MERA Multi
收藏arXiv2025-11-19 更新2025-11-21 收录
下载链接:
https://mera.a-ai.ru/ru/multi
下载链接
链接失效反馈官方服务:
资源简介:
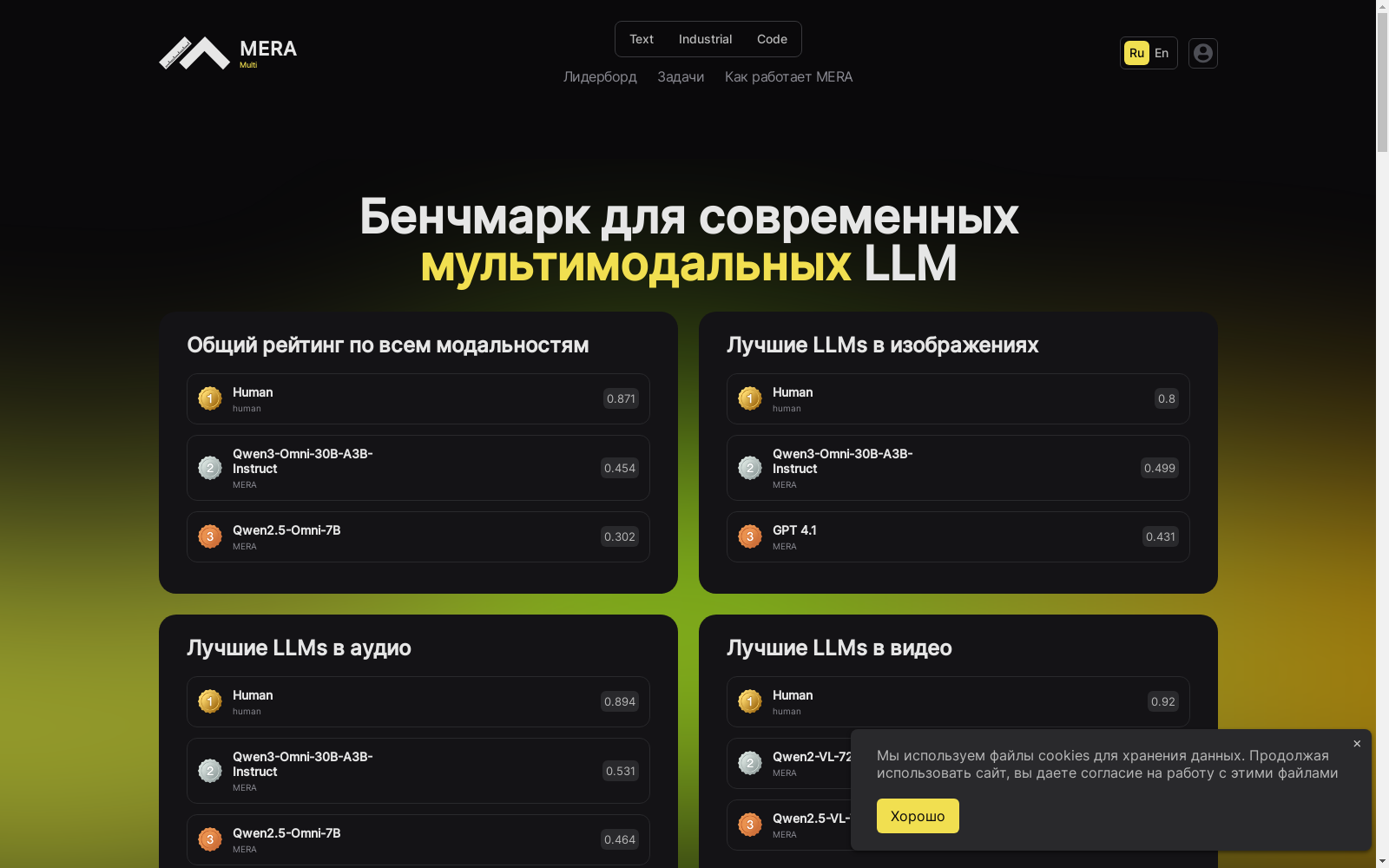
MERA Multi是由俄罗斯MERA团队构建的首个俄语多模态评估基准,涵盖文本、图像、音频和视频四种模态的18个专项任务。该数据集包含从零构建的11个私有数据集和7个公开数据集,总样本量达两万余条,数据来源融合了俄罗斯文化特色与语言特性。创建过程采用统一的技能分类法和块提示结构,通过人工标注与开源数据整合确保数据质量。该基准主要应用于多模态大语言模型的能力评估,旨在解决俄语语境下跨模态理解的文化适应性与评估标准化问题。
MERA Multi is the first Russian-language multimodal evaluation benchmark constructed by Russia's MERA team, covering 18 specialized tasks across four modalities: text, image, audio, and video. This benchmark comprises 11 newly built private datasets and 7 public datasets, with a total of over 20,000 samples. Its data sources incorporate Russian cultural traits and linguistic peculiarities. During its development, a unified skill taxonomy and chunked prompt structure were employed, and data quality was guaranteed via manual annotation and integration of open-source data. This benchmark is primarily utilized for evaluating the capabilities of multimodal large language models (LLMs), aiming to address the challenges of cultural adaptability and evaluation standardization for cross-modal understanding within the Russian language context.
