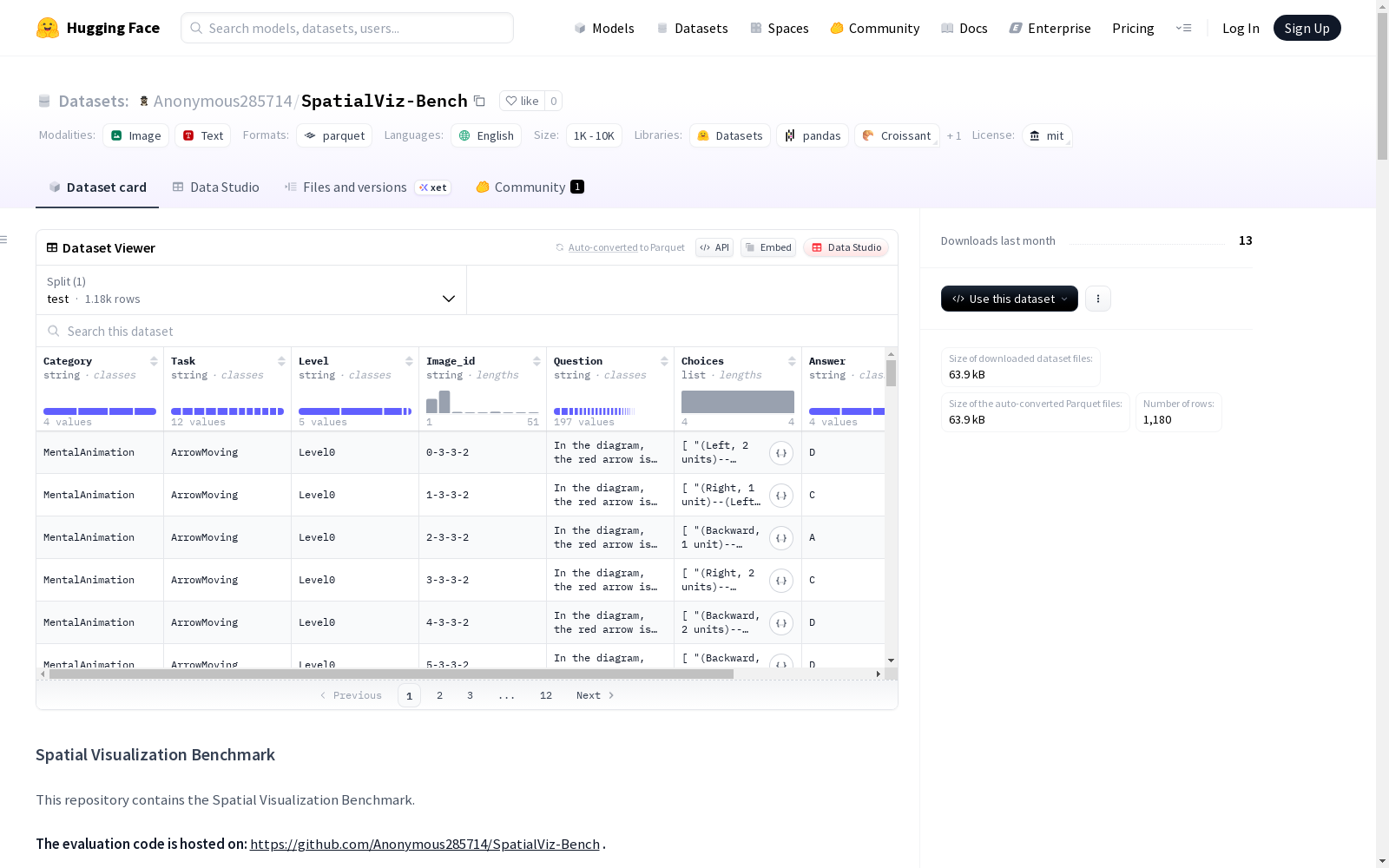
特征
Category: 字符串,表示类别Task: 字符串,表示任务Level: 字符串,表示难度级别Image_id: 字符串,表示图像IDQuestion: 字符串,表示问题Choices: 字符串列表,表示选项Answer: 字符串,表示正确答案Explanation: 字符串,表示解释
数据分割
- test: 包含所有测试数据
数据集描述
SpatialViz-Bench 旨在评估多模态大语言模型的空间可视化能力,这是空间能力的关键组成部分。针对空间可视化的4个子能力(心理旋转、心理折叠、视觉穿透和心理动画),设计了12个任务,每个任务分为2或3个难度级别,共包含1180个问答对。
空间可视化子能力
-
Mental Rotation (心理旋转)
- 2D Rotation
- 3D Rotation
- Three-view Projection
-
Mental Folding (心理折叠)
- Paper Folding
- Cube Unfolding
- Cube Reconstruction
-
Visual Penetration (视觉穿透)
- Cross-Section
- Cube Count Inference
- Sliding Blocks
-
Mental Animation (心理动画)
- Arrow Movement
- Block Movement
- Mechanical System
数据集使用
数据下载
- 数据集可通过
load_dataset("Anonymous285714/SpatialViz-Bench")加载。 - 图像数据以
*.zip形式提供,目录结构按类别、任务和级别组织。
数据格式
- 图像路径格式:
./SpatialViz_Bench_images/{Category}/{Task}/{Level}/{Image_id}.png - 数据以 Parquet 格式提供,包含完整标注。
评估指标
- 所有任务均为多选题,每题仅有一个正确答案。
- 模型性能基于回答准确率评估。
其他信息
- 评估代码托管地址: https://anonymous.4open.science/r/benchmark12tasks1180cases/
搜集汇总
数据集介绍
构建方式
在空间可视化能力评估领域,SpatialViz-Bench数据集的构建采用了系统化的分层设计方法。该数据集围绕空间可视化的四个核心子能力——心理旋转、心理折叠、视觉穿透和心理动画展开,每个子能力下设三个具体任务,形成包含12个任务的综合评估体系。每个任务进一步划分为2至3个难度等级,通过控制图像复杂度、操作步骤数量等变量生成不同层级的测试用例,最终构建出1180个高质量的问答对,确保了评估维度的全面性和层次性。
特点
