SynGrasp-1B
收藏arXiv2025-05-06 更新2025-05-08 收录
下载链接:
https://pku-epic.github.io/GraspVLA-web
下载链接
链接失效反馈官方服务:
资源简介:
SynGrasp-1B 是一个包含十亿帧的机器人抓取数据集,由先进的射线追踪渲染和物理模拟生成,是全球首个此类规模的抓取数据集。该数据集包含了来自 240 个类别的 10,000 个独特物体,并进行了广泛的领域随机化,以确保广泛的几何和视觉变化。该数据集的创建旨在为机器人抓取任务提供一个基础模型,通过模拟数据和互联网语义数据联合训练,以实现零样本泛化和对特定人类偏好的少样本适应性。该数据集的创建过程包括了对象资产和布局生成、抓取合成和轨迹生成、视觉随机化和渲染等步骤。该数据集的应用领域包括机器人抓取任务,旨在解决机器人抓取任务中的零样本泛化和少样本适应性问题。
SynGrasp-1B is a 1-billion-frame robotic grasping dataset generated via advanced ray-tracing rendering and physical simulation, and it is the world's first grasping dataset of this scale. It encompasses 10,000 unique objects across 240 categories, with extensive domain randomization applied to ensure broad geometric and visual diversity. This dataset was developed to serve as a foundational resource for robotic grasping tasks, enabling zero-shot generalization and few-shot adaptation to specific human preferences through joint training on simulated data and internet-derived semantic data. The dataset's creation workflow includes steps such as object asset and layout generation, grasp synthesis and trajectory generation, visual randomization and rendering, among others. Targeting applications in robotic grasping, this dataset aims to address the challenges of zero-shot generalization and few-shot adaptation in robotic grasping tasks.
提供机构:
北京大学
创建时间:
2025-05-06
原始信息汇总
GraspVLA: 基于十亿级合成动作数据预训练的抓取基础模型
摘要
