Baidu_Tieba_KangYaBeiGuo
收藏Hugging Face2025-06-02 更新2025-06-03 收录
下载链接:
https://huggingface.co/datasets/Orphanage/Baidu_Tieba_KangYaBeiGuo
下载链接
链接失效反馈官方服务:
资源简介:
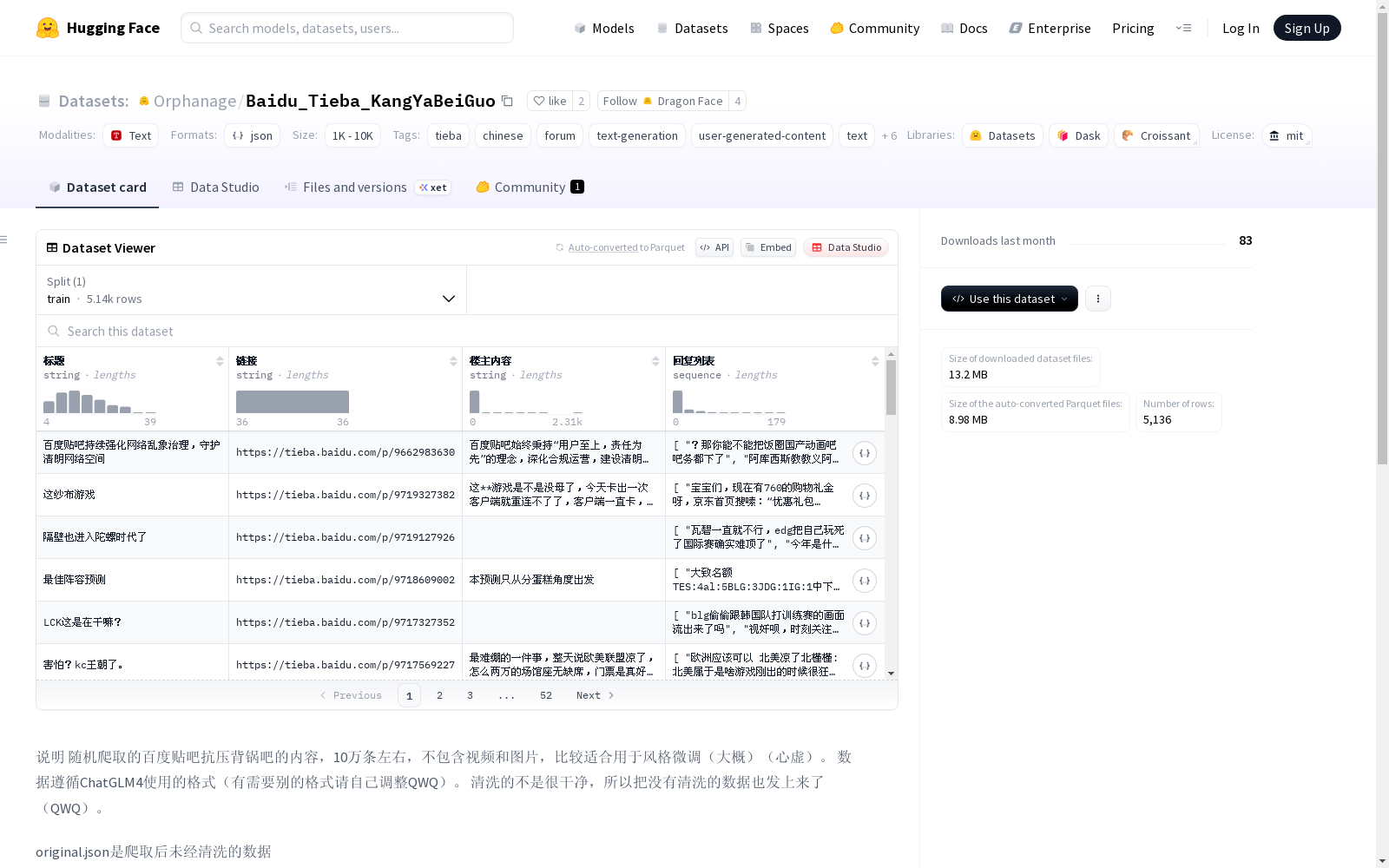
该数据集是从百度贴吧抗压背锅吧随机爬取的约10万条内容,不含视频和图片,适合用于文本风格的微调。数据集遵循ChatGLM4的格式,但数据清洗不够彻底,因此同时提供了未经清洗的原始数据。
This dataset contains approximately 100,000 text samples randomly crawled from the Anti-pressure and Blame-sharing Bar of Baidu Tieba, with no videos or images included. It is suitable for text style fine-tuning. The dataset follows the ChatGLM4 format, but the data cleaning is not thorough enough. Therefore, the unprocessed raw data is also provided alongside the cleaned dataset.
