sammshen/lmcache-agentic-traces
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/sammshen/lmcache-agentic-traces
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- text-generation
tags:
- kv-cache
- llm-serving
- agentic
- multi-turn
- traces
- benchmark
pretty_name: LMCache Agentic Dataset Collection
size_categories:
- 10K<n<100K
---
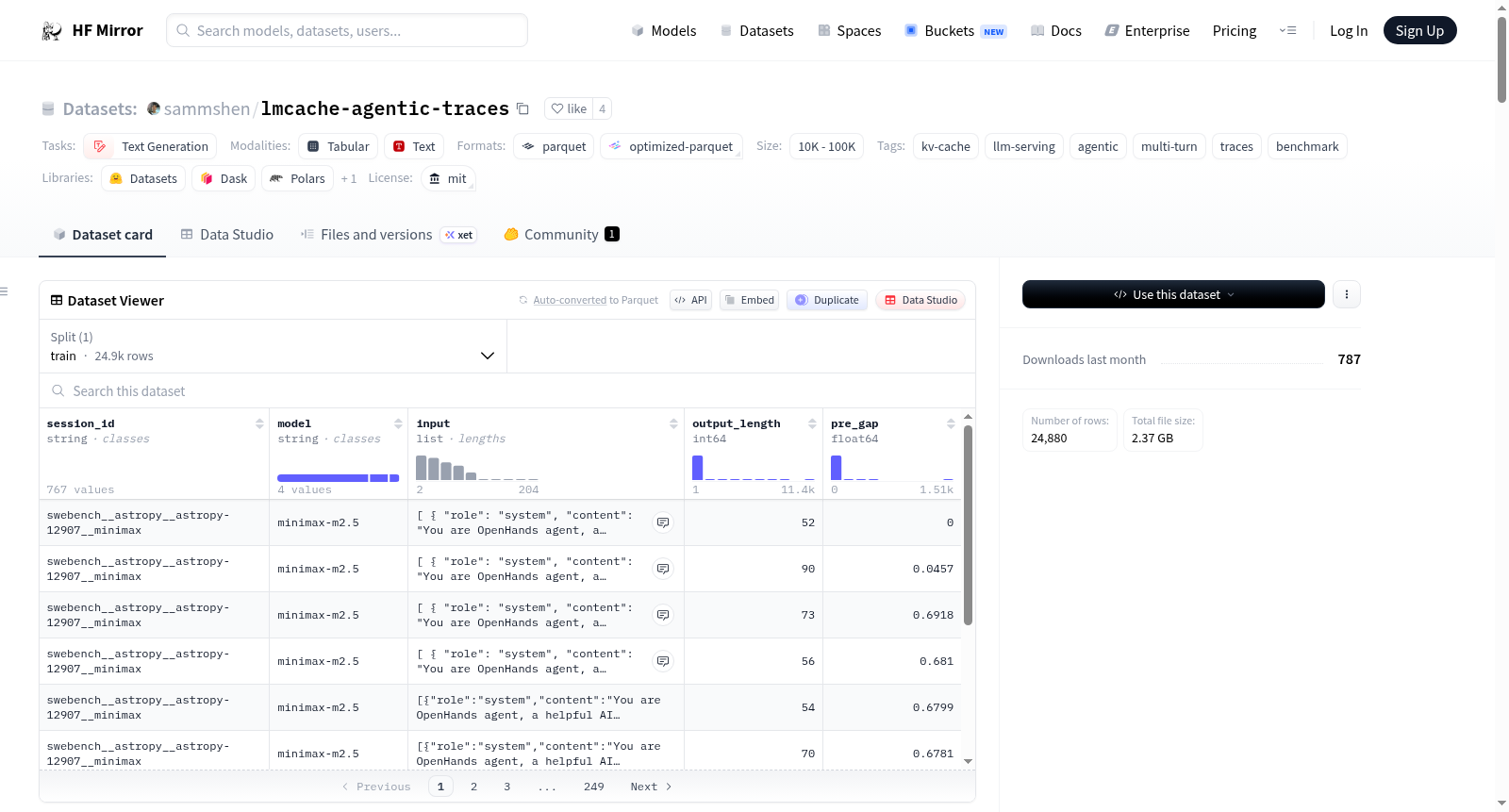
# LMCache Agentic Dataset Collection
A curated dataset collection of **787 multi-turn agentic LLM sessions** (24,881 total LLM iterations) designed for benchmarking stateful LLM serving systems. Every session exhibits at least 5 turns with prefix growth and builds to at least 10K tokens of context — making it ideal for evaluating tiered KV Cache solutions like [LMCache](https://github.com/LMCache/LMCache).