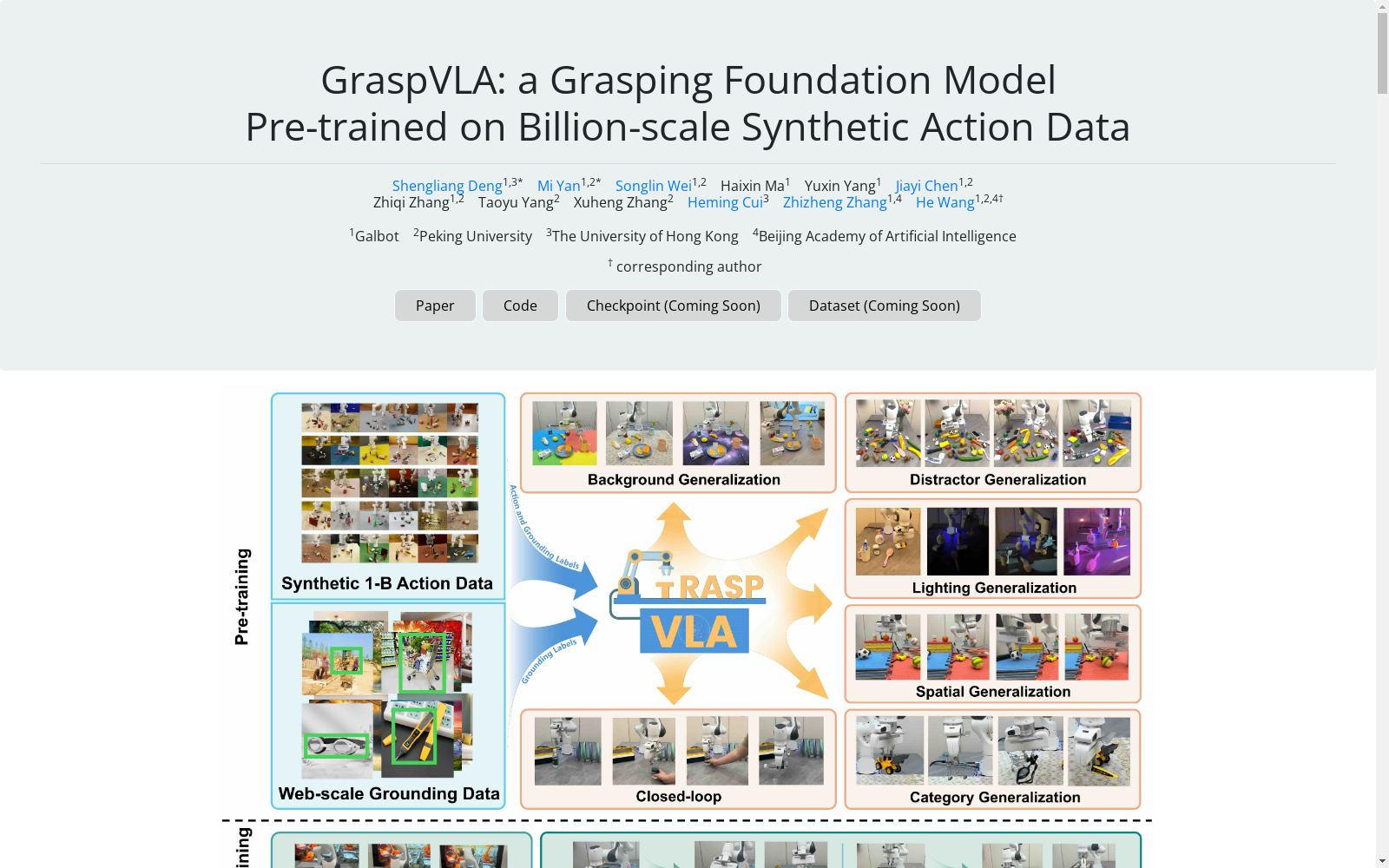
- 探索完全使用大规模合成动作数据训练视觉-语言-动作(VLA)模型的可行性
- 构建SynGrasp-1B数据集:包含十亿帧仿真生成的机器人抓取数据,具有照片级真实感渲染和广泛领域随机化
- 提出GraspVLA模型:将自回归感知任务和基于流匹配的动作生成统一到思维链过程中
- 特点:可联合训练合成动作数据和互联网语义数据,减轻仿真到现实的差距,实现开放词汇抓取泛化
零样本评估
GraspVLA在6个方面展示强大的零样本泛化能力:
- 干扰物泛化:处理30+干扰物的杂乱场景和动态干扰物
- 光照变化泛化:适应各种光照条件,包括黑暗环境
- 空间变化泛化:处理不同高度的球体和不同平面姿态的鸡蛋
- 背景变化泛化:适应不同纹理的桌面和变色墙面
- 类别泛化:通过互联网数据共训练,可泛化到新类别
- 闭环控制:自动调整响应干扰直至任务完成
高效后训练
- 工业场景:少量边界框标注数据即可掌握稀有零件
- 零售场景:少量轨迹数据可学习密集包装环境中的顺序拾取行为
- 家庭场景:少量演示可学习特定抓取姿态偏好并泛化到新杯子
SynGrasp-1B数据集
- 规模:十亿帧仿真抓取数据
- 特点:照片级真实感渲染,包含机器人姿态、物体姿态、背景、光照和材质的领域随机化
- 生成流程:
- 从Objaverse的240个类别中选择10,000+物体网格
- 使用BoDex生成稳定抓取,CuRobo规划抓取轨迹
- 应用材质、光照、相机视角和背景的领域随机化
模型架构
- 组成:自回归视觉语言主干 + 基于流匹配的动作专家
- 机制:渐进动作生成
- 预测合成数据和网络数据的2D边界框
- 额外生成合成数据的抓取姿态和分块动作
联系方式
- Shengliang Deng: sldeng@cs.hku.hk
- Mi Yan: dorisyan@pku.edu.cn
搜集汇总
数据集介绍
构建方式
SynGrasp-1B数据集的构建采用了先进的仿真技术与多样化场景设计相结合的方法。研究团队从Objaverse数据集中精选了10,680个适合桌面抓取的物体实例,涵盖240个不同类别。通过物理仿真引擎MuJoCo和光线追踪渲染器Isaac Sim,生成了包含丰富视觉变化和物理特性的抓取场景。数据生成流程包含三个核心环节:物体布局生成采用随机缩放和抛掷策略创建物理合理的场景;抓取轨迹生成结合了专业的抓取合成算法和运动规划技术;视觉渲染环节则通过随机化光照、背景和摄像机参数来增强数据的多样性。整个构建过程在160块NVIDIA 4090 GPU上耗时10天完成,最终形成了包含十亿帧的规模化数据集。
特点
该数据集最突出的特点是其规模性和多样性。作为全球首个十亿量级的机器人抓取数据集,SynGrasp-1B通过系统性的领域随机化策略,覆盖了物体几何形态、材质属性、光照条件等多维度的变化。数据集包含双视角的RGB图像序列,每帧都配有精确的抓取位姿标注和自然语言指令。特别值得注意的是,数据集设计了四种专业化泛化场景:背景泛化、空间泛化、类别泛化和干扰物泛化,这些设计显著提升了模型在真实环境中的适应能力。此外,闭环验证机制确保了所有合成轨迹的物理合理性,为模仿学习提供了高质量的示范数据。
使用方法
