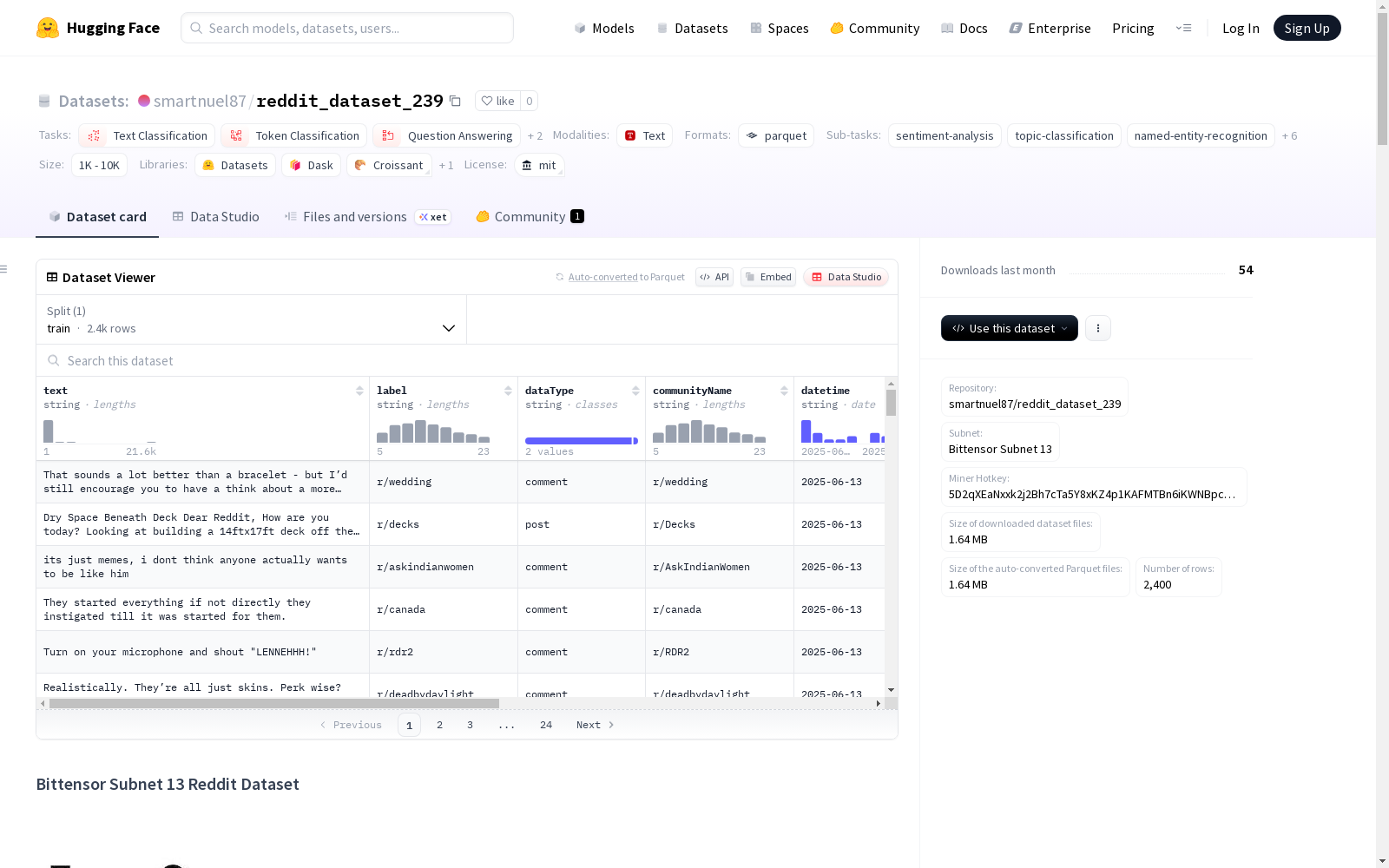
reddit_dataset_239
收藏Hugging Face2025-07-15 更新2025-07-16 收录
下载链接:
https://huggingface.co/datasets/smartnuel87/reddit_dataset_239
下载链接
链接失效反馈官方服务:
资源简介:
Bittensor Subnet 13 Reddit数据集是Bittensor Subnet 13去中心化网络中的一部分,包含预处理后的Reddit数据。该数据由网络矿工持续更新,为各种分析和机器学习任务提供实时Reddit内容流。数据集支持多种任务,如情感分析、主题建模、社区分析和内容分类。数据主要使用英语,但由于去中心化的创建方式,也可能是多语言的。每个数据实例代表一个Reddit帖子或评论,包括文本内容、标签、数据类型、社区名称、日期时间、编码后的用户名和URL。数据集不断更新,用户应根据需要和时间戳创建自己的数据切分。数据来源于Reddit的公共帖子和评论,遵守平台的服务条款和API使用指南,并对用户名和URL进行编码以保护隐私。使用数据时需要注意潜在的偏见和局限性,例如数据质量可能因媒体来源而异,数据可能包含社交媒体平台典型的噪声、垃圾邮件或不相关内容。
创建时间:
2025-07-15
原始信息汇总
Bittensor Subnet 13 Reddit数据集概述
数据集基本信息
- 存储库名称: smartnuel87/reddit_dataset_239
- 所属子网: Bittensor Subnet 13
- 矿工热键: 5D2qXEaNxxk2j2Bh7cTa5Y8xKZ4p1KAFMTBn6iKWNBpcJyj3
- 许可证: MIT
- 多语言支持: 主要英语,可能包含多语言内容
- 数据来源: Reddit公开帖子和评论
数据集描述
- 类型: 去中心化网络预处理Reddit数据
- 更新方式: 由网络矿工持续更新,提供实时数据流
- 官方存储库: https://github.com/macrocosm-os/data-universe
支持任务
- 文本分类
- 标记分类
- 问答系统
- 文本摘要
- 文本生成
- 情感分析
- 主题分类
- 命名实体识别
- 语言建模
- 文本评分
- 多类分类
- 多标签分类
- 抽取式问答
- 新闻文章摘要
数据结构
数据字段
text: Reddit帖子或评论的主要内容label: 内容的情感或主题类别dataType: 标识条目是帖子还是评论communityName: 发布内容的子版块名称datetime: 内容发布或评论的日期username_encoded: 编码后的用户名(保护隐私)url_encoded: 编码后的URL(保护隐私)
数据拆分
- 持续更新,无固定拆分
- 建议用户根据时间戳自建拆分
数据集统计
- 总实例数: 700
- 日期范围: 2025-06-13T00:00:00Z至2025-06-14T00:00:00Z
- 最后更新时间: 2025-07-16T03:14:31Z
- 数据分布:
- 帖子: 5.29%
- 评论: 94.71%
热门子版块(Top 10)
| 排名 | 子版块 | 总数 | 百分比 |
|---|---|---|---|
| 1 | r/AskReddit | 12 | 1.71% |
| 2 | r/AITAH | 8 | 1.14% |
| 3 | r/teenagers | 7 | 1.00% |
| 4 | r/mildlyinfuriating | 7 | 1.00% |
| 5 | r/GlobalNews | 7 | 1.00% |
| 6 | r/wallstreetbets | 6 | 0.86% |
| 7 | r/NBATalk | 6 | 0.86% |
| 8 | r/AmIOverreacting | 5 | 0.71% |
