Soyuz-sft
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/AlexWortega/Soyuz-sft
下载链接
链接失效反馈官方服务:
资源简介:
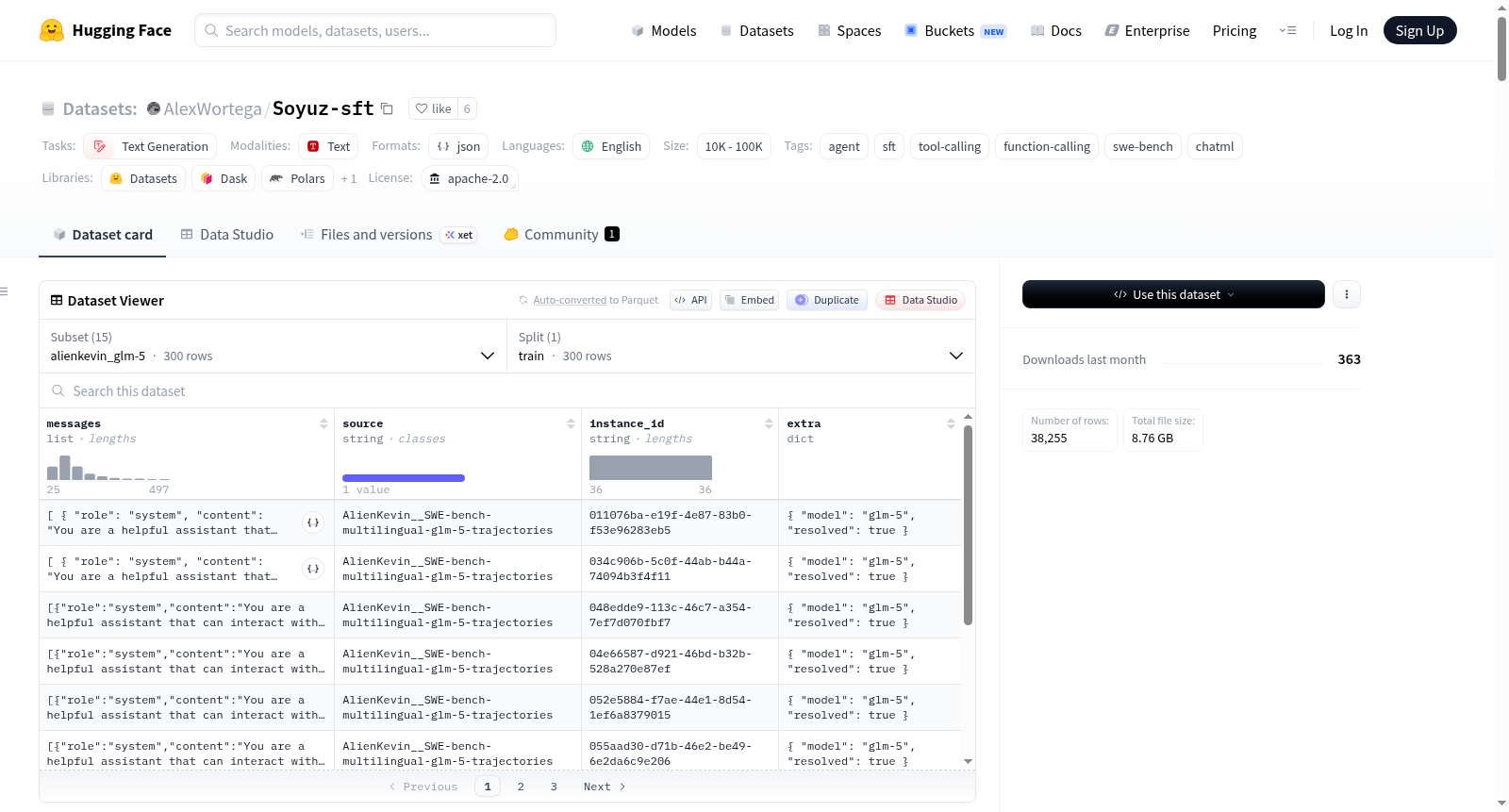
Soyuz-sft是一个统一的ChatML格式监督微调(SFT)数据集,汇集了来自多种前沿模型(如Claude Sonnet 4.5、GPT-5 codex、Kimi K2/K2.5等)的智能体轨迹数据,专门用于将大模型能力蒸馏至较小模型。数据集包含38,060条轨迹,每条轨迹采用标准化的ChatML格式,包含系统消息、用户输入、助手响应(可能含<think>推理步骤和工具调用)以及工具返回结果。数据集按来源分为多个配置,每个配置标注了原始数据集ID和模型来源。数据经过质量筛选,分为clean(质量合格)、unresolved(任务失败但轨迹结构完整)、bad(结构问题)和dpo(对比学习对)四个子集。特别提供了模型能力层级划分(S/A/B/C级),并推荐了针对Qwen3-4B模型的训练方案和过滤策略。数据集适用于文本生成、工具调用、函数调用等任务,尤其适合智能体模型的监督微调和对比学习。
创建时间:
2026-05-06
搜集汇总
数据集介绍
构建方式
Soyuz-sft 数据集由来自多个前沿模型(如 Claude Sonnet 4.5、GPT-5 codex、Kimi K2/K2.5、Qwen3-Coder-480B、GLM-5/5.1、Minimax M2.5 及 gpt-5.2)的智能体轨迹汇集而成,覆盖 SWE-bench、SWE-Smith、GAIA 等基准测试。原始数据来自 11 个源头数据集,经过统一的 ChatML 格式转换与标准化处理,每条轨迹包含系统提示、用户指令、带推理与工具调用的助手回复以及工具执行结果等完整回合。数据经过清洗、去重、过滤低质量与未完成任务,并整合为清洁、未解决与缺陷三个子集,同时构建了约 340 对适用于偏好优化的 DPO 样本对。
特点
该数据集规模约 3.8 万条轨迹,每条包含丰富的工具调用与多轮交互细节,平均每轨迹含 20–150 条消息与 12–74 次工具调用。数据集创新性地引入教师分层体系,将模型按推理能力分为 S、A、B、C 四个等级,便于下游训练时按需筛选。清洁子集经过终点剪裁处理,确保每条轨迹以干净的助手文本回复结束,避免了模型学到持续活跃或无法停止的不良行为。此外,数据保留源头归属与任务实例标识,支持跨模型对比与多源知识蒸馏。
使用方法
用户可通过 HuggingFace Datasets 库按配置加载数据,推荐使用 'clean' 配置进行监督微调。训练时可借助教师层级字段 'teacher_tier' 灵活筛选高质量子集,例如仅保留 S 与 A 层级可获得约 1.8 万条轨迹。DPO 子集提供了相同或相似任务的成对对比样本,便于开展偏好学习。对于 Qwen3-4B 等小型模型,建议使用 5 轮训练、余弦学习率衰减与较小批次大小,并在欠拟合时逐步扩展数据范围以避免过拟合。
背景与挑战
背景概述