SynGrasp-1B数据集主要服务于视觉-语言-动作(VLA)模型的预训练。研究人员提出的GraspVLA框架采用渐进式动作生成机制,将数据集中的合成动作数据与互联网语义数据协同训练。具体使用时,模型的视觉语言模块首先处理观测图像和文本指令,预测目标物体的2D边界框;随后基于机器人基坐标系生成抓取位姿;最终由动作专家模块输出末端执行器的动作序列。这种链式推理架构有效缩小了仿真与现实间的差距。数据集支持开箱即用的零样本迁移,也可通过少量真实场景的微调样本(约100个示范)快速适应特定任务需求,如工业零件抓取或卫生敏感场景的抓取约束。
背景与挑战
背景概述
SynGrasp-1B数据集是由Galbot、北京大学和香港大学的研究团队于2025年推出的十亿规模机器人抓取仿真数据集。作为首个完全基于合成数据训练视觉-语言-动作(VLA)模型的基准数据集,其核心研究目标是通过高保真物理仿真和光线追踪渲染技术,解决真实世界数据采集成本高昂、规模受限的难题。该数据集包含240个类别、10,680个独特物体的抓取轨迹,通过域随机化技术覆盖几何形态、材质属性和环境光照的广泛变化,为GraspVLA基础模型提供训练支撑,显著推动了具身智能领域从仿真到现实的迁移学习研究。
当前挑战
SynGrasp-1B面临的挑战主要体现在两方面:在领域问题层面,需突破开放词汇抓取中语义-动作对齐的难题,解决传统方法对透明物体、长尾类别物体的识别局限;在构建过程层面,需平衡仿真数据的物理精确性与生成效率,设计异步写入与并行渲染框架以处理十亿级数据规模,同时通过单步运动规划优化轨迹平滑度以克服模仿学习中常见的动作犹豫问题。此外,如何通过渐进式动作生成机制融合互联网语义数据与合成动作数据,也是实现跨模态知识迁移的关键挑战。
常用场景
经典使用场景
SynGrasp-1B数据集作为目前全球首个十亿规模级的机器人抓取仿真数据集,其经典使用场景聚焦于视觉-语言-动作(VLA)模型的预训练领域。通过240个类别、10,680个物体的高保真物理仿真与光线追踪渲染,该数据集为研究者提供了涵盖几何形态、材质属性、光照条件等多维度随机化的训练环境。典型应用包括开发如GraspVLA等基础模型,通过模拟数据训练实现开环抓取策略的零样本迁移,尤其在透明物体、长尾类别物体等传统算法表现薄弱的场景中展现显著优势。
实际应用
在工业自动化领域,SynGrasp-1B支持开发适应非结构化环境的抓取系统,如物流分拣中处理透明包装或异形零件;服务机器人场景中,模型可基于自然语言指令实现家居物品的精准抓取,如"拾取内壁无接触的水杯"等复杂约束任务。医疗辅助领域则受益于其对长尾物品(如手术器械)的泛化能力。实际测试表明,在包含干扰物、动态光照等挑战性环境下,基于该数据训练的模型抓取成功率可达93.3%,较传统方法提升近30%。
衍生相关工作
SynGrasp-1B催生了多项里程碑式研究:GraspVLA首次验证纯合成数据预训练VLA模型的可行性;其PAG机制启发了后续如CoT-VLA等思维链推理框架在机器人控制中的应用。数据集构建方法为DexMimicGen等双边操作数据集提供技术范本,而异步渲染与并行物理模拟技术则被SkillMimicGen等数据生成系统继承。在算法层面,基于该数据的流匹配动作生成范式影响了RDT-1B等扩散策略模型的设计。
以上内容由遇见数据集搜集并总结生成


