TIME
收藏arXiv2026-02-13 更新2026-02-15 收录
下载链接:
https://huggingface.co/spaces/Real-TSF/TIME-leaderboard
下载链接
链接失效反馈官方服务:
资源简介:
TIME是由南洋理工大学等机构联合构建的新一代时间序列预测基准,包含50个原创数据集和98个任务,严格避免数据泄露风险。数据集通过政府公开数据、产业合作等多渠道获取,并采用人机协同的自动化筛查流程确保数据质量,涵盖多元领域和频率的时序特征。其创新性地提出模式级评估视角,通过结构分解和时序特征编码实现跨数据集的通用能力分析,旨在为零样本时序基础模型提供更贴近真实场景的评估框架。
TIME is a next-generation time series forecasting benchmark jointly developed by Nanyang Technological University and other institutions. It includes 50 original datasets and 98 tasks, strictly avoiding data leakage risks. The datasets are collected from multiple channels such as government open data and industrial collaborations, and an automated human-machine collaborative screening process is adopted to ensure data quality, covering time series features across diverse domains and sampling frequencies. It innovatively proposes a pattern-level evaluation perspective, enabling cross-dataset general capability analysis through structural decomposition and time series feature encoding, aiming to provide a more real-scenario-aligned evaluation framework for zero-shot time series foundation models.
提供机构:
南洋理工大学; 格里菲斯大学; DataDog; 清华大学; Squirrel Ai Learning
创建时间:
2026-02-13
搜集汇总
数据集介绍
构建方式
在时间序列预测领域,基准测试的数据质量和任务设计对模型评估的可靠性至关重要。TIME基准采用了一套严谨的人机协同构建流程,旨在解决现有基准中数据陈旧、质量参差不齐以及任务定义脱离实际应用的问题。该流程首先从政府门户、行业合作伙伴和开放平台等多样化来源精心筛选了50个全新数据集,确保数据的新颖性以避免因数据泄露导致的评估偏差。随后,通过自动化筛查与人工决策相结合的方式,对原始数据进行时间戳校正、规则验证、统计检验、极端值处理和相关性检查,生成详细的质量报告,并由领域专家和大型语言模型辅助进行最终审核与任务制定。任务配置严格遵循实际应用场景的需求,预测视野和测试长度均根据数据频率和业务背景进行定制化设计,从而保证了基准的高数据完整性和现实相关性。
使用方法
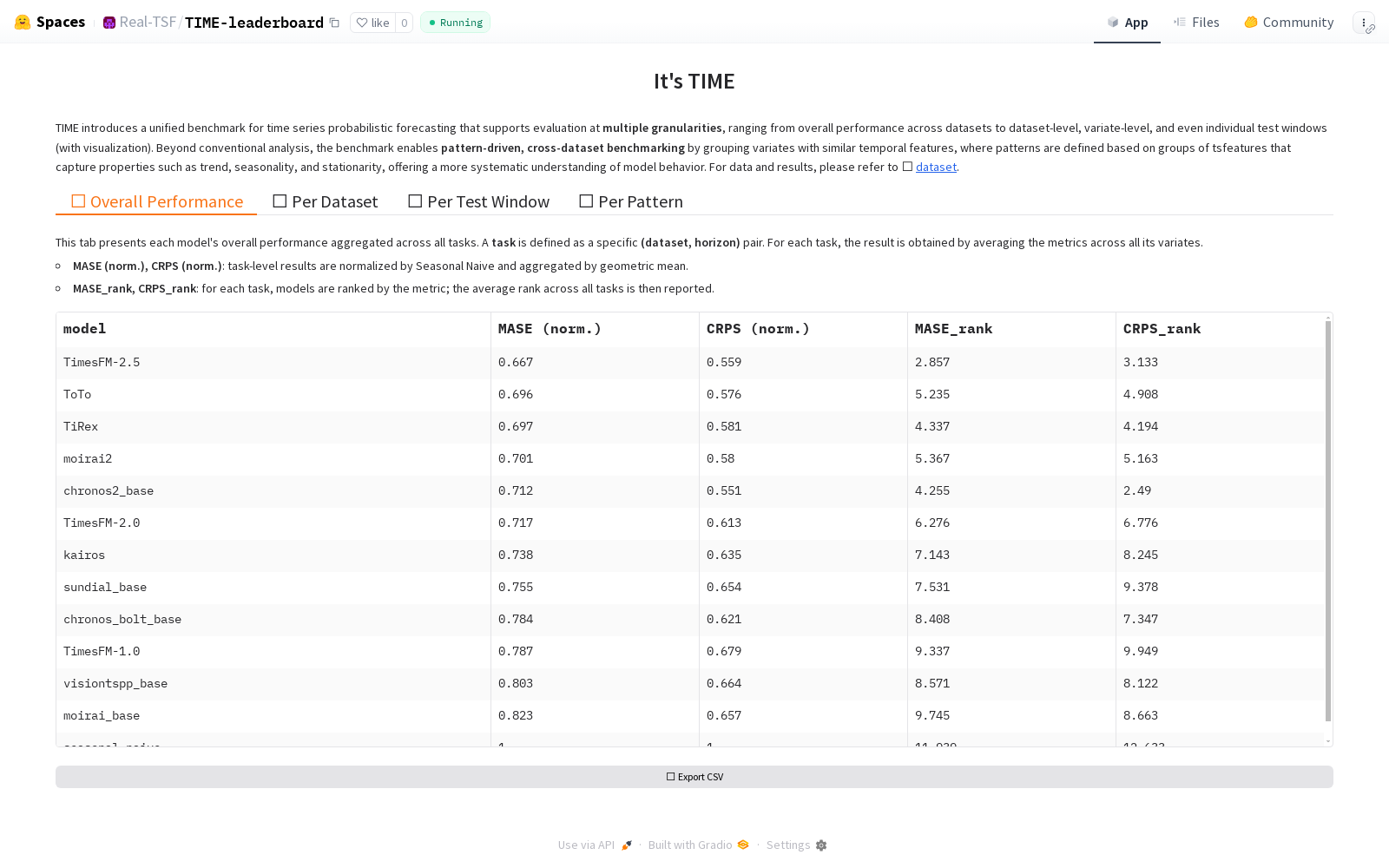
TIME基准为时间序列基础模型的评估提供了系统化的使用框架。研究人员可通过其公开的交互式排行榜进行多粒度分析,该排行榜集成了定量结果与定性可视化功能。评估时,需遵循其滚动窗口评估协议,使用平均绝对缩放误差和连续分级概率评分分别作为点预测和概率预测的指标。为了公平比较不同数据集中变量的内在可预测性差异,所有模型指标均相对于季节性朴素基线进行归一化处理,并使用几何平均数进行聚合。用户可以根据特定的时间模式(如强趋势或非平稳序列)检索对应的变量子集,进行针对性的模式级性能分析。此外,平台提供的预测可视化工具允许用户直接检查模型在不同时间尺度上的预测结果,将统计性能与预测的结构保真度相结合,从而更全面地理解模型行为,并为实际场景中的模型选择提供可操作的参考。
