michaelwzhu/ChatMed_Consult_Dataset
收藏Hugging Face2023-05-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/michaelwzhu/ChatMed_Consult_Dataset
下载链接
链接失效反馈资源简介:
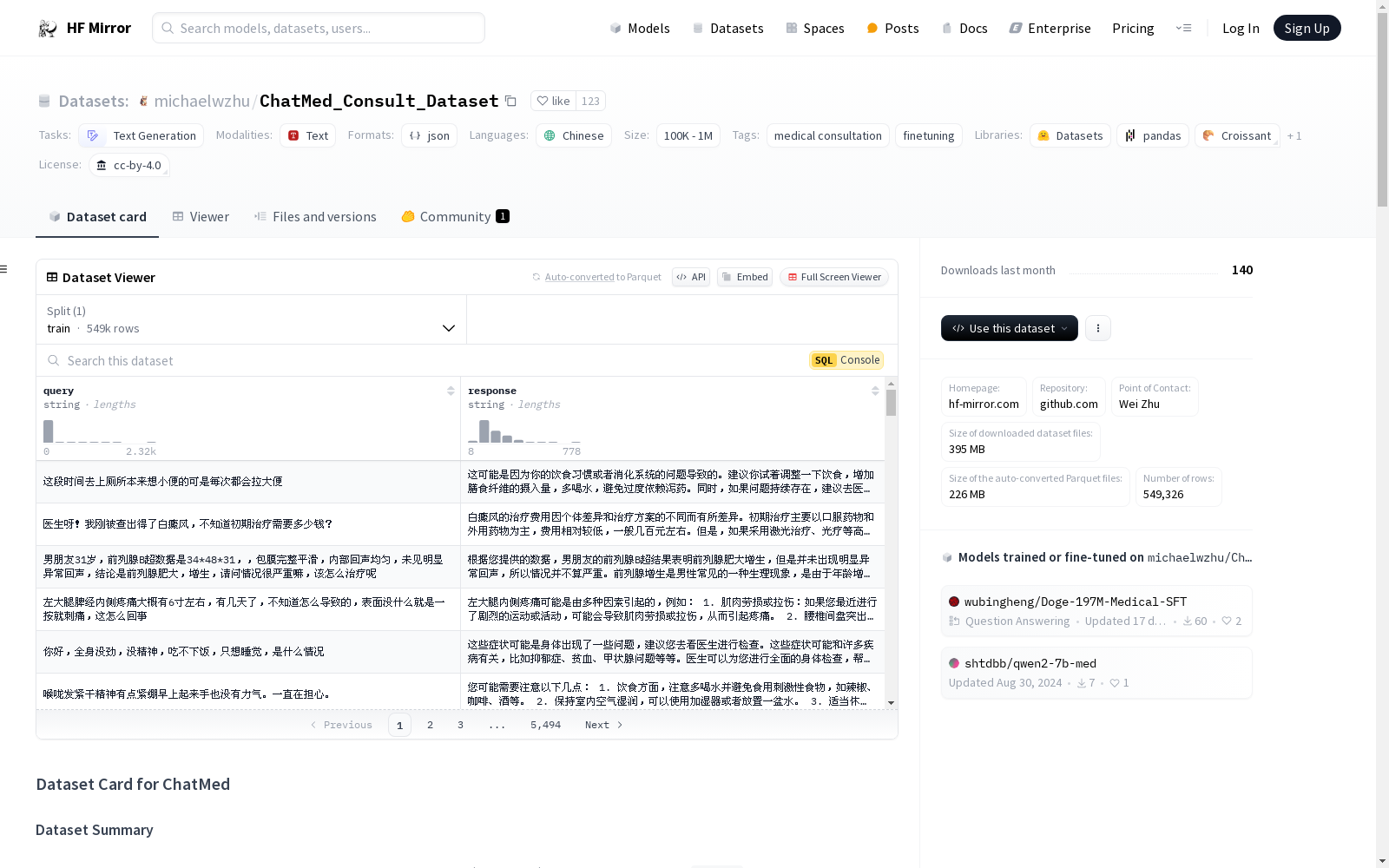
ChatMed-Dataset是一个包含110,113个中文医疗查询-响应对的数据集,这些对由OpenAI的GPT-3.5引擎生成。查询来自多个在线医疗咨询网站,反映了真实世界的医疗需求。该数据集旨在为中文大型语言模型注入医疗知识,并支持自动医疗咨询任务的微调。数据集以json-line格式提供,便于使用。
ChatMed-Dataset is a dataset comprising 110,113 Chinese medical query-response pairs, all generated using OpenAI's GPT-3.5 engine. The queries originate from multiple online medical consultation platforms, reflecting real-world medical needs. This dataset aims to infuse medical knowledge into Chinese large language models and support fine-tuning for automatic medical consultation tasks. It is provided in JSON Lines format for ease of use.