## Motivation
Modern LLM agents (coding assistants, research agents, tool-calling systems) make dozens of sequential API calls per task. Each call appends tool results and assistant responses to a growing conversation history, creating a natural prefix-sharing pattern: iteration N's input is iteration N-1's input plus new messages at the end.
This means **>90% of tokens in a typical request have already been processed in the previous request**. An efficient KV cache can skip recomputation of the shared prefix, dramatically increasing system throughput (tok/s) and reducing GPU cost.
The challenge with inference benchmarking of agentic workloads is that the trace format should permit directly running against an inference API such as the OpenAI or Anthropic API instead of requiring an agent harness to be nested in between. Thus, the user can directly benchmark their inference deployment with a reproducable agentic workload without actually deploying an agent.
This dataset provides these real agent trajectories from the tasks provided in the following open source agentic datasets:
- **[SWE-bench Verified](https://swebench.com/)**: Real GitHub issues from popular Python repos. The agent (OpenHands CodeAct) reads code, writes patches, runs tests, and iterates on failures. Sessions range from 5-50 turns of edit-test-debug cycles.
- **[GAIA](https://huggingface.co/datasets/gaia-benchmark/GAIA)**: Level 2-3 multi-step reasoning tasks requiring web search, file analysis, and chain-of-thought reasoning. Evaluated with Inspect AI.
- **[WildClaw](https://github.com/WildClaw)**: Mixed agent tasks spanning creative synthesis, search, and code generation.
## Dataset Overview
| Source | Sessions | Turns (med/mean/max) | Models | Workload |
|--------|----------|----------------------|--------|----------|
| **SWE-bench** | 669 | 38 / 35 / 50 | MiniMax-M2.5, Claude Sonnet 4.6, DeepSeek V3.1 | Code debugging: read code, write patches, run tests, debug failures |
| **GAIA** | 85 | 14 / 13 / 26 | Claude Sonnet 4.6 | Multi-step research and reasoning with web search |
| **WildClaw** | 10 | 22 / 24 / 41 | Claude Opus 4.6 | Mixed agent tasks (creative, search, code) |
| **Total** | **787** | **35 / 33 / 50** | **4 models** | **3 workload types** |
## Data Format
Each row represents one LLM iteration within a session. All rows for a session share the same `session_id`. A "session" corresponds to a single task — one initial query that the agent works on across multiple turns. All sessions are single-task: the agent receives one problem and iterates on it (reading code, running commands, calling tools) until done or the turn budget is exhausted.
Messages use four roles: `system` (always the first message), `user` (the initial query plus framework-injected feedback like error messages and runtime info), `assistant` (LLM responses and tool-call requests), and `tool` (tool execution results). The `tool` role appears in GAIA, WildClaw, and SWE-bench Sonnet sessions which use OpenAI-style function calling. SWE-bench MiniMax/DeepSeek sessions embed tool outputs directly in `user` messages instead.
```jsonl
{"session_id": "swebench__django__django-16527__claude", "model": "claude-sonnet-4-6", "input": [{"role": "system", "content": "..."}, {"role": "user", "content": "Fix the bug..."}], "pre_gap": 0.0, "output_length": 342}
{"session_id": "swebench__django__django-16527__claude", "model": "claude-sonnet-4-6", "input": [{"role": "system", "content": "..."}, {"role": "user", "content": "Fix the bug..."}, {"role": "assistant", "content": "Let me read...", "tool_calls": [...]}, {"role": "tool", "content": "class QuerySet:..."}], "pre_gap": 1.2345, "output_length": 567}
```
### Fields
| Field | Type | Description |
|-------|------|-------------|
| `session_id` | string | Unique session identifier (e.g. `swebench__django__django-16527__claude`, `gaia__L2_abc123__claude`, `wildclaw__01_Productivity_Flow_task_1_arxiv_digest__claude`). Describes source, task, and model. Same for all rows in a session. |
| `model` | string | Model used (e.g. `claude-sonnet-4-6`, `minimax-m2.5`, `deepseek-v3.1`). |
| `input` | array | Full cumulative OpenAI-format `messages` array. The assistant's output from iteration N-1 is embedded in iteration N's input. `input[N]` is a strict prefix-superset of `input[N-1]`. |
| `pre_gap` | float | Seconds between the previous iteration's response completing (last streamed token) and this iteration's request being sent. This is the real tool-execution / user-thinking time. Always `0.0` for the first iteration of a session. Median: 0.71s, mean: 2.08s, p95: 3.73s. |
| `output_length` | int | Completion tokens generated for this iteration. |
### Timing Model
The `pre_gap` field captures the **client-side delay** between consecutive LLM calls within a session. This is the time spent executing tools (running bash commands, reading files, making web requests) or processing the LLM's response before sending the next request. It does **not** include LLM inference time — that depends on the serving system being benchmarked.