背景与挑战
背景概述
TIME数据集作为下一代时间序列预测基准,由南洋理工大学、清华大学、格里菲斯大学及DataDog等机构的研究团队于2026年2月联合推出,旨在应对时间序列基础模型评估中的结构性局限。该数据集聚焦于零样本泛化能力的严格评测,通过整合50个全新数据集与98项预测任务,构建了一个任务中心化的评估框架。其核心研究问题在于如何突破传统基准在数据覆盖、完整性、任务对齐及分析视角等方面的瓶颈,从而推动时间序列预测领域向更通用、更实用的评估范式演进。TIME的建立不仅为时间序列基础模型提供了无数据泄露的纯净测试环境,更通过模式级评估视角,为模型能力分析带来了可泛化的深刻见解。
当前挑战
TIME数据集致力于解决时间序列预测领域的两大核心挑战:在领域问题层面,传统基准常受限于数据陈旧、任务脱离实际场景以及评估指标抽象难解,导致模型排名与真实应用效能脱节;TIME通过引入新鲜数据、上下文对齐的任务设计及模式级分析,旨在提升评估的实用性与可解释性。在构建过程中,研究团队面临数据完整性保障的严峻考验,需通过自动化筛查与人工审核相结合的质量控制流程,剔除噪声、异常值及不可预测变量,同时确保任务配置符合现实操作需求与变量可预测性,这一过程对数据清洗与领域知识整合提出了极高要求。
常用场景
经典使用场景
在时间序列预测领域,TIME数据集作为新一代任务导向型基准,其经典应用场景在于对时间序列基础模型进行严格的零样本评估。该数据集通过整合50个全新数据集与98个预测任务,构建了一个无数据泄露风险的评估环境,使得研究者能够客观衡量模型在未见数据上的泛化能力。其任务配置紧密贴合现实世界的操作需求,例如针对不同频率数据设定合理的预测视野,从而确保评估结果具有实际参考价值。
解决学术问题
TIME数据集有效应对了现有时间序列预测基准在数据新鲜度、完整性和评估视角等方面的局限。它通过引入全新数据源和严格的人工参与质量保障流程,解决了传统基准因数据重复使用而导致的数据泄露问题。同时,数据集采用基于模式的分析方法,利用结构化的时间序列特征对变量进行编码,使得评估能够超越传统的元数据分类,从更本质的时间模式层面提供可泛化的性能洞察,从而推动时间序列预测研究向更严谨、更实用的方向发展。
实际应用
TIME数据集的实际应用广泛覆盖了能源、交通、金融、医疗等多个关键领域。例如,在能源管理中,数据集包含的太阳能发电和电力负荷序列可用于预测可再生能源的产出波动;在交通领域,停车场利用率和交通流量数据能够支持城市智慧交通系统的调度决策;在金融和经济分析中,加密货币价格、宏观经济指标等序列为风险管理和政策制定提供了可靠的预测基础。这些应用均体现了数据集在真实场景中的高度实用性和前瞻性。
数据集最近研究
最新研究方向
在时间序列预测领域,TIME数据集的推出标志着评估范式从传统数据集中心化向任务中心化的深刻转变。该数据集通过整合50个全新数据集和98个预测任务,严格避免了数据泄露风险,为零样本时间序列基础模型(TSFMs)的评估提供了纯净的测试环境。其前沿研究方向聚焦于模式级评估视角,利用结构时间序列特征对变量内在时序模式进行编码,实现了跨数据集的通用性能分析。这一方法突破了传统基于静态元标签的评估局限,能够揭示模型在趋势强度、季节性稳定性、平稳性等核心时序特性上的泛化能力。相关热点事件体现在对现有基准数据陈旧性、完整性不足及任务与现实脱节等瓶颈的系统性回应,推动了预测评估向更高数据完整性、任务对齐性和可解释性发展。TIME的影响在于为TSFMs的公平比较和深度诊断建立了新标准,其多粒度排行榜和可视化工具增强了结果的可操作性,为时间序列预测在金融、能源、交通等关键领域的可靠部署提供了科学依据。
相关研究论文
- 1It's TIME: Towards the Next Generation of Time Series Forecasting Benchmarks南洋理工大学; 格里菲斯大学; DataDog; 清华大学; Squirrel Ai Learning · 2026年
以上内容由遇见数据集搜集并总结生成