| 9 | r/justiceforKarenRead | 5 | 0.71% |
| 10 | r/NepalSocial | 5 | 0.71% |
使用注意事项
- 可能包含Reddit数据固有的偏见
- 数据质量可能因来源而异
- 可能包含社交媒体典型的噪声或垃圾内容
- 仅限于公共子版块,不含私人社区
- 使用时需遵守Reddit服务条款
引用信息
bibtex @misc{smartnuel872025datauniversereddit_dataset_239, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={smartnuel87}, year={2025}, url={https://huggingface.co/datasets/smartnuel87/reddit_dataset_239}, }
搜集汇总
数据集介绍
构建方式
在社交媒体数据分析领域,该数据集依托Bittensor子网13的去中心化架构,通过分布式矿工网络实时采集并预处理Reddit公开帖文与评论。数据构建严格遵循平台服务条款与API规范,采用编码技术匿名化用户名及URL以保障用户隐私,形成持续更新的动态语料库。
使用方法
研究者可基于时间戳动态划分训练与测试集,通过解析text字段进行语义建模,结合communityName实现社区差异分析。需注意数据固有的时空偏差与社交平台噪声,建议通过分层采样平衡子论坛表征,并遵循MIT许可与Reddit使用条款开展学术研究。
背景与挑战
背景概述
作为Bittensor去中心化网络Subnet 13的重要组成部分,reddit_dataset_239由智能体smartnuel87于2025年构建,依托Macrocosmos数据生态系统。该数据集通过分布式矿工实时采集Reddit平台公开内容,涵盖文本分类、情感分析、命名实体识别等多模态自然语言处理任务,为社交媒体动态研究提供了持续更新的语料库。其创新性地采用用户信息编码机制保障隐私合规,对计算社会科学领域具有重要实证研究价值。
当前挑战
在领域问题层面,该数据集需应对社交媒体文本固有的语义噪声与话题漂移现象,同时克服社区文化差异导致的标注一致性难题。构建过程中面临实时数据流处理的时序偏差挑战,需平衡数据新鲜度与质量管控;分布式采集架构导致的内容重复与稀疏分布问题亦需特殊处理,且需在遵守平台条款前提下实现多语言内容的标准化整合。
常用场景
经典使用场景
在社交媒体分析领域,reddit_dataset_239作为实时更新的Reddit内容集合,为研究者提供了丰富的文本语料。该数据集典型应用于情感分析任务,通过分析用户评论的情感极性揭示社区情绪波动;在主题建模方面,能够自动识别热门讨论话题及其演化规律;同时支持社区动态分析,帮助理解不同子论坛的文化特征和用户互动模式。
解决学术问题
该数据集有效解决了社交媒体研究中数据时效性不足的瓶颈问题,为自然语言处理领域提供了高质量的标注语料。其在细粒度情感分析、跨社区文化比较、实时话题追踪等研究方向具有重要价值,特别是通过去中心化采集机制保证了数据的多样性和代表性,为构建更稳健的NLP模型提供了坚实基础。
实际应用
实际应用中,该数据集可赋能商业智能系统进行品牌声誉监控,通过实时分析Reddit平台用户反馈及时捕捉市场情绪变化。新闻机构可借助其进行热点事件追踪和舆论趋势预测,而内容推荐系统则能基于社区特征实现更精准的个性化推荐。政府部门亦可利用其进行公共舆情监测和政策效果评估。
数据集最近研究
最新研究方向
在社交媒体分析领域,Reddit_dataset_239凭借其去中心化实时更新的特性,正成为动态舆情监测和社区演化研究的重要数据源。前沿研究聚焦于结合大语言模型进行跨社区话题传播分析,探索突发事件的舆论形成机制。该数据集支持的多任务框架(如情感分析、主题分类)为社交媒体内容理解提供了新范式,尤其在去中心化网络与AI结合的创新应用中展现出独特价值,推动着社交计算与分布式机器学习交叉领域的发展。
以上内容由遇见数据集搜集并总结生成