在人工智能体(Agent)领域,如何将前沿大模型展现出的复杂推理与工具调用能力高效迁移至轻量化部署模型,已成为当前研究的核心瓶颈。Soyuz-sft数据集由研究者AlexWortega于2026年构建,旨在汇聚来自Claude Sonnet 4.5、GPT-5 codex、Kimi K2等十余个顶尖模型的Agent运行轨迹,形成高质量监督微调(SFT)语料库。该数据集以ChatML格式统一整理了超过3.8万条完整轨迹,覆盖SWE-bench、GAIA等基准测试,并通过教师层级(S/A/B/C)标注实现了质量可控的知识蒸馏。其发布为小型Agent模型的训练提供了标准化资源,在工具调用、代码生成等复杂任务的知识迁移研究中产生了重要影响。
当前挑战
Soyuz-sft数据集面对的核心挑战在于多源异构Agent轨迹的整合与质量保障。首先,不同模型采用的工具调用格式各异,包括XML、Markdown及结构化字段,统一规范化过程中需保持语义完整性。其次,轨迹质量参差不齐——原始数据中约35%存在循环死锁、运行时错误或任务未解决等结构性问题,需通过复杂的过滤流水线(如滑动窗口循环检测、错误尾迹识别)进行清洗。此外,约50%的轨迹存在不恰当的终止模式,模型若接触此类数据可能学习到无休止调用工具的坏习惯,因此设计了终止修剪策略。最终,仅约53%的原始数据被判定为可用,构建出兼具多样性与纯净度的SFT子集。
常用场景
经典使用场景
在大型语言模型的研发图谱中,Soyuz-sft数据集被精妙地设计为多源智能体轨迹的融合枢纽,其经典用途在于通过统一ChatML格式聚合前沿模型(如Claude Sonnet 4.5、GPT-5 Codex等)在软件工程基准测试中的交互日志,以此蒸馏出更为轻量却具备同等工具调用能力的智能体模型。这一过程不仅是知识迁移的优雅实践,更为学术界探索模型规模与推理效能间的帕累托最优边界提供了高保真的训练养料。
衍生相关工作
这一数据集的诞生催生了多条富有张力的衍生研究脉络,包括基于多教师蒸馏的模型压缩技术、跨模型偏好对齐的对比学习框架,以及利用未解决轨迹构建负样本的鲁棒性训练策略。尤为值得关注的是,研究者从中提炼出关于工具调用终止条件的形式化分析,提出了面向长尾任务的动态截断机制。这些工作不仅在SWE-bench等权威基准上刷新了记录,更推动了将智能体行为模式建模为马尔可夫决策过程的规范化探索。
数据集最近研究
最新研究方向
前沿模型智能体轨迹的蒸馏与统一监督微调。Soyuz-sft数据集汇聚了Claude Sonnet 4.5、GPT-5 codex、Kimi K2等前沿模型的智能体轨迹,并依据模型性能划分为S/A/B/C四个层级,为小模型的知识蒸馏提供了高质量、多样化的训练素材。该数据集的构建顺应了当前将强大模型能力迁移至轻量级部署的热点趋势,通过统一格式和精心设计的过滤流程(clean/bad/dpo子集),显著提升了SFT与偏好对齐训练的有效性。其研究的核心意义在于,为智能体模型的规模化训练与高效蒸馏搭建了标准化桥梁,有望加速新一代自主工具调用与软件工程智能体在资源受限场景下的落地应用,对推动AI代理技术的实用化与民主化具有重要影响。
以上内容由遇见数据集搜集并总结生成