```
|-- LLM inference (N-1) --|-- pre_gap[N] (tool exec / think time) --|-- LLM inference (N) --|
```
This enables accurate trace replay: a benchmarking tool can fire request N exactly `pre_gap[N]` seconds after receiving the last token of response N-1, faithfully reproducing the original workload timing without baking in the original server's inference latency.
## Dataset Statistics
### Turns per Session
The dataset spans a wide range of conversation lengths. SWE-bench sessions are the longest (median 38 turns, many hitting the 50-turn cap). GAIA sessions vary from 5 to 26 turns depending on task difficulty. WildClaw sessions range from 6 to 41 turns.


### Context Growth
The key property for KV cache benchmarking: how context size grows as a session progresses. All sessions are filtered to reach at least 10K tokens of context. On average, context starts at ~14K tokens and grows linearly to ~35K tokens by turn 50.

Per-source context growth shows distinct patterns:
- **SWE-bench**: steady linear growth from ~14K to ~37K tokens (large system prompts + code context)
- **GAIA**: rapid growth to ~20K tokens then plateau (web search results accumulate then stabilize)
- **WildClaw**: steep growth from ~30K to ~130K tokens (complex multi-tool agent sessions)

### Token Distributions
Input tokens (prompt size) follow a right-skewed distribution with median 21K tokens, dominated by SWE-bench's large contexts. Output tokens have a median of 104 tokens — these are the short, frequent tool-call requests that dominate agentic iteration. However, the dataset also captures substantial long-form generation: 11.5% of outputs exceed 500 tokens and the tail extends to 11K+ tokens. These longer outputs — code patches, detailed analyses, multi-step plans — are the responses typically visible to the end user in an agent interaction, and they represent the bulk of the generation workload despite being less frequent.

## Usage with AIPerf
This dataset can be converted to [AIPerf](https://github.com/ai-dynamo/aiperf)'s `mooncake_trace` format for benchmarking. See [sammshen/agentic-dataset](https://github.com/sammshen/agentic-dataset) for the converter script and full documentation.
```bash
# Convert to mooncake_trace format (pre_gap → delay in ms)
python convert_lmcache_to_mooncake.py --output trace.jsonl
# Recommended: concurrent sessions, sequential intra-session turns
aiperf profile \
--input-file trace.jsonl \
--custom-dataset-type mooncake_trace \
--concurrency 20 \
--request-timeout-seconds 3600 \
--extra-inputs ignore_eos:true \
--use-server-token-count
```
AIPerf guarantees that requests within the same `session_id` run strictly sequentially in all scheduling modes. `--concurrency N` keeps N sessions active with no inter-turn delay (max cache pressure). For realistic timing with tool-execution gaps, use `--fixed-schedule` which honors the `delay` field from `pre_gap`.
## Intended Use
This dataset is designed for:
- **KV cache system benchmarking**: Evaluate prefix-aware caching strategies (e.g., LMCache, Mooncake, vLLM prefix caching, SGLang RadixAttention) using realistic workloads with verified prefix structure.
- **LLM serving research**: Study context growth patterns, request timing distributions, and output length distributions in real agentic workloads.
- **Cache policy design**: Use the per-source breakdown to understand how different workload types create different caching opportunities (e.g., SWE-bench's large steadily growing contexts vs GAIA's rapid growth and plateau).