提供机构:
MERA团队
创建时间:
2025-11-19
搜集汇总
数据集介绍
构建方式
MERA Multi数据集采用多模态融合的构建策略,涵盖文本、图像、音频和视频四种模态,通过18个任务系统化评估模型能力。构建过程分为公开数据集整合与私有数据集原创开发两个维度:7个任务源自公开数据源的筛选与重构,11个任务则基于俄罗斯文化语境全新构建。私有数据集采用专家指导与众包标注相结合的方式,通过Telegram机器人收集本土化多媒体素材,并运用ABC Elementary平台进行三轮交叉验证,确保数据质量与文化适配性。所有数据均经过严格的内容保护处理,包括数字水印嵌入和成员推理攻击检测机制。
特点
该数据集在语言学与模态覆盖层面具有显著特色。作为首个俄语多模态基准测试框架,其深度整合斯拉夫语言特性与东欧文化元素,涵盖民间传说、苏联媒体等本土化语义场景。任务设计采用统一的能力分类体系,将18个任务映射至感知、知识与推理三大认知维度,每个任务均评估多重能力组合。评估机制创新性地融合精确匹配与语义评分双轨指标,通过定制化评判模型实现生成内容的语义等价性判定。数据保护体系包含技术层面水印嵌入与法律层面专用许可协议,构建了完整的防泄露生态。
使用方法
数据集采用模块化评估管道,支持通用模型与模态专用架构的标准化测试。评估流程基于扩展的lm-eval框架实现,通过块提示技术生成10种标准化指令变体,有效控制提示工程偏差。模型需处理线性化多模态输入,生成开放式答案直至终止条件触发。评分系统综合精确匹配与评判模型得分,最终采用模态加权算法计算覆盖度调整后的总分。提交系统通过自动化平台实现,用户需克隆代码库生成提交文件,经专家验证后可公开至排行榜。私有数据集仅限基准测试使用,严格禁止模型训练用途。
背景与挑战
背景概述
MERA Multi数据集由MERA团队于2025年创建,旨在填补俄语多模态大语言模型评估领域的空白。该数据集作为首个针对俄语的多模态基准框架,由Artem Chervyakov、Alena Fenogenova等核心研究人员主导开发,聚焦于解决多模态模型在俄语语境下的智能理解、局限性及风险等核心研究问题。其创新性体现在融合文本、图像、音频和视频四类模态,通过构建涵盖18项任务的评估体系,显著推动了斯拉夫语系乃至形态丰富语言的多模态研究进展,并为跨语言文化适应性评估提供了可复现的方法论基础。
当前挑战
该数据集面临的挑战主要体现在领域问题与构建过程两方面:在领域层面,需解决多模态模型对俄语文化特异性(如民俗、苏联媒体等)的认知鸿沟,以及跨模态语义对齐与推理能力的统一评估;构建过程中,克服了数据收集的文化适配性难题,包括从零创建涵盖多元场景的私有数据集,并设计防泄漏机制如数字水印与许可协议,确保评估结果免受训练数据污染影响。
常用场景
经典使用场景
在俄语多模态大语言模型评估领域,MERA Multi数据集作为首个针对俄语文化的多模态基准测试框架,其经典使用场景体现在对图像、音频、视频与文本融合理解能力的系统性测评。该数据集通过18个精心构建的任务单元,覆盖了从基础感知到复杂推理的多层次能力评估,特别注重俄罗斯文化语境下的语言特性与视觉元素关联,为模型在跨模态信息处理中的表现提供了标准化测量环境。
实际应用
在实际应用层面,MERA Multi为俄语区智能语音助手、跨模态搜索引擎等产品提供了关键性能验证标准。其涵盖的视觉问答、音频场景分析等任务直接对应现实场景中的医疗表格解析、环境音识别等需求,而视频理解模块则支撑着安防监控、教育课件分析等产业应用。通过水印技术与许可证管理,该数据集确保了商业应用中的知识产权保护,为俄语多模态技术的产业化落地构建了安全可靠的测试基础。
衍生相关工作
该数据集催生了多模态能力分类学的系统化研究,其提出的块提示结构与双指标评估体系已被后续工作广泛采纳。基于其构建的MSMIA数据泄漏检测方法推动了模型训练透明度研究的发展,而统一评估框架则启发了包括东欧语系在内的多语言多模态基准建设浪潮,为跨文化人工智能评估建立了可扩展的技术蓝图。
以上内容由遇见数据集搜集并总结生成