SpatialViz-Bench数据集的特点体现在其多维度的评估体系设计上。数据集通过四个核心空间能力模块覆盖了从二维旋转到三维机械系统分析的广泛场景,每个模块下的任务均设有渐进式难度等级。测试案例采用图像与文本相结合的多模态形式呈现,所有问题均设计为具有唯一正确答案的多选题格式。数据集特别注重现实场景的模拟,例如通过立方体堆叠尺寸、纸张折叠操作次数等参数来精确控制任务复杂度,为模型能力评估提供细粒度的区分维度。
使用方法
该数据集的使用需结合图像文件与标注数据共同处理。用户可通过HuggingFace Datasets库直接加载Parquet格式的标注文件,同时按照预设的层级目录结构解压图像资源。每个数据样本包含类别、任务、难度等级等元数据信息,研究者可通过拼接文件路径的方式关联图像与标注。评估时需将模型输出与标注中的标准答案进行比对,采用准确率作为核心评估指标。数据集专门设计了包含错误选项解析的说明字段,为模型错误分析提供参考依据。
背景与挑战
背景概述
空间可视化能力作为认知科学和人工智能交叉领域的重要研究方向,SpatialViz-Bench数据集由匿名研究团队于2024年构建,旨在系统评估多模态大语言模型在空间认知方面的表现。该基准聚焦心理旋转、心理折叠、视觉穿透和心理动画四大核心子能力,通过12项任务构建了包含1180个问答对的层次化评估体系。其创新性在于将经典空间认知理论转化为可量化的计算任务,为智能体的空间推理能力提供了标准化测评框架,对自动驾驶、机器人导航等需空间理解的应用领域具有推动作用。
当前挑战
该数据集需解决空间认知任务中动态几何变换的抽象表征难题,例如三维物体旋转的视角一致性、多步骤折叠操作的逻辑链建模等核心挑战。构建过程中面临双重困难:一是需平衡任务复杂度与标注可扩展性,如心理动画任务需模拟连续运动轨迹而保持选项无歧义;二是确保视觉刺激的生态效度,如在立方体展开任务中需控制图案对称性以避免解题捷径,同时维持跨任务难度梯度的系统性。
常用场景
经典使用场景
在空间认知研究领域,SpatialViz-Bench数据集被广泛用于评估多模态大语言模型的空间可视化能力。该数据集通过涵盖心理旋转、心理折叠、视觉穿透和心理动画四大子能力,构建了包含12项任务的综合评估体系。研究者通常利用该数据集对模型进行系统性测试,通过多层级难度设计揭示模型在空间推理任务中的表现差异,为模型优化提供精准诊断依据。
衍生相关工作
基于该数据集提出的评估范式,已催生多项关注空间推理可解释性的研究。部分工作尝试将神经符号推理框架引入多模态模型,以提升其在心理旋转等任务中的表现。另有研究受其启发开发了针对特定子能力的增强训练方法,这些衍生工作共同推动了空间认知计算研究向更精细化方向发展。
数据集最近研究
最新研究方向
在空间认知与多模态人工智能交叉领域,SpatialViz-Bench作为首个系统评估空间可视化能力的基准数据集,正推动多模态大模型在心理旋转、折叠、透视和动态模拟等核心子能力的前沿探索。当前研究聚焦于提升模型对复杂空间关系的动态推理能力,尤其在三维几何变换、机械系统动画预测等任务中,结合神经符号计算与视觉-语言对齐技术,以解决模型在跨模态空间推理中的泛化瓶颈。这一方向不仅呼应了自动驾驶、机器人导航等实际场景中对空间智能的迫切需求,也为认知科学与人工智能的深度融合提供了可量化的评估框架。
以上内容由遇见数据集搜集并总结生成