## Citation
If you use this dataset, please cite:
```bibtex
@misc{lmcache-agentic-dataset-2026,
title={LMCache Agentic Dataset: Multi-Turn LLM Agent Sessions for KV Cache Benchmarking},
author={LMCache},
year={2026},
url={https://huggingface.co/datasets/sammshen/lmcache-agentic-traces}
}
```
## License
CC-BY-4.0
提供机构:
sammshen
搜集汇总
数据集介绍
构建方式
在智能体系统日益普及的背景下,该数据集通过精心整合多个开源智能体基准任务的实际运行轨迹构建而成。其核心方法是从SWE-bench Verified、GAIA和WildClaw三个代表性数据集中,提取真实的、多轮次的智能体会话记录。构建过程严格筛选了会话长度,确保每个会话至少包含5轮交互,且上下文长度累积至万词元规模,以模拟智能体任务中典型的上下文前缀共享模式。数据以迭代为单位组织,完整保留了每次模型调用的输入消息序列、输出长度及请求间隔时间,形成了可直接用于推理API基准测试的标准化轨迹格式。
特点
该数据集最显著的特征在于其真实性与多样性,它汇集了787个涵盖代码调试、多步推理与混合创意任务的多轮智能体会话,总计24,881次模型迭代。数据呈现出鲜明的上下文增长模式,会话内相邻请求的输入存在超过90%的令牌重叠,这为评估KV缓存系统的前缀共享优化效能提供了理想场景。此外,数据集精确记录了每次迭代前的工具执行或思考时间(pre_gap),使得工作负载的时间特性得以在基准测试中被忠实复现。不同来源的数据在会话长度、上下文增长曲线和令牌分布上各具特点,共同构成了对现代智能体工作负载的全面刻画。
使用方法
该数据集主要用于评估支持状态保持的大语言模型服务系统,特别是分级KV缓存解决方案。使用者可通过提供的转换脚本,将数据转化为AIPerf基准测试框架所需的mooncake_trace格式。在测试中,可以配置不同的并发度与调度策略,例如,高并发设置可模拟最大缓存压力场景,而固定调度模式则会严格遵守数据中记录的请求间隔时间,以还原真实的工作负载时序。通过分析不同智能体任务类型下的上下文增长模式与令牌分布,研究者能够深入理解各类工作负载对缓存策略提出的差异化要求,进而指导缓存系统的设计与优化。
背景与挑战
背景概述
在大型语言模型(LLM)服务系统领域,高效管理键值(KV)缓存已成为提升推理吞吐量与降低计算成本的核心技术挑战。LMCache Agentic Traces数据集由LMCache团队于2026年创建,旨在为状态化LLM服务系统提供基准测试支持。该数据集精心收集了787个多轮次智能体会话,涵盖总计24,881次LLM迭代,数据源自SWE-bench Verified、GAIA和WildClaw等开源智能体任务库。其核心研究问题聚焦于如何利用真实智能体工作负载中普遍存在的前缀共享模式,即超过90%的令牌在连续请求中重复出现,从而为层级化KV缓存解决方案的评估提供标准化、可复现的轨迹数据,推动高效推理系统的设计与优化。
当前挑战
该数据集致力于解决智能体工作负载下LLM服务系统的推理基准测试挑战,其核心在于如何精准模拟真实场景中多轮次对话的上下文增长与请求时序,避免因嵌套智能体框架而引入额外偏差。构建过程中的主要挑战包括:第一,需从异构的原始智能体任务中提取并统一格式,确保每个会话的输入严格遵循前缀超集关系,以准确反映KV缓存的应用潜力;第二,必须精确捕获并记录请求间的客户端延迟(即工具执行与用户思考时间),剥离原始服务器推理延迟,从而实现工作负载时序的高保真重放;第三,需筛选并整合不同来源的会话,使其上下文长度均能增长至至少一万令牌,以覆盖从代码调试到复杂推理的多样化、长上下文评估场景。
常用场景
经典使用场景
在大型语言模型服务系统的研究领域,lmcache-agentic-traces数据集为评估状态感知的KV缓存机制提供了基准场景。该数据集汇集了787个多轮次智能体会话,涵盖代码调试、多步推理与创意合成等多种任务,每个会话均展现出显著的上下文前缀共享特征。研究人员可借此模拟真实智能体工作负载,精确测量缓存策略在避免重复计算、提升系统吞吐量方面的效能,尤其适用于检验如LMCache等分层缓存方案在长上下文迭代中的表现。
解决学术问题
该数据集主要应对智能体工作负载下高效推理系统的学术挑战。传统基准常忽略多轮对话中令牌前缀的高度重叠性,导致缓存利用率评估失真。本数据集通过提供严格前缀扩展的会话轨迹,使研究者能定量分析上下文增长模式与缓存命中率的关系,从而设计更优的缓存逐出与预载策略。其意义在于为KV缓存机制的研究建立了可复现的实验基础,推动了面向长上下文、低延迟推理的系统优化理论发展。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在高效缓存架构与调度策略的创新上。例如,LMCache项目利用其前缀增长模式设计了基于令牌相似度的分层缓存系统;Mooncake与vLLM等推理引擎则借鉴其会话时序特征,实现了支持细粒度前缀共享的注意力机制。此外,在学术层面,该数据集催生了多项关于智能体工作负载建模与缓存行为预测的研究,为动态上下文管理算法提供了实证分析基础。
以上内容由遇见数据集搜集并总结生成