提供机构:
michaelwzhu
原始信息汇总
数据集概述
数据集描述
- 名称: ChatMed-Dataset
- 语言: 中文 (zh)
- 许可: Creative Commons NonCommercial (CC BY-NC 4.0)
- 标签: 医疗咨询, 微调
- 任务类别: 文本生成
数据集总结
ChatMed-Dataset 包含110,113对医疗查询-响应配对,这些配对使用OpenAI的GPT-3.5引擎生成。查询数据从多个在线医疗咨询网站爬取,反映了真实世界的医疗需求。响应由OpenAI引擎生成,旨在为中文大型语言模型注入医疗知识。
支持的任务和排行榜
该数据集设计用于微调预训练语言模型,以在自动医疗咨询中表现更佳。
数据集结构
数据实例
数据集采用json-line格式,便于使用。示例数据如下:
json { "query": "你好,视神经萎缩,黄斑变性。怎样缓解,及日常注意事项。谢谢。", "response": "视神经萎缩和黄斑变性是两种不同的疾病,需要分别进行治疗。
视神经萎缩是指视神经逐渐受损,导致视力逐渐减退,常见的治疗方法包括:
1.药物治疗:如促进视神经细胞再生的药物,改善视网膜供血的药物等。
2.手术治疗:如视神经萎缩的手术治疗可以通过神经移植、修复和再生等手术方式来缓解症状。
3.康复训练:通过视力训练等康复训练可以帮助患者恢复视力。
黄斑变性则是指黄斑区域受损,导致中央视力减退,常见的治疗方法包括:
1.药物治疗:如抗氧化剂、维生素等可以缓解症状。
2.手术治疗:如黄斑脱离手术等可以恢复视力。
3.日常注意事项:保持良好的生活习惯,如戒烟、控制血压、血糖等,避免暴晒和过度用眼,保持充足的睡眠和均衡的饮食等。
需要根据具体情况选择合适的治疗方案,建议您咨询专业医生进行诊断和治疗。" }
数据字段
query: 来自网络的真实医疗查询。response: 由OpenAIGPT-3.5引擎生成的响应。
数据分割
| train | |
|---|---|
| ChatMed-Dataset | 110,113 |
使用数据的考虑
数据集的社会影响
该数据集的发布旨在使学术界能够对大型语言模型如何响应真实医疗查询进行科学研究。
数据集的已知限制
数据集由语言模型(GPT-3.5)生成,可能包含错误或偏见。建议用户谨慎使用,并提出新的方法来过滤或改进这些不完美之处。
搜集汇总
数据集介绍
构建方式
ChatMed-Dataset数据集的构建,是基于互联网上110,113个医疗问诊问题,利用OpenAI的GPT-3.5引擎生成相应的回答。该数据集旨在为中文大型语言模型注入医学知识,通过对真实世界医疗需求的反映,以及对互联网医生与患者回答的筛选甄别,逐步构建出质量更优的数据集。
使用方法
用户可以通过访问HuggingFace的官方仓库来获取ChatMed-Dataset数据集。该数据集采用json-line格式存储,便于处理和使用。用户可以直接读取数据实例中的`query`和`response`字段,分别获取医疗咨询问题和对应的回答,进而用于模型训练、微调或评估等任务。
背景与挑战
背景概述
在人工智能技术不断发展的当下,医疗咨询领域的人工智能应用日益受到重视。ChatMed-Dataset,作为一款专业的中文医疗对话数据集,由Wei Zhu于2023年创建并维护。该数据集旨在通过注入医疗知识,提升中文大型语言模型在自动医疗咨询方面的表现。它汇集了110,113条真实的医疗咨询问答对,这些问答对通过OpenAI的GPT-3.5引擎生成,反映了现实世界中用户在医疗咨询方面的多样化需求。该数据集的出现,不仅丰富了中文垂直领域的AGI数据集资源,也为学术研究提供了重要的基础数据,对于推动医疗人工智能的发展具有重要意义。
当前挑战
尽管ChatMed-Dataset在构建时采用了先进的GPT-3.5引擎生成回答,但数据集构建过程中仍面临诸多挑战。首先,数据质量是关键,由于回答由模型生成,可能包含错误或偏见,因此需要进一步的筛选和优化。其次,数据集的多样性和代表性也是重要考量,需确保数据能够覆盖广泛的医疗场景和用户需求。此外,数据集在个人隐私保护、数据标注的准确性以及避免社会偏见等方面也需进行深入研究和处理。
常用场景
经典使用场景
在当前人工智能技术飞速发展的时代背景下,ChatMed-Dataset应运而生,该数据集最经典的使用场景是作为预训练语言模型的微调数据,旨在提升模型在自动医疗咨询领域的表现,以满足实际医疗咨询中患者与医生交流的需求。
解决学术问题
ChatMed-Dataset的构建解决了中文垂直领域AGI数据集匮乏的问题,为学术研究提供了宝贵的资源,有助于研究人员深入探索大型语言模型在医疗咨询场景中的应用,进一步推动医学自然语言处理技术的发展。
实际应用
在实践应用方面,该数据集可以被用来训练医疗聊天机器人,为患者提供实时、准确的医疗咨询,减轻医生的工作负担,提高医疗服务效率,对医疗保健行业产生积极影响。
数据集最近研究
最新研究方向
在医疗咨询领域,ChatMed-Dataset作为一款由GPT-3.5生成的中文医疗问答数据集,正引领研究走向深入探索人工智能在医疗领域的应用潜能。该数据集不仅为模型提供了丰富的垂直领域知识,更通过模拟真实世界的医疗咨询场景,推动了自动医疗咨询系统的发展。目前,研究者正致力于利用此数据集优化预训练语言模型,以实现更精准、高效的医疗问答响应,这对于提升医疗服务质量,满足患者个性化需求具有显著影响和意义。
以上内容由遇见数据集搜集并总结生成