创建时间:
2025-05-29
搜集汇总
数据集介绍
构建方式
在中文网络论坛数据挖掘领域,Baidu_Tieba_KangYaBeiGuo数据集通过自动化爬虫技术从百度贴吧抗压背锅吧采集了约10万条用户生成内容。数据采集过程采用随机抽样策略,完整保留了文本交互的原始生态,同时排除了视频与图片等非文本元素。为保障数据完整性,研究者同步提供了未经清洗的原始数据文件original.json,这种双版本设计为文本质量研究提供了对比基准。
使用方法
研究者可借助该数据集开展中文自然语言生成模型的风格迁移训练,特别适用于游戏社区语言风格的适配性微调。使用前建议根据具体任务需求进行数据清洗与格式转换,原始数据与处理后数据可分别用于鲁棒性训练与精调实验。通过Hugging Face平台可直接加载数据集,引用时需遵循CC BY-NC 4.0协议并标注指定文献来源。
背景与挑战
背景概述
随着互联网社交平台的蓬勃发展,用户生成内容成为自然语言处理研究的重要资源。百度贴吧作为中文网络社区的代表性平台,其海量发帖数据为语言模型风格迁移研究提供了丰富素材。2025年,研究者Ziyu Zheng等人构建了Baidu_Tieba_KangYaBeiGuo数据集,聚焦网络论坛语言特性分析,旨在探索特定社区语境下的文本生成技术。该数据集收录抗压背锅吧约10万条用户对话,采用与ChatGLM4兼容的标注格式,为中文网络语言生态研究提供了专项语料支撑。
当前挑战
网络论坛文本建模需应对非规范语言表达的复杂性,该数据集针对游戏社区特有的术语混用、情绪化表达等语言现象提出解析挑战。数据构建过程中面临多模态内容过滤的技术难点,原始爬取数据包含大量需人工甄别的无效信息。用户生成内容固有的噪声问题要求开发更精细的清洗流程,而未标注的语境信息则增加了风格特征提取的难度,这些因素共同制约着数据质量的提升。
常用场景
经典使用场景
在中文自然语言处理领域,Baidu_Tieba_KangYaBeiGuo数据集为研究社区语言风格提供了丰富的素材。该数据集收录了百度贴吧抗压背锅吧的十万条用户生成内容,特别适用于对话系统和文本生成模型的风格微调任务。研究人员可以借助这些真实论坛数据,训练模型模仿特定网络社群的表达习惯,例如游戏社区中常见的调侃语气或情感化表达,从而提升生成文本的多样性和场景适应性。
解决学术问题
该数据集有效缓解了中文网络语言研究中的语料稀缺问题。通过提供大规模真实场景下的用户交互文本,它支持了网络语言演化分析、群体情感模式识别等研究方向。特别是在处理非规范网络用语和动态语言现象时,该数据集为构建更具鲁棒性的语言模型提供了实验基础,推动了计算语言学与社会计算的交叉研究。
实际应用
在实际应用层面,该数据集可服务于智能客服系统的语气适配训练,帮助AI更好地理解游戏玩家等特定用户群体的交流方式。内容审核领域也可利用这些数据构建毒性语言检测模型,识别网络论坛中的不当言论。此外,教育科技领域可借此开发网络用语翻译工具,促进代际间的有效沟通。
数据集最近研究
最新研究方向
在中文社交媒体内容分析领域,Baidu_Tieba_KangYaBeiGuo数据集为研究网络社区语言风格与用户生成内容提供了重要资源。该数据集聚焦于抗压背锅吧的文本数据,近期研究多围绕大语言模型的风格微调技术展开,特别是结合ChatGLM等架构探索网络用语的情感表达与毒性检测机制。随着游戏社区如《原神》《英雄联盟》等话题的热度攀升,该数据集被广泛应用于用户行为分析与内容安全治理,助力提升生成式AI在复杂网络环境中的适应性与可控性。
以上内容由遇见数据集搜集并总结生成


