有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
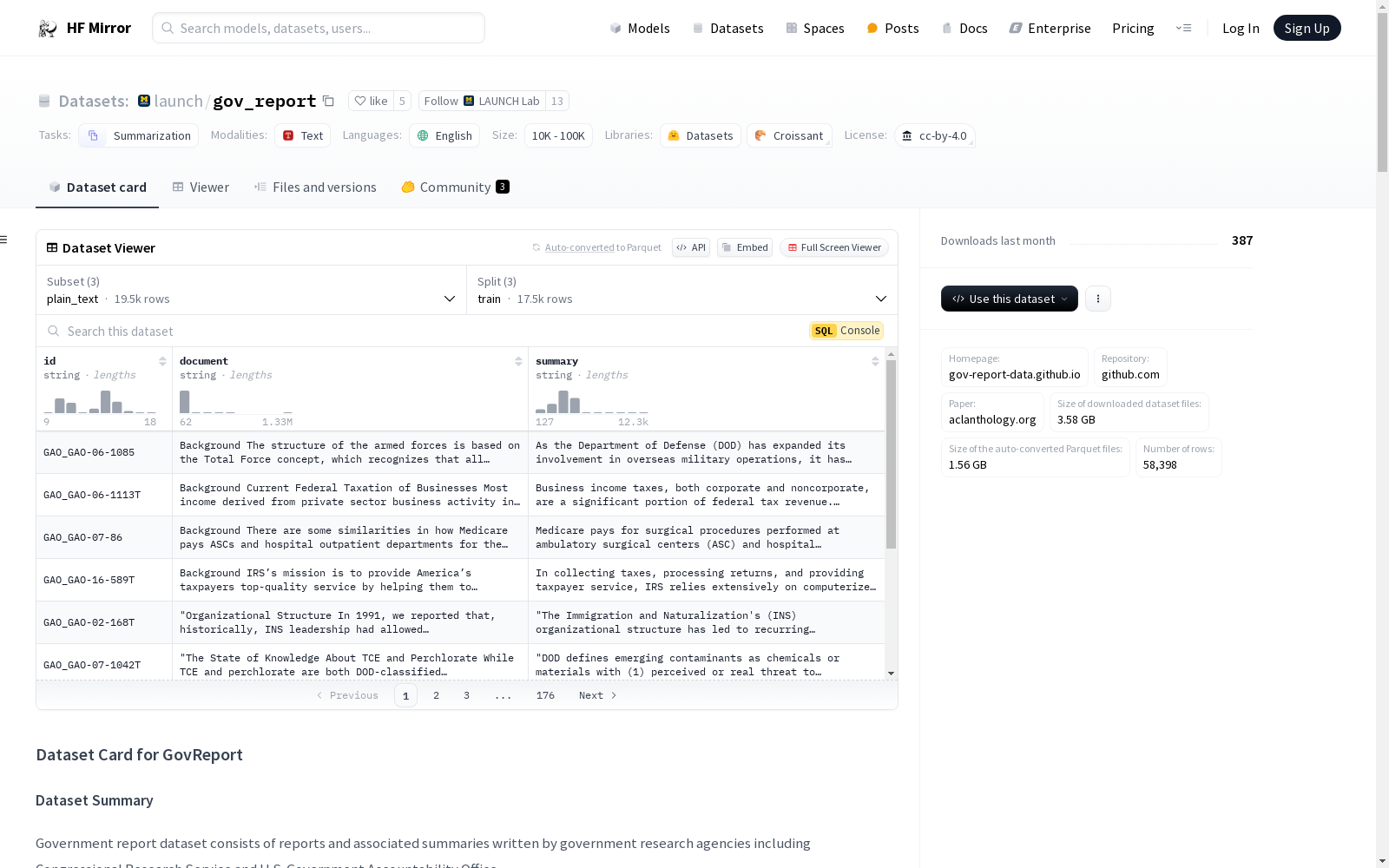
id, document, summary字段。id, document_sections(包含title, paragraphs, depth), summary_sections(包含title, paragraphs)字段。id: 字符串类型。document: 字符串类型。summary: 字符串类型。id: 字符串类型。document_sections: 字典类型,包含title, paragraphs, depth列表。summary_sections: 字典类型,包含title, paragraphs列表。@inproceedings{huang-etal-2021-efficient, title = "Efficient Attentions for Long Document Summarization", author = "Huang, Luyang and Cao, Shuyang and Parulian, Nikolaus and Ji, Heng and Wang, Lu", booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies", month = jun, year = "2021", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2021.naacl-main.112", doi = "10.18653/v1/2021.naacl-main.112", pages = "1419--1436", abstract = "The quadratic computational and memory complexities of large Transformers have limited their scalability for long document summarization. In this paper, we propose Hepos, a novel efficient encoder-decoder attention with head-wise positional strides to effectively pinpoint salient information from the source. We further conduct a systematic study of existing efficient self-attentions. Combined with Hepos, we are able to process ten times more tokens than existing models that use full attentions. For evaluation, we present a new dataset, GovReport, with significantly longer documents and summaries. Results show that our models produce significantly higher ROUGE scores than competitive comparisons, including new state-of-the-art results on PubMed. Human evaluation also shows that our models generate more informative summaries with fewer unfaithful errors.", }
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
Breast Ultrasound Images (BUSI)
小型(约500×500像素)超声图像,适用于良性和恶性病变的分类和分割任务。
github 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
China Groundgroundwater Monitoring Network
该数据集包含中国地下水监测网络的数据,涵盖了全国范围内的地下水位、水质和相关环境参数的监测信息。数据包括但不限于监测站点位置、监测时间、水位深度、水质指标(如pH值、溶解氧、总硬度等)以及环境因素(如气温、降水量等)。
www.ngac.org.cn 收录
FAOSTAT Agricultural Data
FAOSTAT Agricultural Data 是由联合国粮食及农业组织(FAO)提供的全球农业数据集。该数据集涵盖了农业生产、贸易、价格、土地利用、水资源、气候变化、人口统计等多个方面的详细信息。数据包括了全球各个国家和地区的农业统计数据,旨在为政策制定者、研究人员和公众提供全面的农业信息。
www.fao.org 收录