HumDial-EIBench
收藏HumDial-EIBench 数据集概述
数据集简介
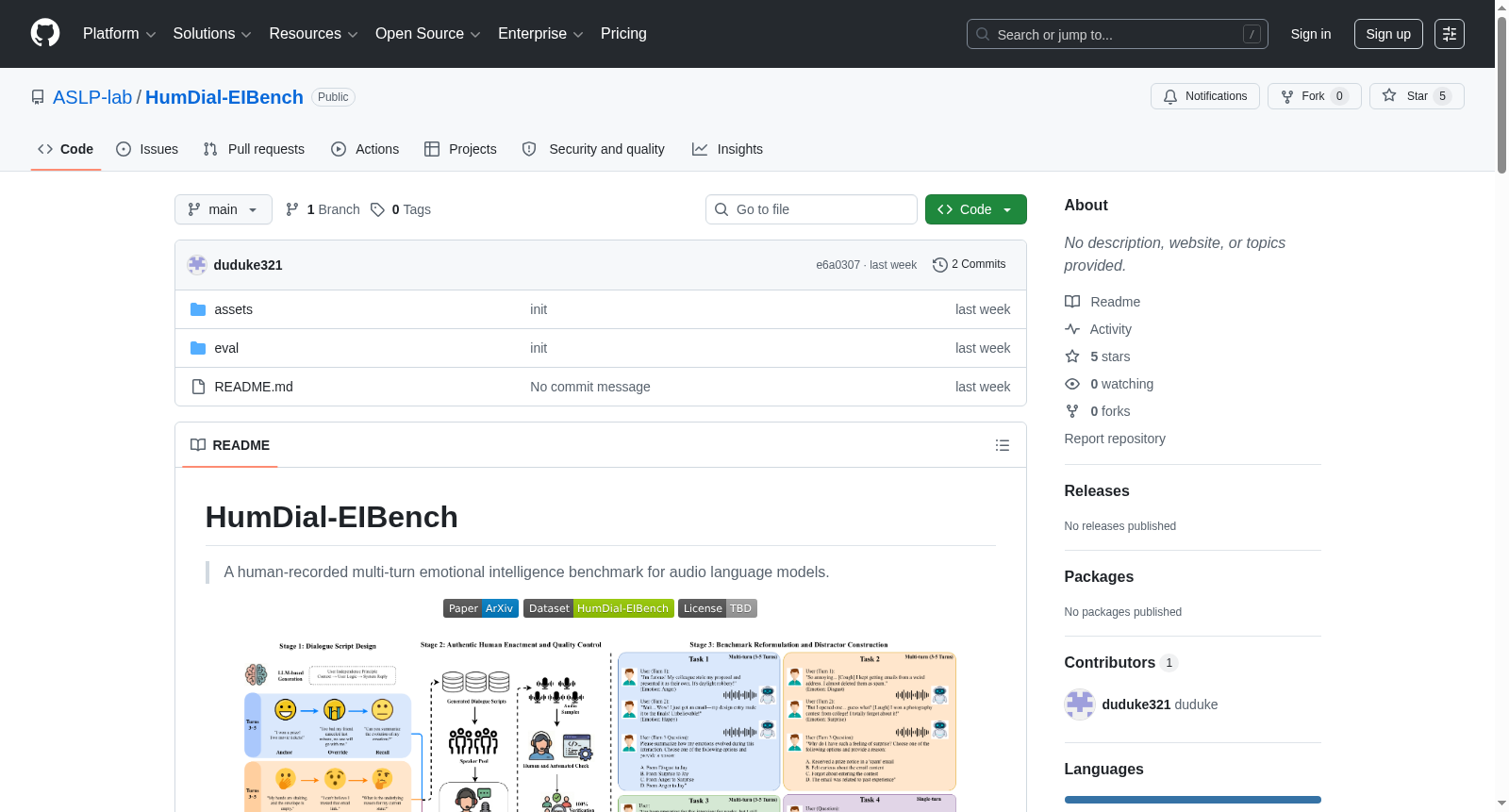
HumDial-EIBench 是一个用于评估音频语言模型情感理解能力的人类录制多轮对话情感智力基准。该基准旨在诊断模型是否真正理解语音中的情感,而非依赖文本转录的捷径。数据集基于 ICASSP 2026 HumDial 挑战赛的真实人类录制对话构建,包含中文和英文子集。
数据集特点
- 数据真实性:采用真实人类录制的多轮音频,而非合成语音。
- 评估目标性:通过客观的对抗性多项选择题任务进行以推理为重点的评估。
- 任务设计:包含专门的声学-语义冲突任务,并分别诊断文本共情与声学共情。
- 核心目标:在记忆、推理、生成和跨模态鲁棒性方面诊断音频语言模型的情感智力。
基准概览
- 总样本量:1,077
- 语言:中文 + 英文
任务构成
| 任务 | 类型 | 中文/英文样本量 | 对话轮数 | 主要评估指标 |
|---|---|---|---|---|
| 任务1:情感轨迹检测 | 多项选择题 | 150 / 150 | 3-5 | 准确率 |
| 任务2:隐式因果推理 | 多项选择题 | 134 / 149 | 3-5 | 准确率 |
| 任务3:共情反应生成 | 开放生成 | 144 / 150 | 3-5 | LLM + 人工评估 |
| 任务4:声学-语义冲突 | 多项选择题 | 100 / 100 | 1 | 准确率 |
| 总计 | 528 / 549 |
任务详情
任务1:情感轨迹检测
追踪跨对话轮次的情感变化(例如,E_t1 -> E_t2 -> E_t3),而非对孤立话语进行分类。
任务2:隐式因果推理
从分散的上下文线索中推断潜在的情感触发因素。多项选择题格式有助于减少评估者的主观性。
任务3:共情反应生成
从三个维度评估生成的反应:
- D1:文本共情与洞察力(LLM 评估,1-5分)
- D2:声音共情与一致性(人工评分,1-5分)
- D3:音频质量与自然度(人工评分,1-5分)
任务4:声学-语义冲突
测试当文本情感与声音情感相矛盾(例如,类似讽刺的情况)时的鲁棒性,以暴露文本主导偏见。
关键发现
- 大多数音频语言模型在多轮情感追踪和隐式因果推理方面仍存在困难。
- 文本共情与声学共情之间存在明显的解耦。
- 所有测试模型在声学-语义冲突下都表现出显著的文本主导偏见。
数据与代码访问
- 数据集即将发布。
评估使用
任务3(共情生成)评分
使用 eval/eval_task3.py 对模型输出的 D1/D2/D3 维度进行评分,并写入每个样本及汇总结果。
输入格式(jsonl)
jsonc { "dialogue_id": "sample_001", "turns": [ { "input_emotion": "sad", "input_text": "Ive been feeling really overwhelmed lately...", "response_text": "It sounds like youre carrying a lot right now.", "response_audio": "outputs/sample_001_turn1.wav" } ] }
运行命令
bash python eval/eval_task3.py --model Qwen3-Omni-30B-A3B-Instruct --input_file results/task3_outputs.jsonl --output_file results/task3_scores.jsonl
该脚本自动识别目标评估轮次(第二个非中性轮次)并根据先前轮次构建上下文。
环境说明:此脚本需要 GPU 运行时和
vLLM。运行前请在eval/eval_task3.py中设置本地评估检查点路径。
联系
如有问题或合作意向,请在本代码库中提交议题。